Apr 01, 2024
Raft + RocksDB 架构及其在 Apache Hugegraph 分布式存储中的运用
RAFT 加 RocksDB 已经逐渐成为分布式 KV 领域的一种普适性架构,通过整合 RAFT log 还有rocksdb 的 WAL 可以在一定程度上降低数据的写放大问题。目前该部署方式的应用场景也比较广泛,耳熟能详的比如 TiKV、NebulaGraph 还有美团的 Cellar,在部署方式的选择上主要是基于 share nothing 架构,其中 RocksDB 充当了 RAFT 状态机的角色。
Apache Hugegraph 今年也在构建分布式架构,其中 store 存储模块基于 Raft + RocksDB 向 Hugegraph Server 提供分布式存储服务,以达到存算分离的目的。
近期笔者在 Apache Hugegraph 社区做了一次相关分享,以下为脱敏后的内容。
知识背景
RocksDB
基本介绍
- RocksDB 是 Facebook 开发的一款高性能 C++ KV 存储引擎,底层基于 LSM Tree,其键值均允许使用二进制流。
- RocksJava 是为了给 RocksDB 构建一个高性能,但是易用的 java 驱动的工程, 它由 3 层构成:
- org.rocksdb 包里面的 Java 类,构成 RocksJava API。Java 用户只会直接接触到这一层。
- C++ 的 JNI 代码,提供 Java API 和 RocksDB 之间的链接。
- C++ 层的 RocksDB 本身,并且编译成了一个 native 库,被 JNI 层使用。
<dependency> |
- RocksJava 生成的文件
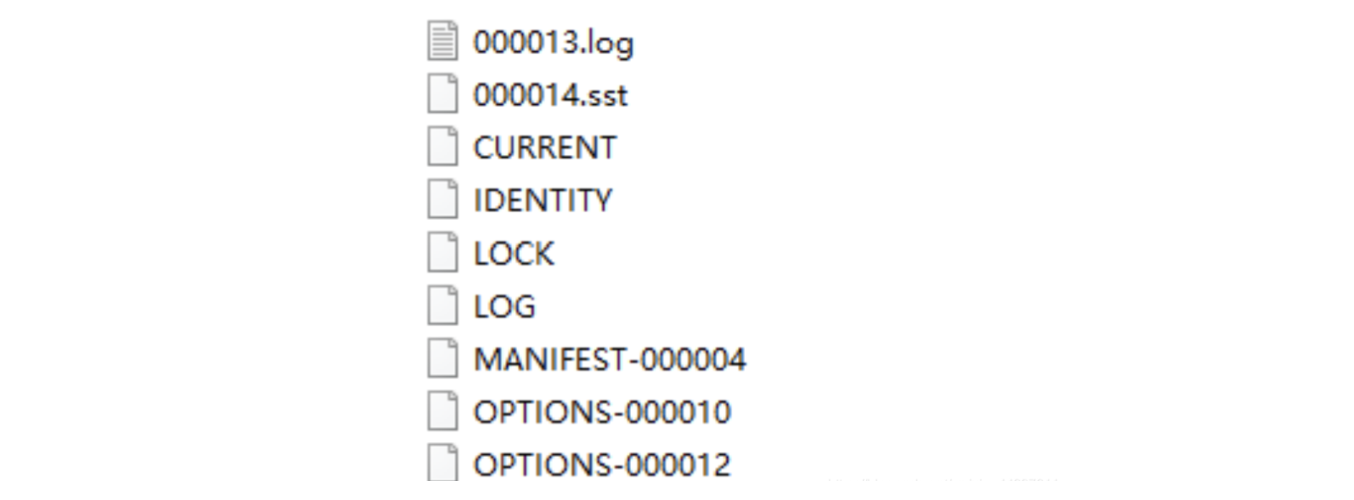
- xxx.log:(日志) WAL 文件
- xxx.sst:数据文件
- CURRENT:是一个特殊的文件,用于声明最新的manifest日志文件
- IDENTITY:id
- LOCK:无内容,open 时创建,表示一个 db 在一个进程中只能被 open 一次,多线程共用此实例
- LOG:(主)统计日志
- MANIFEST:指一个独立的日志文件,它包含 RocksDB 的状态快照/版本
- OPTIONS:配置信息
经典术语
理解经典定义不只是帮我们理解 LSM 的设计, 更是帮我们理解从内存 -> 磁盘, 从逻辑->物理视图上, 为何要引入这些概念, 更好的理解和传统 B-Tree 的区别
- Column Family(列族)
在 RocksDB 3.0,增加了 Column Families 的支持。可以简单理解为:CF 约等于我们熟悉的 Table
RocksDB 的每个键值对都与唯一一个列族(column family)结合。如果没有指定 Column Family,键值对将会结合到“default” 列族。RocksDB 在开启 WAL 的时候保证即使crash,列族的数据也能保持一致性。通过 WriteBatch API,还可以实现跨列族的原子操作。
列族提供了一种从逻辑上给数据库分片的方法。它的一些有趣的特性包括:
- 支持跨列族原子写。意味着你可以原子执行Write({cf1, key1, value1}, {cf2, key2, value2})。
- 跨列族的一致性视图。
- 允许对不同的列族进行不同的配置
- 即时添加/删除列族。两个操作都是非常快的。
简单的说,不同的列族是共享 WAL 的(从而保证跨列族原子写),但是 memtable 和 SSTable 是隔离的。
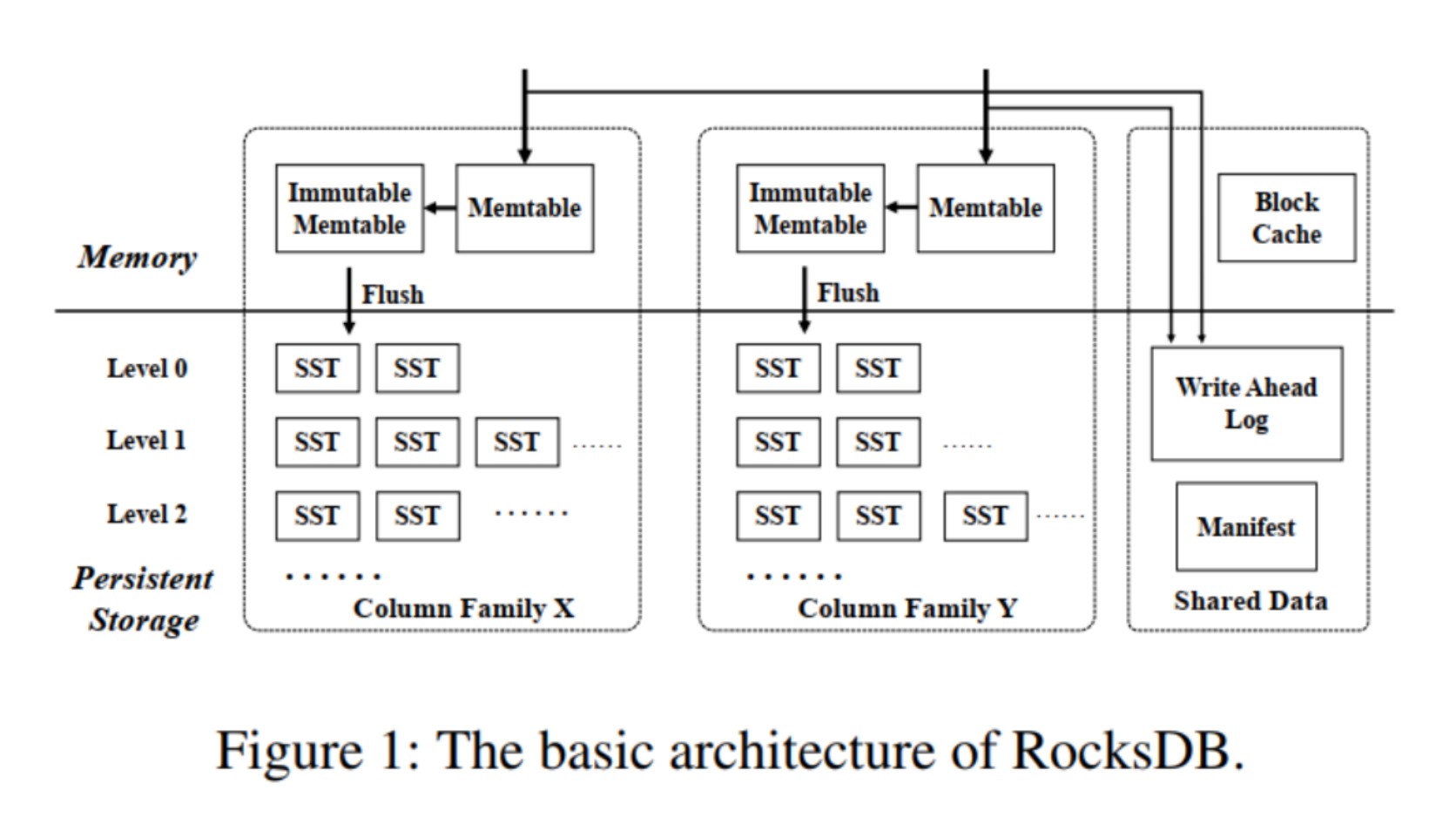
- Column (列)
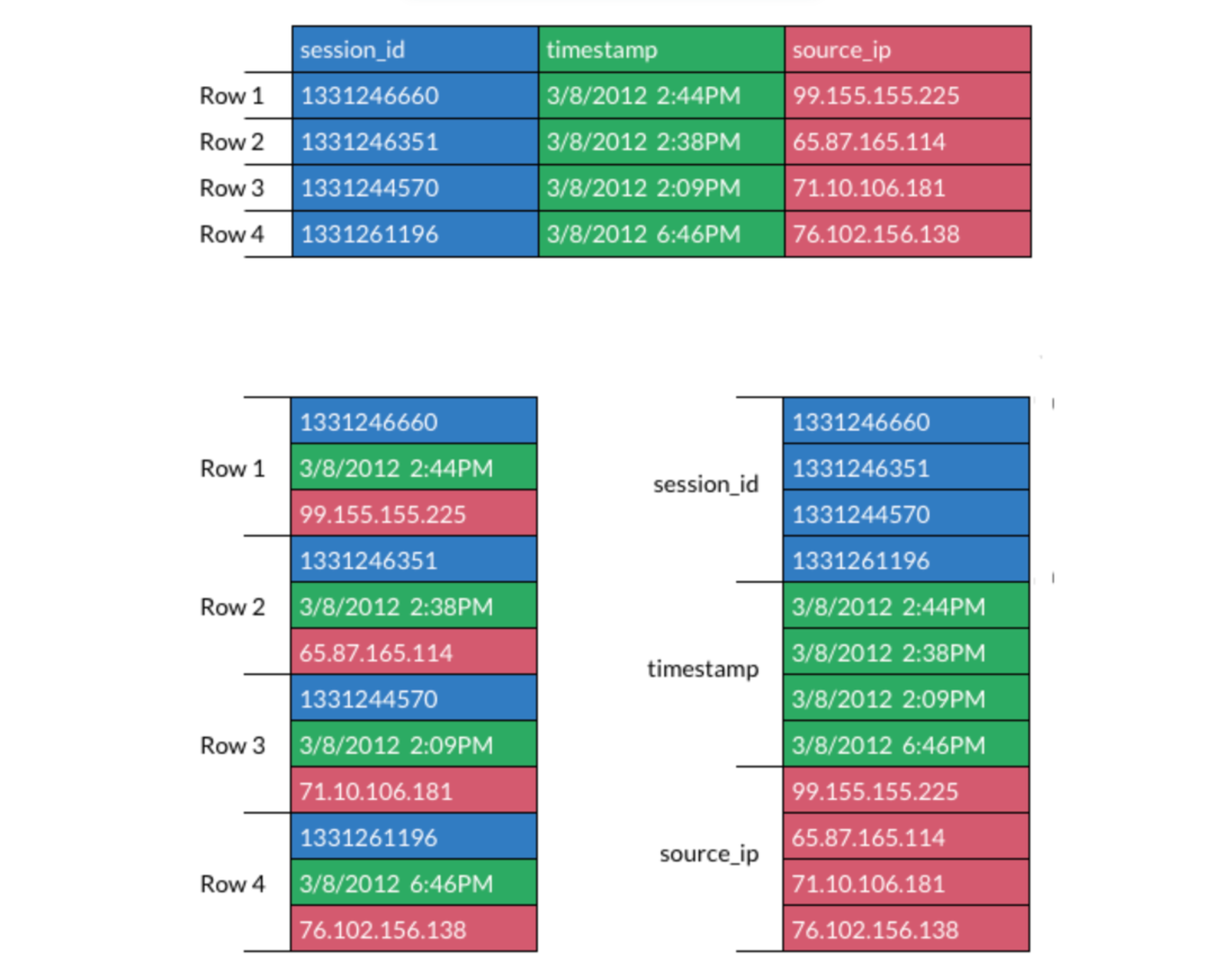
- 传统的「列存」和「行存」
- 行存(常用于 OLTP)对应左边,列存(常用于 OLAP)对应右边
- 以 Hbase 为例,虽然它的官网写着:HBase is a column-oriented database management system。但是 RocksDB/Hbase 其实不是上述的「列存」,以 Hbase 为例:
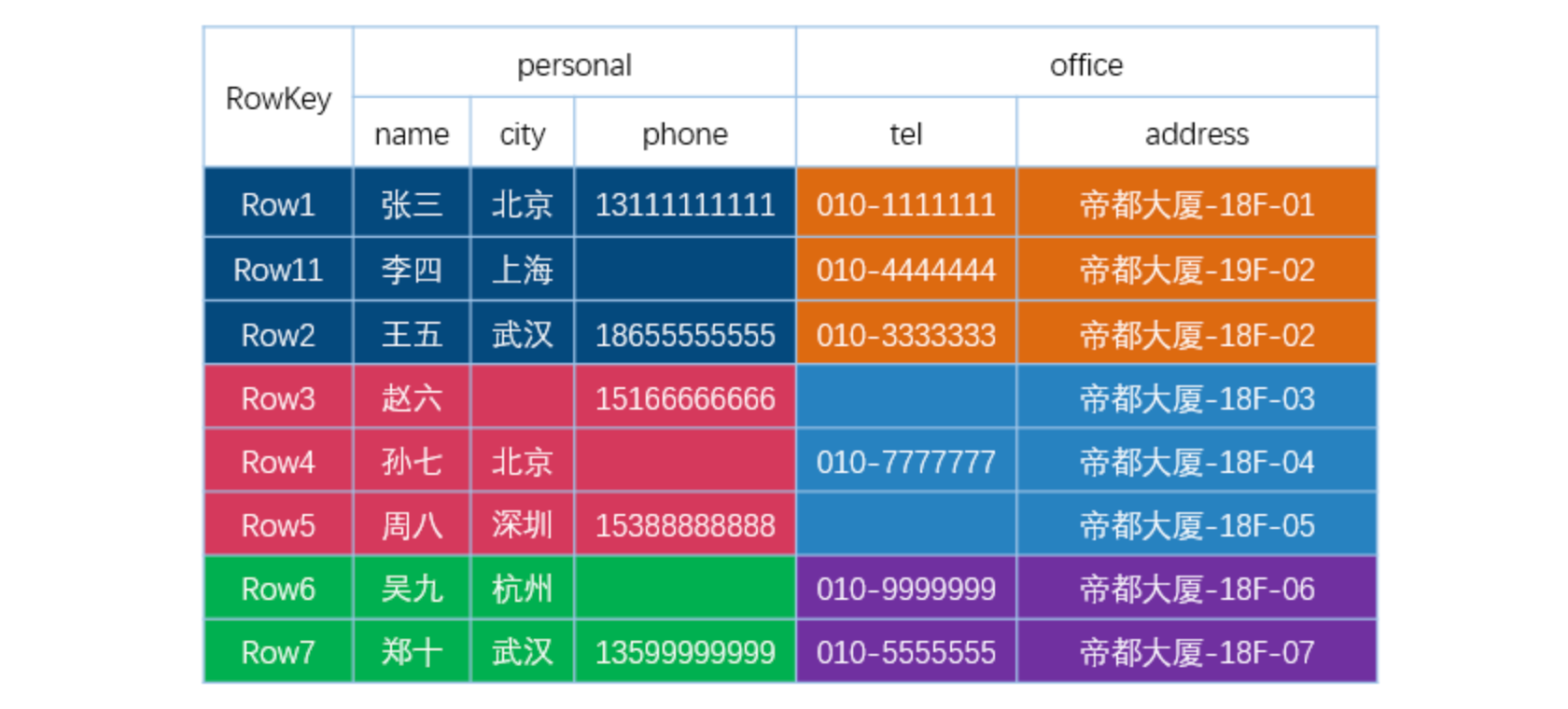
假如有这么一张 HBase 表,它的底层存储大概是这样的:
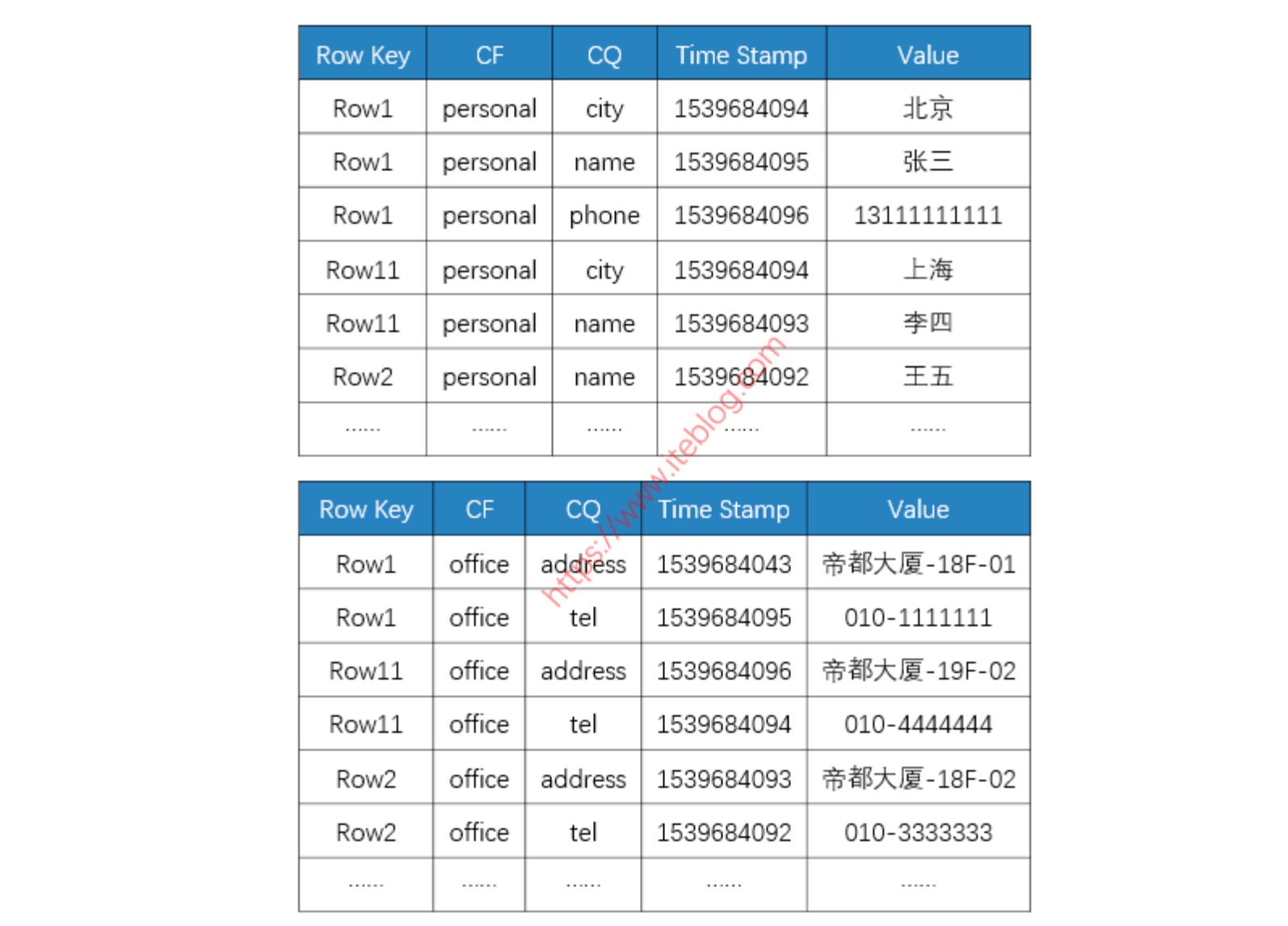
从上图可以看出:
- 不同的列族存在不同的文件中(上面两个表格代表不同的 HFile);
- 整个数据是按照 Rowkey 进行字典排序的;
- 每一列数据在底层 HFile 中是以 KV 形式存储的;
- 相同的一行数据中,如果列族也一样,那么这些数据是顺序放在一起的。
到这里大家应该可以看到,HBase 其实不是列式数据库,因为同一行数据,如果列族也一样,这些数据是存储在相邻位置的;这和上面的列式存储不太一样。所以说,HBase 既不像行式存储,又不像列式存储。它其实更像是面向列族的存储数据库,因为不同行相同的列族数据是相邻存储的;而同一行不同列族的数据是存储在不同位置的。
RocksDB 同理,我们可以直接看 RocksDB 底层的 SSTable 结构:(SSTable 的概念可以参考 ddia 第三章:https://vonng.gitbooks.io/ddia-cn/content/ch3.html)
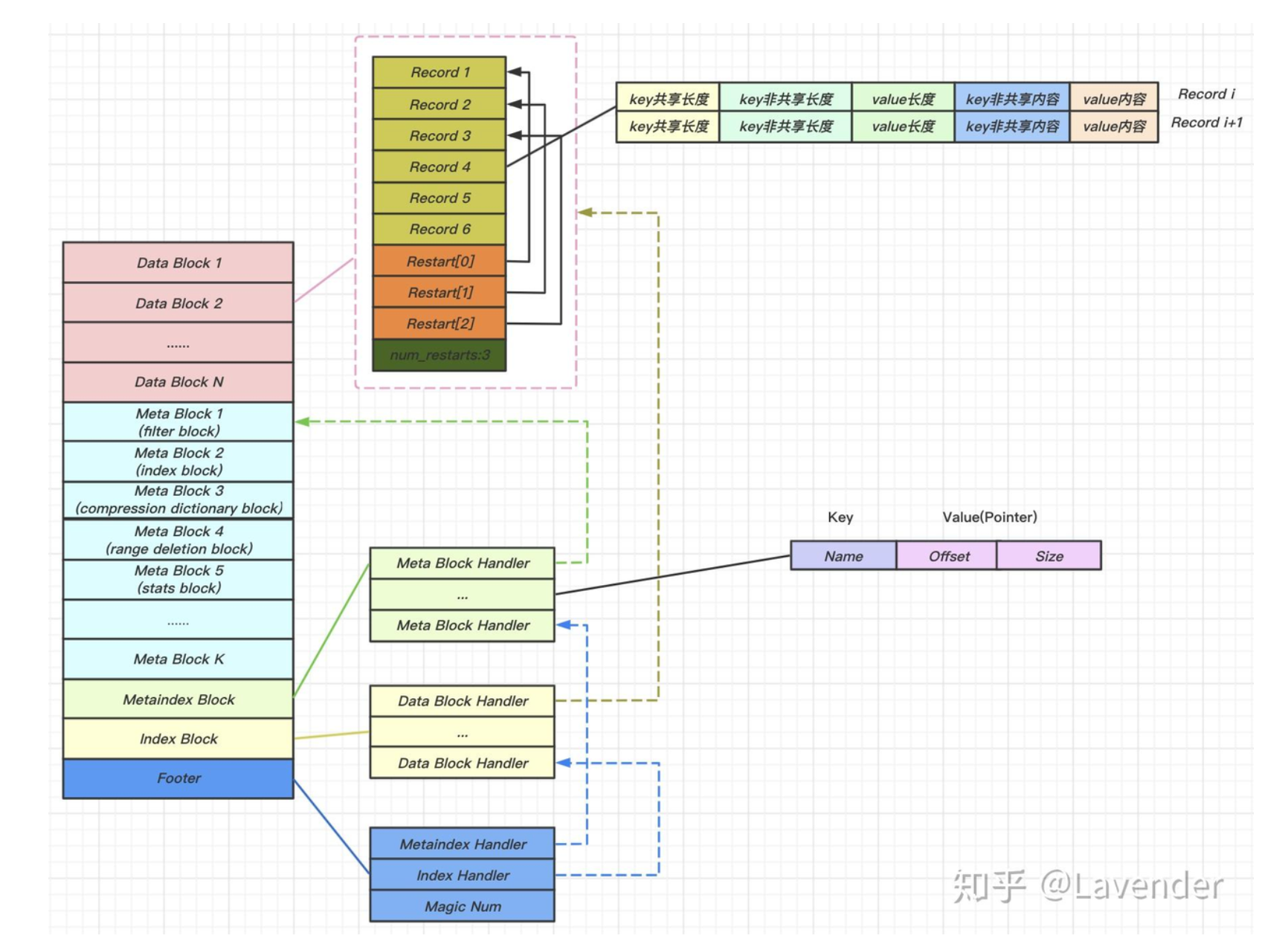
重点看一下 Data Block:data block 顺序存储 key/value,对于单个 block 会保存5个数值
struct Entry { |
- 第一部分 Entry 用来存储 key-value 数据。由于 sstable 中所有的 key-value 对都是严格按序存储的,用了节省存储空间,并不会为每一对 key-value 对都存储完整的 key 值,而是存储与上一个 key 非共享的部分,避免了 key 重复内容的存储。比如 “the car” 和 “the color” 相同的部分 “the“,为了节省空间,那么 key+1 开始,只记录key 不同的部分,例如:”olor”
- 一个Entry分为5部分内容:
- 与前一条记录 key 共享部分的长度,为 0 则表示该 Entry 是一个重启点;
- 与前一条记录 key 不共享部分的长度;
- value 长度;
- 与前一条记录 key 非共享的内容;
- value 内容
可以看出 RocksDB 也是以 key 为基准进行有序存储的 KV 引擎,至于「列族」概念,只是逻辑上的划分,并不意味着它们真的是列存数据库。
- Snapshot(快照)
一个快照会捕获在创建的时间点的 DB 的一致性视图。快照在 DB 重启之后将消失。
- Iterator(迭代器)
RocksDB 迭代器允许用户以一个排序好的顺序向后或者向前遍历 db。它还拥有查找 DB 中的一个特定 key 的功能,为此,迭代器需要以一个排序好的流来访问 DB。
- 而 RocksDB 数据库中的所有数据都是逻辑上排好序的。应用可以指定一种键值压缩算法来对键值排序。
如果 ReadOptions.snapshot 被给出,那么迭代器会从一个快照里面返回数据。如果这是一个nullptr,迭代器隐式创建一个迭代器创建的时间节点的快照。该隐式快照会通过固定资源来提供数据。隐式快照无法转换为显式快照。
- Compaction(压缩)&& flush
Compaction 是将一些 SST 文件合并成另外一些 SST 文件的后台任务。
Flush 是将 memtable 的数据写入 SST 文件的后台任务。
- 可以手动调用;compaction 是较重的操作,在某些负载较重的场景,会提前 compaction,减轻负载
- 比如业务低峰期,会集中 compaction
- 进阶:Remote compaction,存算分离
典型 API
键值对的数据都是按照二进制处理的。键值都没有长度的限制。
Put可以将一个键值对写入数据库。如果该键值已经存在于数据库内,之前的数据会被覆盖。WriteBatch可以将多个操作原子地写入数据库。- 比如 hg 中利用 writeBatch 的原子性,封装为
SessionOperatorImpl.commit
- 比如 hg 中利用 writeBatch 的原子性,封装为

Get允许应用从数据库里面提取一个键值对的数据。MultiGet允许应用一次从数据库获取一批数据。使用MultiGet获取的所有数据保证相互之间的一致性(版本相同)。IteratorAPI 允许对 database 做 RangeScan。Iterator 可以指定一个 key,然后应用程序就可以从这个 key 开始做扫描。Iterator API 还可以用来对数据库内已有的 key 生成一个预留的迭代器。一个在指定时间的一致性的数据库视图会在 Iterator 创建的时候被生成。所以,通过 Iterator 返回的所有键值都是来自一个一致的数据库视图的。SnapshotAPI 允许应用创建一个指定时间的数据库视图。Get,Iterator接口可以用于读取一个指定snapshot 数据。当然,Snapshot和Iterator都提供一个指定时间的数据库视图,但是他们的内部实现不同。Snapshot在数据库重启过程不能保持存在:reload RocksDB 会释放所有之前创建好的 snapshot。
有趣的事实
RocksDB 从使用层的角度来说,难点在于:open 时要传入的 option 对象可配置的太多了,就连 rocksdb 开发者都没有给出一个完美的调优方案,只是给出了一系列调优参考值,建议的是在不同的应用场景中通过压测来进行参数调优。github上的调优参考链接如下:https://github.com/facebook/rocksdb/wiki/RocksDB-Tuning-Guide
此图为上面链接的文档中最后一段,可见 rocksdb 调优是多么复杂的一件事。

Demo
此处进行了本地演示,大体为展示 multiGet、put、writeBatch 等 API
Raft/JRaft
详细了解 Raft 机制可以参考 Raft 论文
基本介绍
Raft 是一个强一致性的共识算法,用于分布式系统中保持副本间的一致性,核心是日志复制和 leader 选举。
Client 向复制状态机发送一系列能够在状态机上执行的命令,共识算法负责将这些命令以 Log 的形式复制给其他的状态机,这样不同的状态机只要按照完全一样的顺序来执行这些命令,就能得到一样的输出结果。
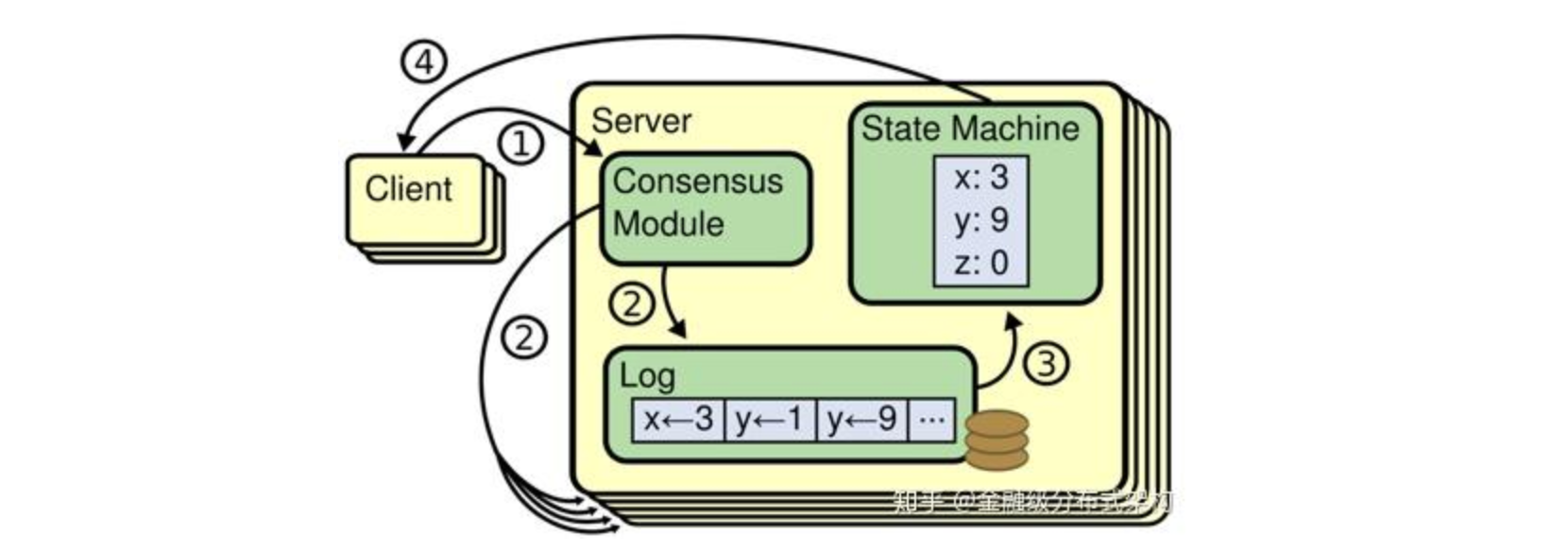
SOFA-JRaft 是一个基于 Raft 一致性算法的生产级高性能 Java 实现,支持 MULTI-RAFT-GROUP,适用于高负载低延迟的场景。 (也可以理解为一个 braft 的 Java 实现 - 见官方 README)
上述状态机模型应用到 JRaft,大致架构如下:
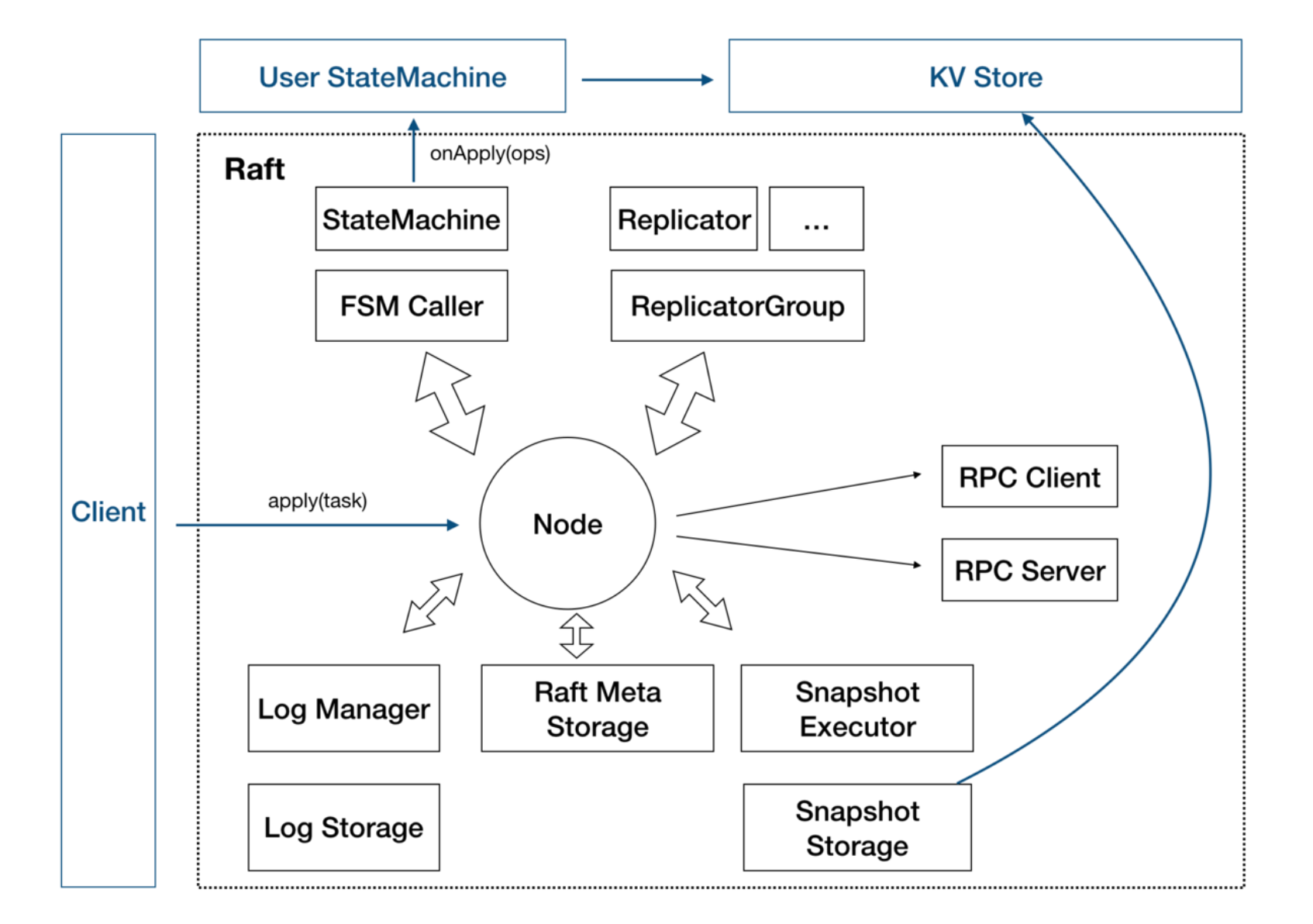
因为 Raft 中,通常选举或写入需要半数以上副本同意,所以 RaftGroup 只允许半数以下的副本故障,也就是说 5 副本允许 2 个故障,6 个副本也是允许 2 个故障,可见 5 个和 6 个节点的容灾能力是一样的,所以一般来说建议用户配置的副本数量为奇数。
而对于大部分生产环境,共识组一般就是 3 副本。因此上述架构图可拓展如下:
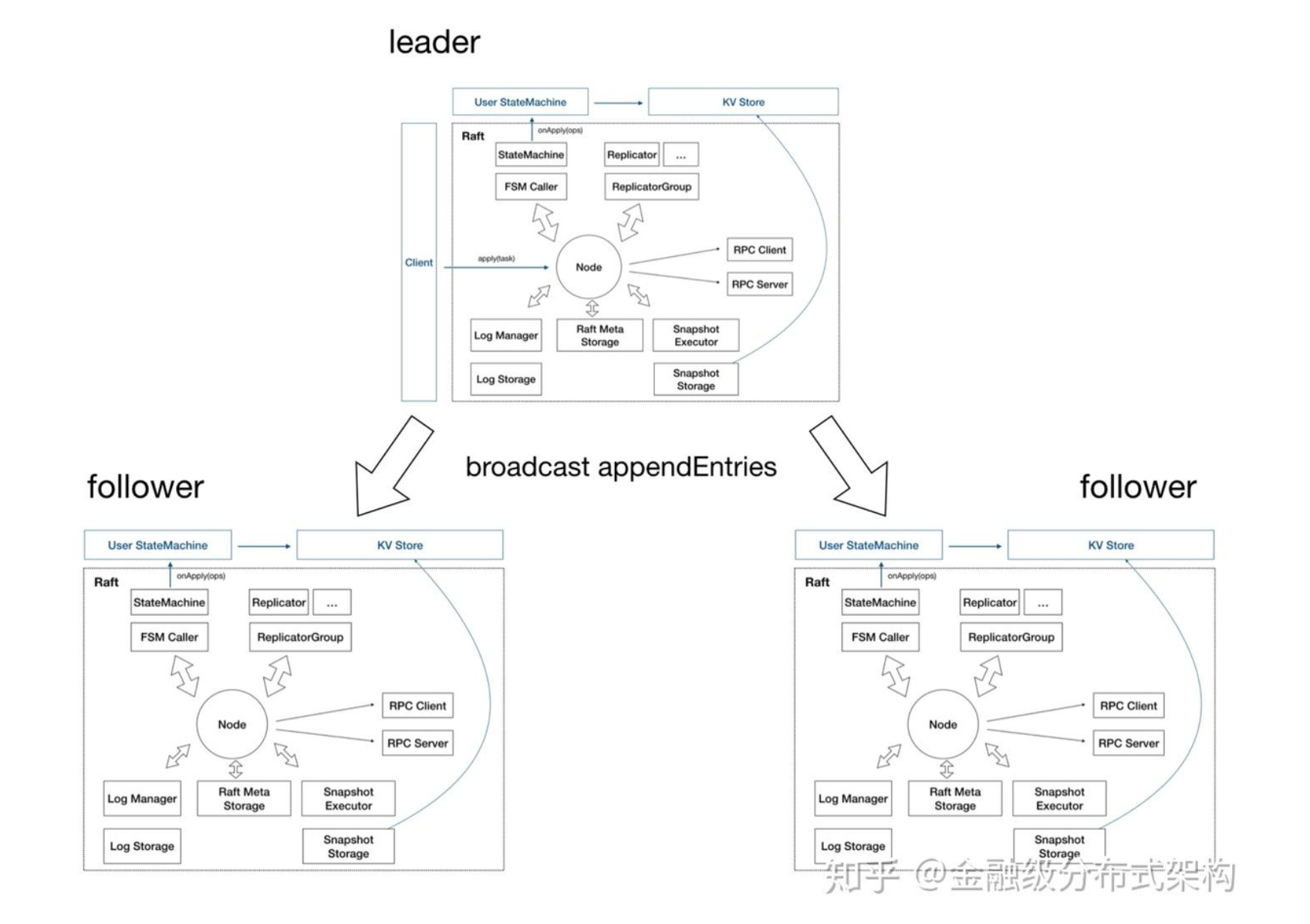
具体可以参考:https://zhuanlan.zhihu.com/p/59385865
Multi-Raft
这里引用 Cockroach ( MultiRaft 的先驱,出来的比 TiDB 早 )对 MultiRaft 的定义:
In CockroachDB, we use the Raft consensus algorithm to ensure that your data remains consistent even when machines fail. In most systems that use Raft, such as etcd and Consul, the entire system is one Raft consensus group. In CockroachDB, however, the data is divided into ranges, each with its own consensus group. This means that each node may be participating in hundreds of thousands of consensus groups. This presents some unique challenges, which we have addressed by introducing a layer on top of Raft that we call MultiRaft.
在 CockroachDB 中,我们使用 Raft 一致性算法来确保在机器发生故障时数据也能保持一致。在大多数使用 Raft 的系统中,如 etcd 和 Consul,整个系统只有一个 Raft 共识组。然而,在 CockroachDB 中,数据被分成不同的范围,每个范围都有自己的共识组。这意味着每个节点都可能参与成千上万个共识组。这就提出了一些独特的挑战,我们通过在 Raft 之上引入一层 MultiRaft 来解决这些问题。
简单来说,MultiRaft 是在整个系统中,把所管理的数据按照一定的方式切片,每一个切片的数据都有自己的副本,这些副本之间的数据使用 Raft 来保证数据的一致性,在全局来看整个系统中同时存在多个 Raft-Group,就像这个样子:
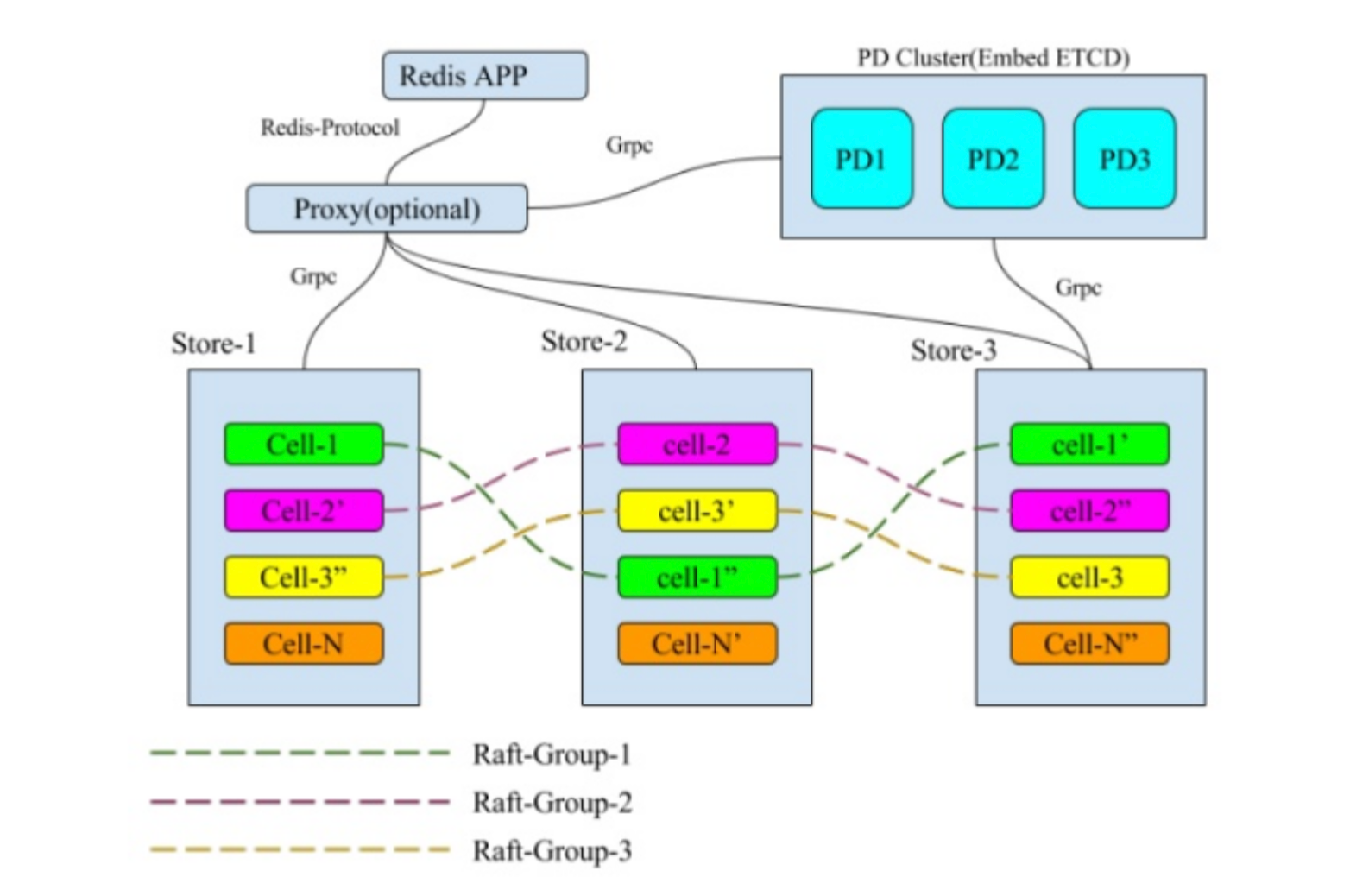
单个 Raft group 是无法解决大流量的读写瓶颈的,通过 Multi-Raft 来拓展读写性能是分布式系统的常见做法,JRaft 支持 Multi-Raft 架构,Hg 也采用了 Multi-Raft 架构。
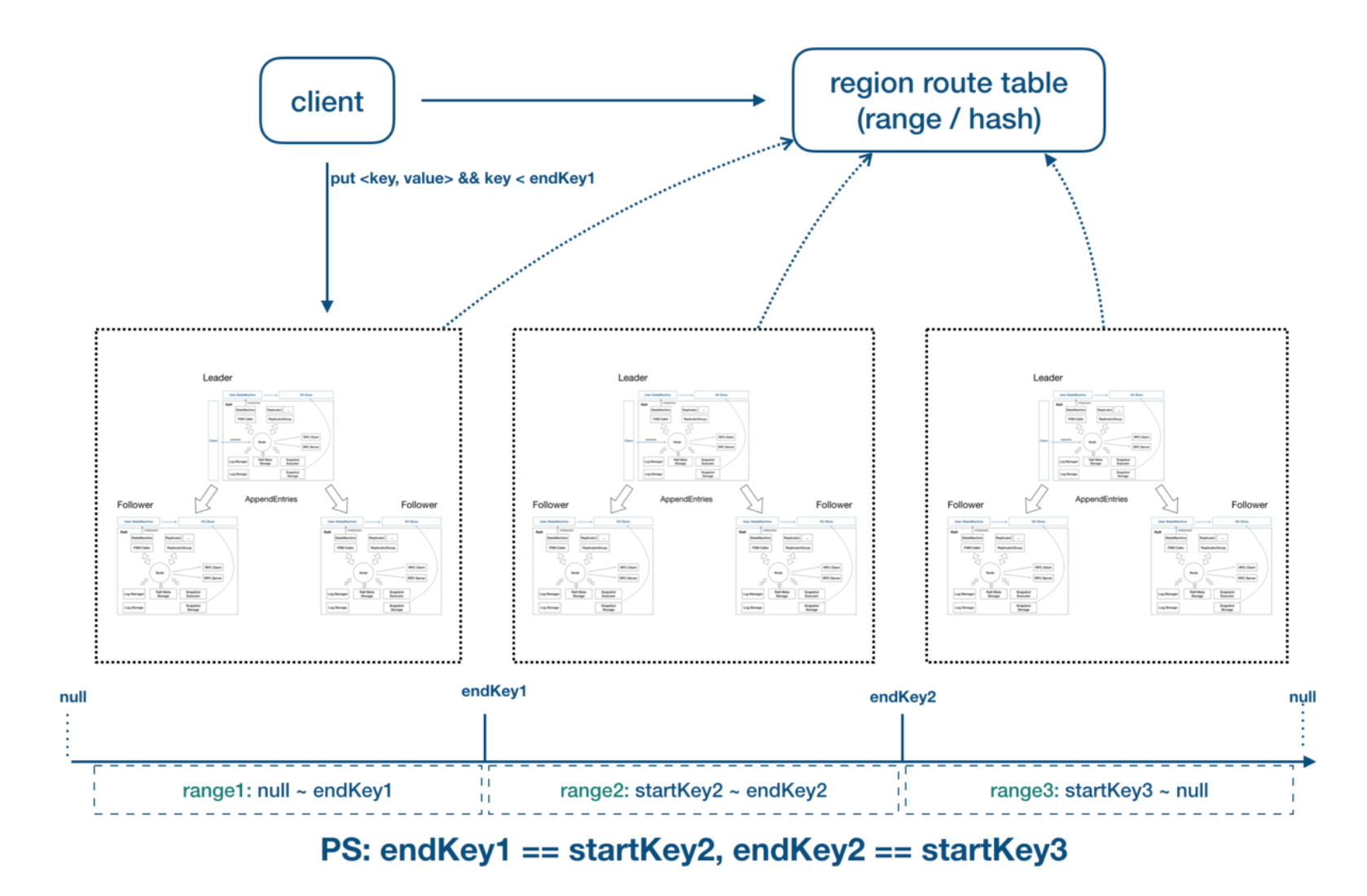
HG 分布式存储模型
从图中可以看到 RaftGroup 和 patition 是一一对应的,patition 是逻辑上的概念,是多个 PartGraph 的集合。
因为 RaftGroup 是横跨多个服务器节点的,每一个节点就是一个数据分片,也就是 shard,所以 partition 和 shard 是一对多的关系,partition 有几个副本就对应几个 shard。因为一台服务器会有多个 RaftGroup,也就是有多个 shard,而一个图实例对应的是一个 rocksdb 实例,所以 shard 和 store 是多对一的关系。
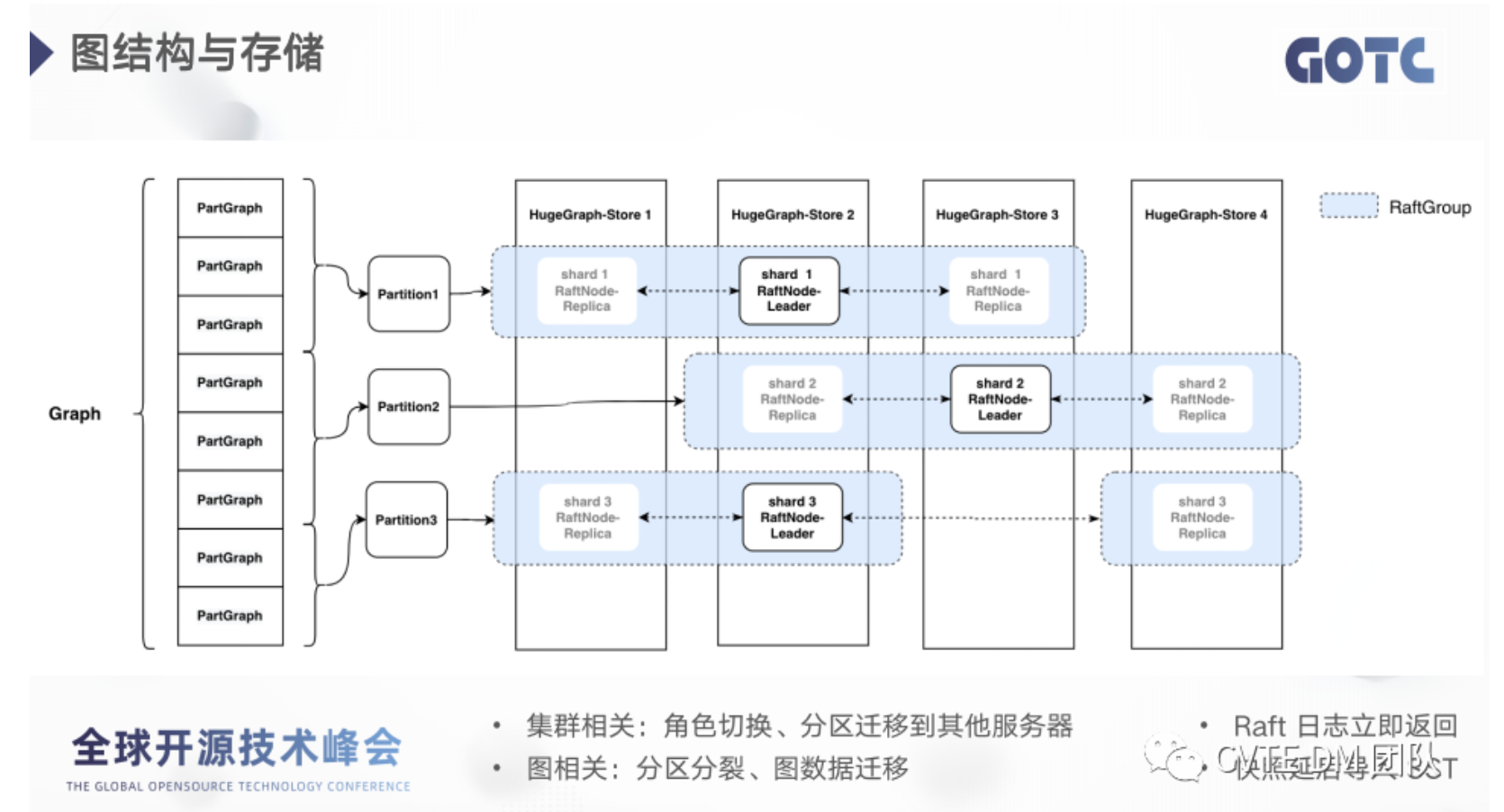
在代码里面:假设某个 store 实例有 n 个 shard,分别属于 n 个 RaftGroup
- 那么该 store 实例将持有 n 个 PartitionEngine(Map<String, PartitionEngine>)
- 每个 PartitionEngine 持有该 store 实例,对应 shard 的 RaftNode 引用,同时持有该 Partition 的所有 peer 信息
- 对应 JRaft 的 raftGroupService.start
具体分区哈希算法:详情参考 feat(hbase): support hash rowkey struct & pre-init tables (#1696) 035a03e1
Store 模块交互流程概览
- 集群整体架构:
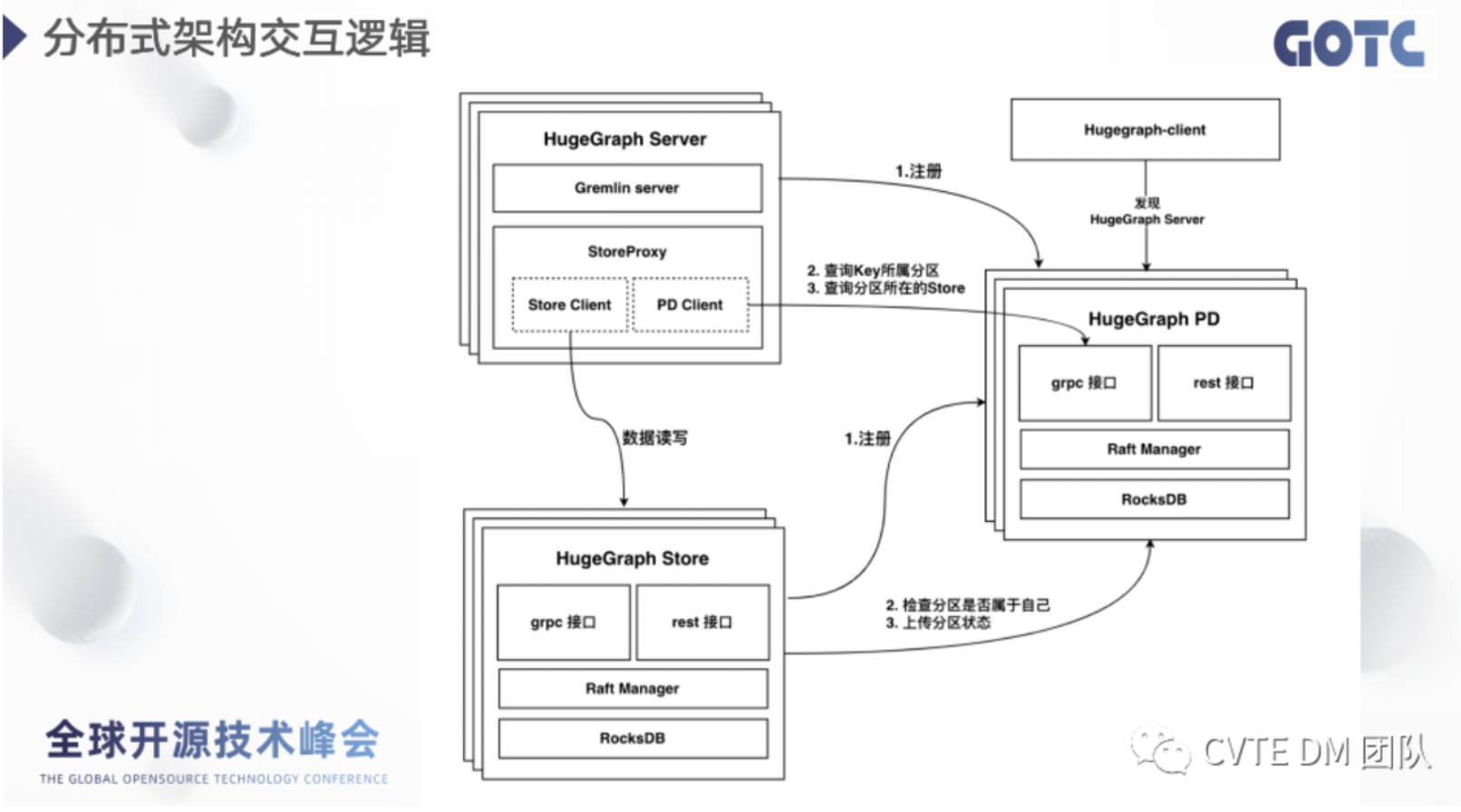
- Server 和 store 类似存算分离
- Store 内部的 request flow
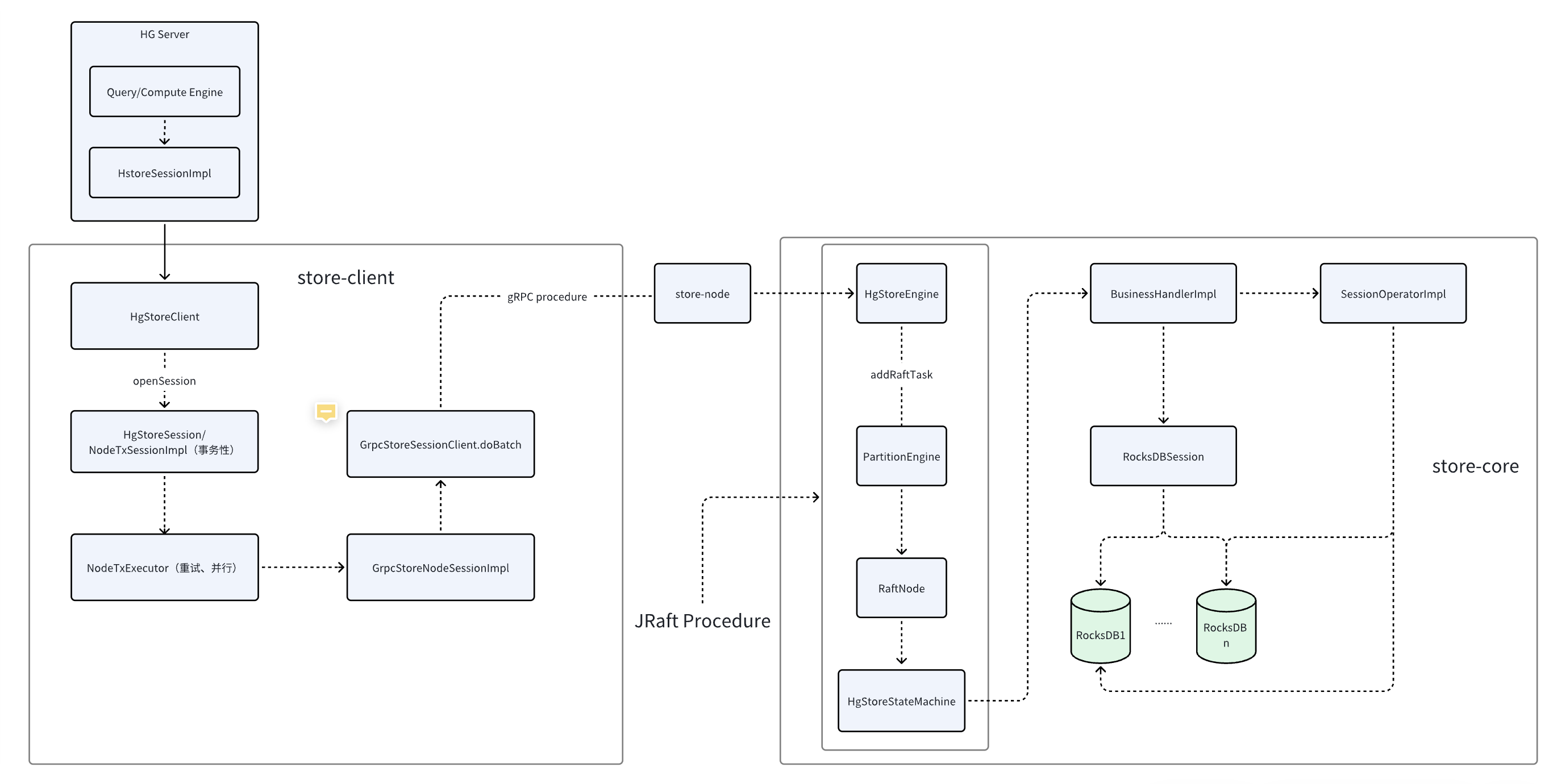
HG 在 RocksDB 的存储数据结构
某个 graph 在 RocksDB 的数据存在下列 table(CF-列族)中:
private static final ConcurrentHashMap<String, Integer> tables = new ConcurrentHashMap<>() {{ |
参考 org.apache.hugegraph.backend.serializer.BinarySerializer ,可以看出 HG 的边点等属性是如何序列化成 RocksDB 的 kv
以边为例:
- 以 partition_Id(基于 id hash 算出来的) + id 作为 key,以边/点的具体 lable、properties 作为 value
// 以边为例,写 kv 的方法 |
宏观设计
Iterator pattern
对于 pd-store 架构,Hg 采用各种 Iterator 来进行数据读取
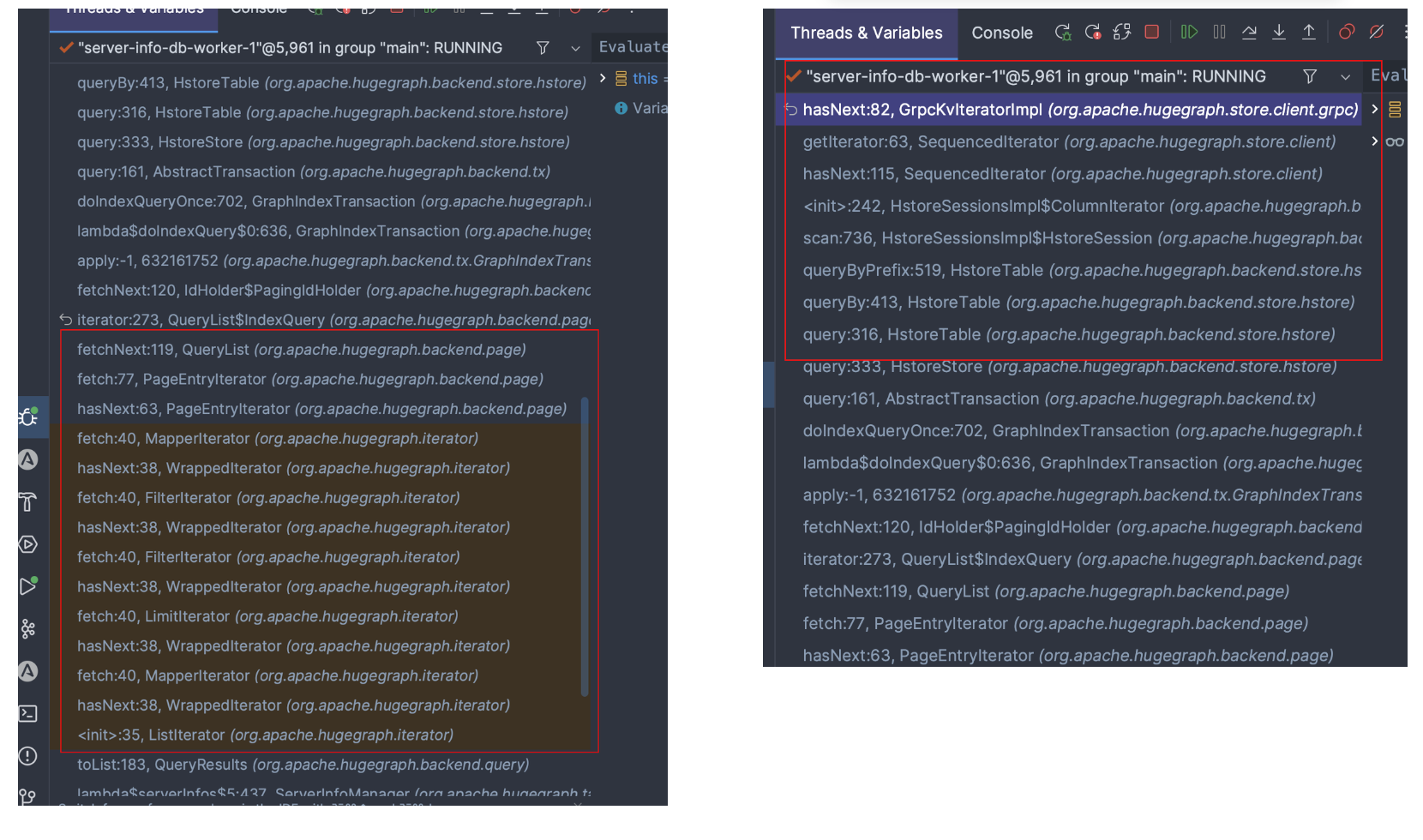
理解有两层原因:
- RocksDB 底层后端提供 Iterator 读方式,因此顺水推舟在整个架构中都用 Iterator
- 采用 Iterator wrap Iterator 的方式,层层调用,可以实现类似火山模型的效果 (向量化/批处理模型可算是它的优化版, 也是 HG 之后可在部分查询上改进的思路之一)
火山模型是数据库界已经很成熟的解释计算模型,该计算模型将关系代数中每一种操作抽象为一个 Operator,将整个 SQL 构建成一个 Operator 树,从根节点到叶子结点自上而下地递归调用 next() 函数。每个 next() 函数处理一个 tuple。
例如 SQL:
对应火山模型如下:
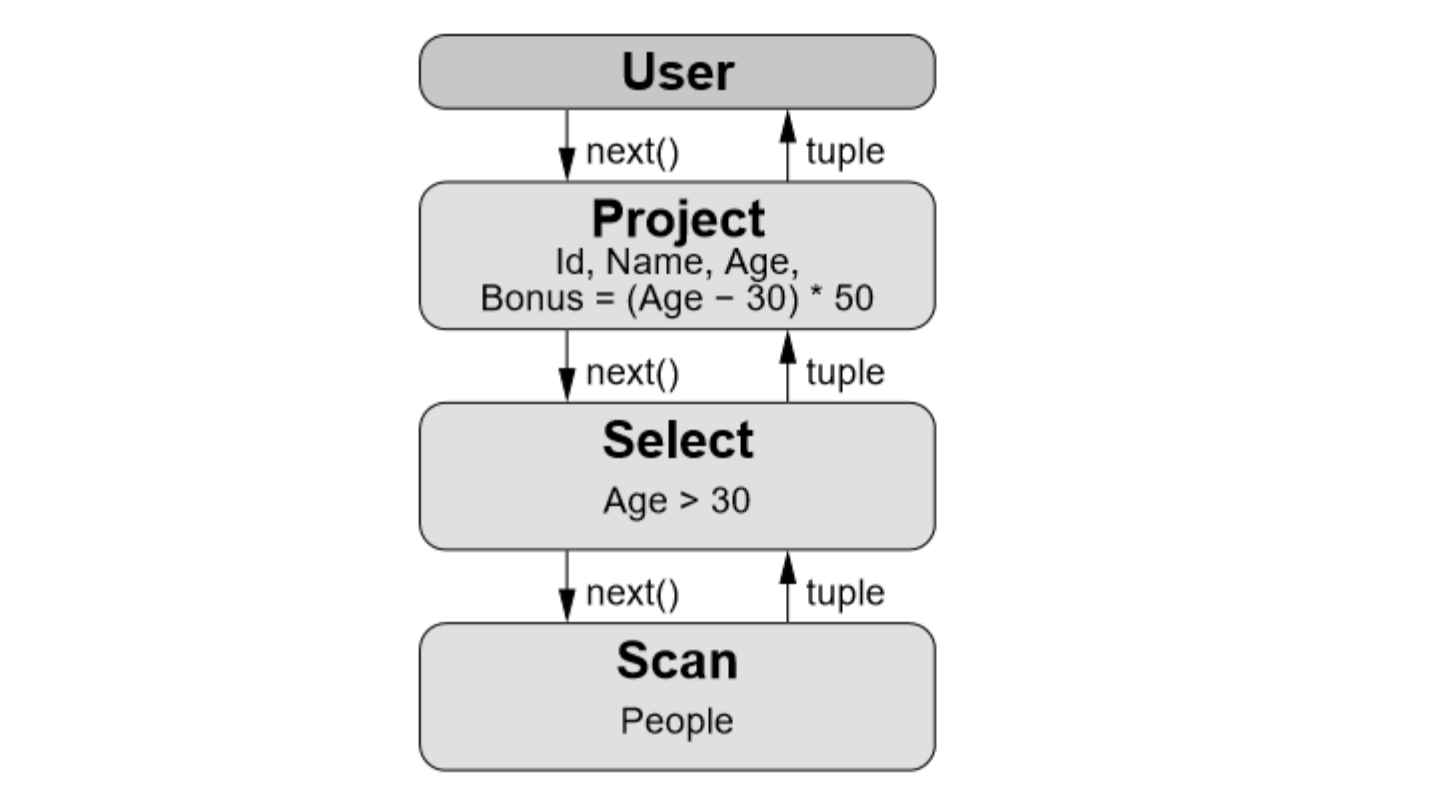
Listener
用于广播、执行类似 AOP 的逻辑,实现一些切面动作
- Store 的状态:当 store 上线时,进行启动动作
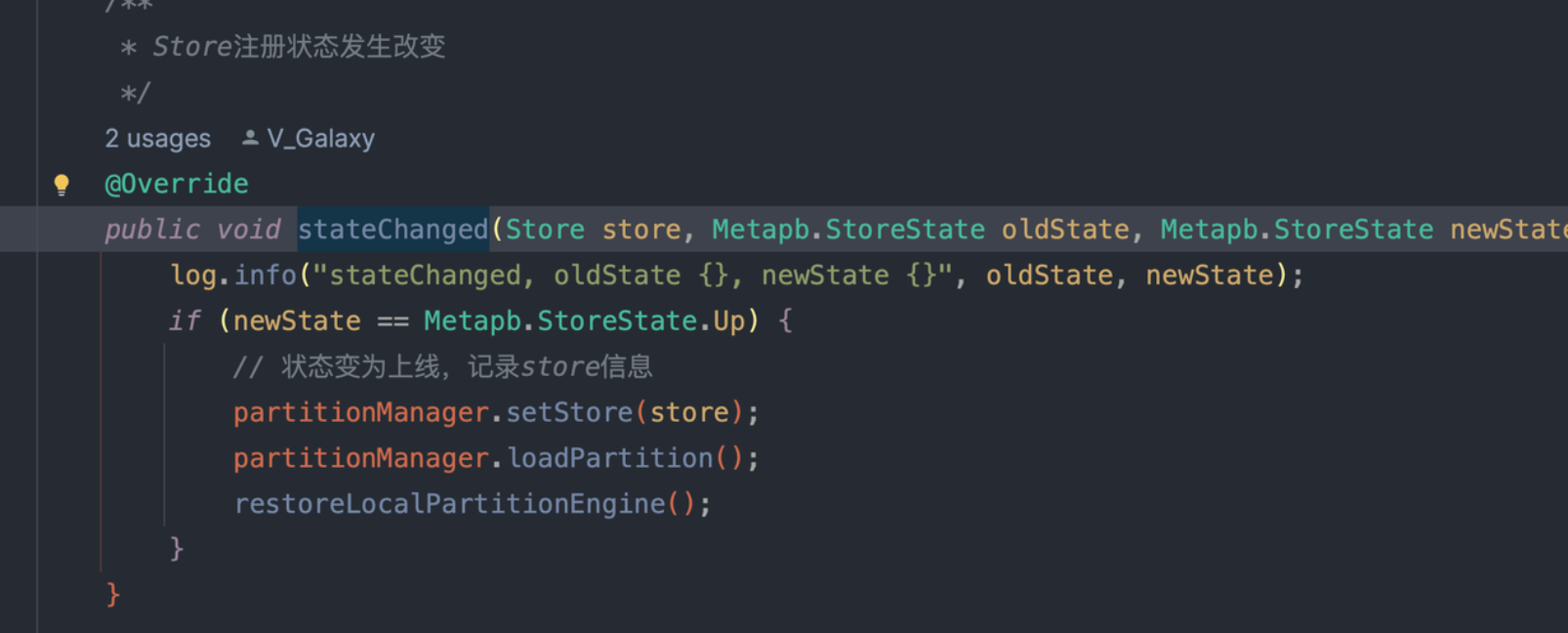
- RaftGroup 的状态
RaftStateListener:监听 RaftGroup 的 leader change 等信息
- Replicator(JRaft 用于复制日志的组件)的状态
ReplicatorStateListener:在状态改变时检查是否有 changeShard 任务
- RocksDB 的状态
RocksDBChangeListener:compaction 等动作
- Partition 的状态
PartitionChangedListener:用于在 change 的时候由 leader 通知其他 follower
Closure
类似闭包,实际用起来像 go defer 或 AOP,定义在结束某个活动时执行的动作
engine.addRaftTask(request.getGraphName(), request.getPartitionId(), |
需要注意的是:JRaft 还使用 closure 来标识是否是 leader
|
心跳保活(with TTL)
HgStoreEngine 中,store 实例会定期向 pd 发送心跳。
Store 的设计中,处处可见状态机思想:store 实例被设定为了四种状态,根据不同的状态,心跳会有不同的动作
- Unknown
- Offline
- 重新向 pd 注册,先拿 id,如果集群 ready,注册之,然后监听 partition 的消息(重启)
- Online
- 与 pd 心跳,更新 storeInfo
- 根据拿到的 cluster 信息,检查 cluster 是否异常(保活)
- Tombstone(死亡)
- 什么也不做
高可用
- 分布式架构原生保证一定的容错
- store 定期与 pd 心跳,同步元信息(伴有 TTL 保活),而 Pd 利用 RocksDB 将元信息持久化,保证了重启恢复。
- store 实例之间的副本同步过程,借助 JRaft 组件保证了重启恢复。
- store 的 meta info(无论是 pd 还是 store)都借助 RocksDB 进行持久化,防止节点宕机信息丢失(存储在专门的图 hgstore-metadata 下)
高性能
- 并发执行:不多赘述
- 异步任务:如 AsyncRPC
- 上下文用 Byte 对象传输,减少序列化开销:如 RaftOperation
Ref
- https://blog.csdn.net/weixin_44607611/article/details/113742388
- https://cloud.tencent.com/developer/article/1785028
- https://blog.csdn.net/penriver/article/details/117559188
- https://wanghenshui.github.io/rocksdb-doc-cn/
- https://github.com/facebook/rocksdb/blob/master/java/samples/src/main/java/RocksDBSample.java
- https://zhuanlan.zhihu.com/p/165399524
- https://zhuanlan.zhihu.com/p/340949657
- https://zhuanlan.zhihu.com/p/145551967
- https://zhuanlan.zhihu.com/p/59385865
- https://zhuanlan.zhihu.com/p/61185934
- https://zhuanlan.zhihu.com/p/478705155