Mar 15, 2024
记一次由偏向锁引起的性能下降
近期,笔者为 Apache IoTDB 新增了 JVM 的若干优化 options,其中一条是 -XX:-UseBiasedLock 关闭偏向锁(因为偏向锁如今作用有限,JDK15 开始默认废弃;而取消偏向锁时会造成 safepoint 等待的 stw 开销)。然而,合入 pr 后发现若干场景发生了性能下降。
由于偏向锁是过时且有开销的机制,因此将其关闭后,反而是负优化有点反直觉。第一次遇到这类问题,排查和解决下来都挺有意思的。
偏向锁简介可以参考:https://juejin.cn/post/6994404508344270878
问题背景
合入 https://github.com/apache/iotdb/pull/12088/files 后
- 合并导出场景耗时增加
- 写入 1C1D、3C3D 场景无变化,3C5D 耗时增加
排查过程
首先和社区同学讨论问题范围:
初步思考
感觉会影响查询和合并吞吐的,可能是 -XX:SafepointTimeoutDelay=1000 -XX:+SafepointTimeout。这两个参数会在某个线程 Safepoint 超时时,将相关信息打印到标准输出里。可能是在某个时刻 Safepoint 超时的线程太多了,导致标准输出变多,影响了吞吐。
验证结果:注释掉上述参数,验证发现还是耗时高,说明罪魁祸首不是它们
补充验证:还把 IoTDB 启动脚本完全替换回了 pr 修改之前的版本,发现无耗时异常,说明罪魁祸首在 pr 里
再次思考
pr 剩下涉及到的修改只有:
- safepoint 相关优化:有点黑盒,可能造成耗时增加
- 取消偏向锁:偏向锁理论上已经过时, 取消它并无太多不妥,大多数场景多害少益,且有其他高性能锁作为替代,这也是 JDK15 不支持偏向锁的原因。但是由于它较为黑盒,理论上仍有可能造成耗时增加。
- 线程内存从 1M -> 512K:不会对性能有影响,除非 OOM
- GC 开启自适应:不会对性能有那么大的影响,且大部分场景是正优化
再次验证:注释掉 safepoint 所有优化,并打开了 safepoint 日志,发现问题仍然存在。
而且 safepoint 日志显示:safepoint 耗时很少,平均毫秒级,总共 safepoint 耗时才 1s,且 GC 耗时也很少。因此应该不是 safepoint 和 GC 导致的问题。
发现问题
联想到社区之前测试机器升级到 JDK17 后,也发生了类似的性能下降(当时笔者从 CPU、GC、内存 等角度,使用火焰图、JMH 等手段都没排查出来是哪里的问题),发现当时的耗时就跟本次开源版高耗时的情况差不多
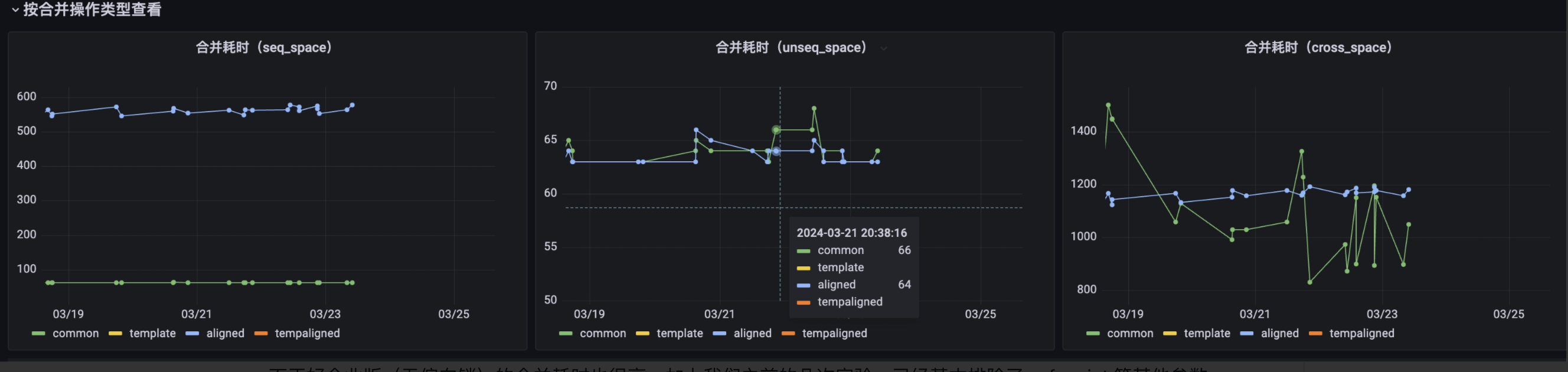
联想到本次 PR 内容之一是手动取消偏向锁 -XX:-UseBiasedLock(这里有一个背景是 JDK8、11 有偏向锁,JDK17 无偏向锁)
而正好之前 JDK17 (无偏向锁)的合并耗时也很高,加上之前的几次实验,已经基本排除了 safepoint 等其他参数的影响,只剩下偏向锁取消和线程内存调整没有验证了,而线程内存调整应该不会影响性能,最多只会 OOM。
因此推测是偏向锁取消导致的这次问题,但是偏向锁理论上已经过时,大多数场景多害少益,且有其他锁作为替代,这也是 JDK17 不支持偏向锁的原因。
验证结果:注释掉 -XX:-UseBiasedLock 后,耗时下降,问题消失。说明本次耗时增加是由于取消了偏向锁
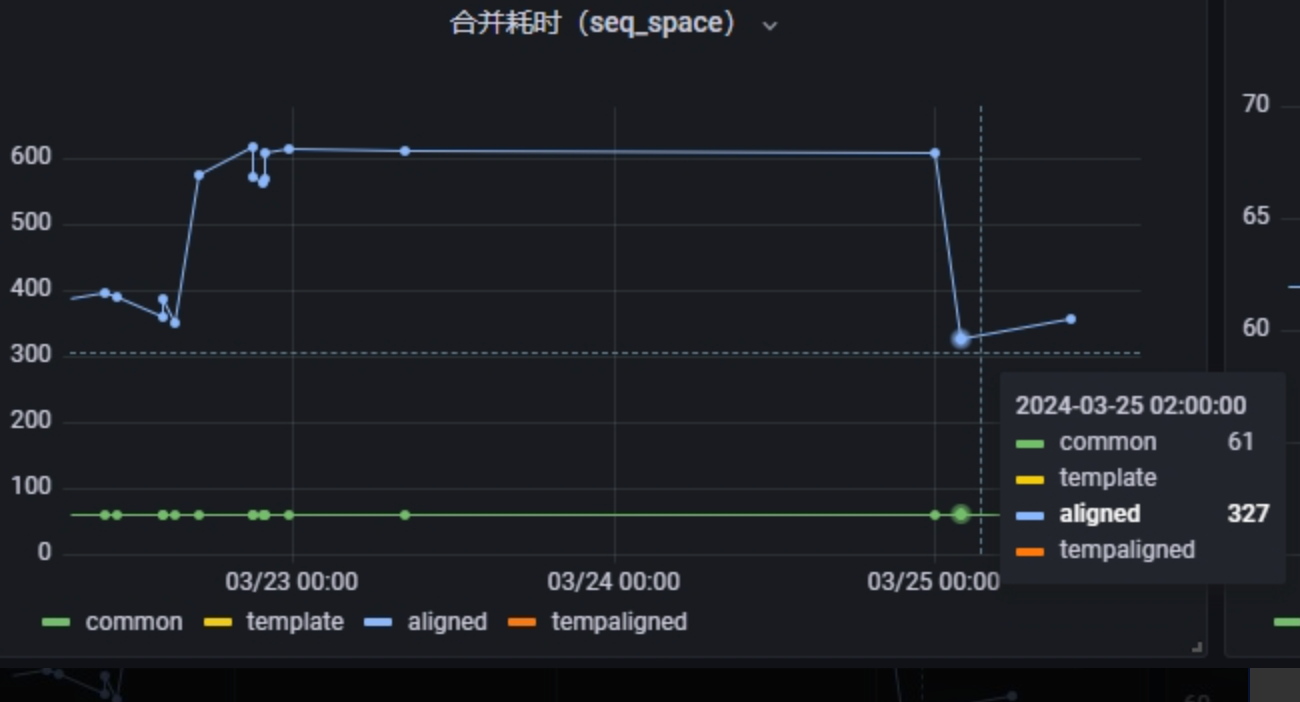
实锤了偏向锁的影响后,笔者还在之前 JDK 升级的测试环境进行验证:
验证结果:在 JDK17 的环境,手动添加偏向锁 -XX:+UseBiasedLock 后,耗时下降,问题消失。说明当时 JDK 升级后性能下降是由于 JDK17 默认废弃了偏向锁
问题根因
引入了 -XX:-UseBiasedLock 取消偏向锁,导致某些场景性能下降。
根据 openjdk 团队的 note,按理说 biased lock 如今已经是多害少益,且有更完善的锁机制进行替代,也因此 JDK 15 之后,biased lock 就默认关闭了。
然而在合并等场景,关闭偏向锁后观测到性能下降。
可能是由于如下场景较多:某线程长期持有某临界区资源,反复获取锁、释放锁,且临界区资源的锁竞争较少,导致偏向锁不太需要被取消。
因此偏向锁带来少 access 锁的收益大于了取消偏向锁 stw 的开销,总体上是正优化。相反,如果取消偏向锁,线程反复 access 锁的开销较大,带来耗时增加。
社区负责 compaction 的同学后续通过查看代码验证,也找到了代码根因:
compaction 依赖底层 ByteArrayOutputStream 的读写接口,而 BAOS 的读写接口都是 Synchronized 修饰的同步方法。导致大量级的 Synchronized 拿锁放锁,进而放大了偏向锁的影响。
解决方案
虽然 openjdk 声明了偏向锁的弊端,并在 jdk15 废弃之,但根据 IoTDB 的实践,取消偏向锁反而会带来负优化。
由此看来,openjdk 的观点并不能奉为圭臬。真正废弃偏向锁的原因可能不是偏向锁性能差,可能是难以维护 || 机制复杂 || 行为难以预测等等。
根据社区老师的指导和建议,软件要尽量控制不可控的因素。既然高版本 JDK 已经移除了偏向锁,那我们就不推荐使用(尽管偏向锁能在 IoTDB 的某些场景有一些优化 );对于低版本 JDK 默认使用偏向锁,我们也不会手动 disable
因此,我们将移除对偏向锁的默认禁用(-XX:-UseBiasedLock),对于 JDK15 以上已经默认 disable 偏向锁的高版本 JDK,我们也不会显式使用偏向锁。因为 JDK 未来可能完全废弃偏向锁,从维护软件稳定性的角度来说,我们只能去适应。
额外思考
看八股好像记得 ReentrantLock 的性能比 Synchronized 好,思考:在高版本 JDK(默认关闭偏向锁),ReentrantLock 是否可以作为 Synchronized 的替代。
ReentrantLock 和 Synchronized 的性能比较,使用 JMH 进行基准测试
- 测试代码
|
- 结果:JDK 1.8 M2 pro 带偏向锁
Benchmark Mode Cnt Score Error Units |
- 结果:JDK 1.8 M2 pro 不带偏向锁
Benchmark Mode Cnt Score Error Units |
结论: 在单线程不断重入,无锁竞争的情况下,Synchronized 无论是否开启偏向锁性能都优于 ReentrantLock。看来八股也不是准的 23333
后续有时间考虑详细学习一下各类锁的实现,并用 Benchmark 测试性能