Jul 14, 2023
论文阅读-Zero-Change Object Transmission (ZCOT)
Zero-Change Object Transmission for Distributed Big Data Analytics
本文主要提出了一种零改变(Zero-Change)的跨 JVM 分布式数据传输方法,提高数据交换性能。
1. Abstract
分布式大数据分析严重依赖于Java和Scala等高级语言的可靠性和多功能性。
然而,这些高级语言也为数据交换制造了障碍。要跨托管运行时(如Java虚拟机(jvm))传输数据,对象应该由发送方(序列化)转换为字节数组,并由接收方(反序列化)转换回对象。对象序列化和反序列化(OSD)阶段引入了相当大的性能开销。先前的工作主要集中在OSD的某些阶段的优化,因此对象转换仍然是不可避免的。此外,它们需要额外的编程工作来与现有的应用程序集成,并且它们的转换还会导致重复的对象传输。这项工作提出了零改变对象传输(Zero-Change Object Transmission, ZCOT),其中对象直接在jvm之间复制而不需要任何转换。ZCOT可以在现有的应用程序中使用,而且它基于对象的传输可以用于重复数据删除。对最先进的数据分析框架的评估表明,ZCOT可以大大提高数据交换的性能,从而使应用程序性能提高23.6%。
2. Introduction
像Java和Scala这样的高级语言在大数据分析等领域受到欢迎,这要归功于它们可靠且通用的托管运行时环境。然而,托管运行时提供的抽象也会带来性能开销,特别是对于数据交换。由于像Java虚拟机(jvm)这样的托管运行时以不透明的基于对象的格式存储数据,因此它们必须在交换之前将对象转换为可解释的二进制流。
转换包含两个阶段:序列化阶段将对象转换为字节数组,反序列化阶段将字节数组转换回对象。对象序列化/反序列化(OSD)机制引入了相当大的转换开销,并已成为分布式对象传输的重要性能瓶颈,特别是对于需要通过网络进行大规模数据交换的应用程序
先前的工作已经认识到OSD的性能问题,并提出了不同的方法,包括软件[26,38,39]和硬件[16,32,40,46],以减轻其影响。
然而,这些方法主要集中在OSD的特定阶段的优化,数据转换仍然是不可避免的。此外,尽管它们可以提高OSD的性能,但它们中的许多都需要额外的编程工作来注释序列化点或更改原始的jvm间通信模型。last but not least,它们将传输的数据视为单个字节数组而不是单个对象,这使得难以识别重复传输并错过优化机会。
这项工作的目的不是优化OSD,而是直接消除整个OSD过程。为此,这项工作提出了零改变对象传输(Zero-Change Object Transmission, ZCOT),它提供了一种理想的数据交换机制,通过直接对象复制在jvm之间传输对象。(provides an ideal data exchange mechanism where objects are transferred among JVMs through direct object copying.)当JVM从其他对象接收对象时,它可以直接处理它们而不需要任何修改(Zero-Change)。ZCOT消除了对对象转换的需求,从而提高了数据交换的性能。
挑战难点及解决方案概述:
- 每个JVM都以特定于进程的不透明格式管理对象(each JVM manages objects in a process-specific and opaque format.)
- ZCOT首先引入了一个名为交换空间(exchange space)的全局共享抽象,交换空间是分布式环境中多个jvm可访问的Java堆空间的一部分。ZCOT进一步采用了**分布式类数据共享(DCDS)**机制,该机制提供了统一的对象格式,使交换空间中的对象对所有jvm都是可解释的。
- 与传统的基于osd的应用程序保持兼容
- ZCOT提出了一种两级传输机制(two-level transmission mechanism),以弥合基于对象的复制和传统的基于字节的传输之间的差距
- 相应的,由于提出了全局共享空间,ZCOT 还引入了元数据服务器,此时需要减少元数据服务器和 jvm 之间的流量
- ZCOT引入了全局共享交换空间,它负责管理多个jvm之间共享的对象。通过引入元数据服务器(metadata server),ZCOT可以memorizes 对象的存储位置,并帮助构建jvm之间的数据传输通道(data transmission channels)。由于大数据分析中的对象通常作为一个完整的数据集进行交换,ZCOT支持基于组的对象管理(group-based object management),它将对象分组组织,并大大减少元数据服务器和jvm之间的流量。此外,ZCOT还集成了在单个jvm中触发的垃圾收集(GC),并减少了GC暂停时间。
ZCOT在传输过程中发送对象而不是字节数组,这使得它具有对象意识(object-conscious),并且更容易识别重复的对象。因此,本文提出了一种重复数据删除机制,进一步优化数据传输。
- ZCOT中的重复数据删除模块利用交换空间抽象来记忆已经发送的对象,避免以后传输不必要的对象。然而,重复数据删除可能会在不同的数据集之间引入引用(或依赖关系)。
- 为此,ZCOT扩展了其分布式内存管理模块,以考虑组间依赖关系。
2.1 contribution
- 一个名为交换空间的分布式共享抽象,支持jvm之间的零更改对象传输,同时保持与传统的基于osd的应用程序的兼容性。
- 一种在全局共享空间上的内存管理机制,同时与各 JVM 的 GC 集成
- A data deduplication module,识别和删除不必要的数据传输来提升性能
- 在通信密集型工作负载上的实验表明ZCOT比现有OSD库的性能有所提高。
3. Background
3.1 OSD
语言运行时为独立于平台的代码执行提供了高级抽象。至于用户对象,运行时以不透明的格式存储它们,这种格式将对象数据与相应的元数据(类型信息、同步、内存管理等)一起维护。以Java为例,jvm为每个对象维护一个头来存储其元数据
但是,当需要在jvm之间进行数据交换时,对象必须超出运行时范围。例如,对象可能被持久化到磁盘中,以后由其他jvm重用;它们也可以通过网络发送和接收。
为了支持这些场景,即使在离开jvm时,对象也必须是可解释的。因此,jvm采用对象序列化/反序列化(OSD)机制,该机制将Java对象转换为通用数据格式(序列化),并在jvm中重用时转换回来(反序列化)。Java系统库(JSL)已经为应用程序提供了内置的OSD库。图1显示了JSL OSD的工作流程。至于序列化部分,对象被转换成一个字节数组,该数组遵循jvm之间一致同意的数据格式。字节数组将被写入磁盘或通过网络发送。当另一个JVM接收到字节数组时,它通过反序列化将字节数组转换回对象。
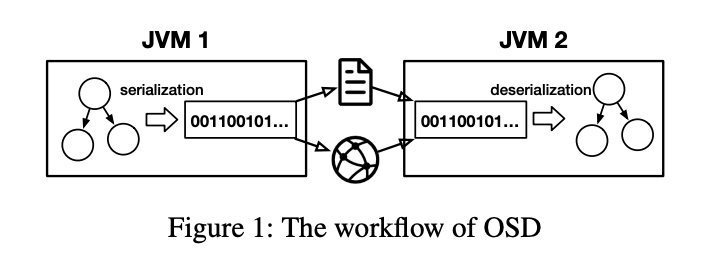
OSD机制有两个主要优点。首先,该库提供了一种通用的数据格式,这样就可以在不同版本和配置的jvm之间转换Java对象。其次,序列化的数据被压缩,并且在磁盘和网络中产生更小的占用。
3.2 Limitations and opportunities
主要缺点是性能损失
- Transformation overhead:OSD为对象持久化和传输引入了额外的阶段。为了序列化一个对象,OSD应该遍历所有可访问的对象并存储它们的类型信息。对于反序列化,OSD需要扫描序列化后的数据并重构对象。
- Memory footprint(内存占用):产生很多临时对象,加大内存占用,导致更频繁的 GC
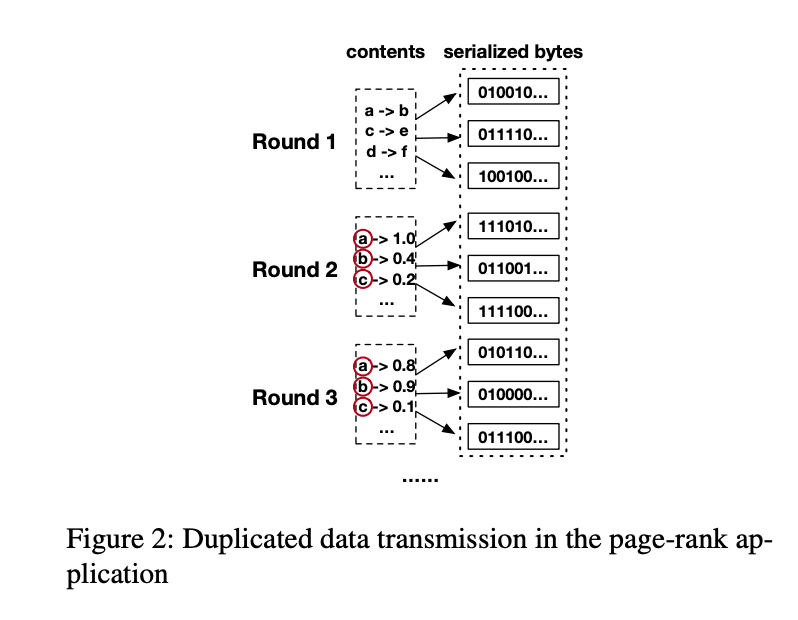
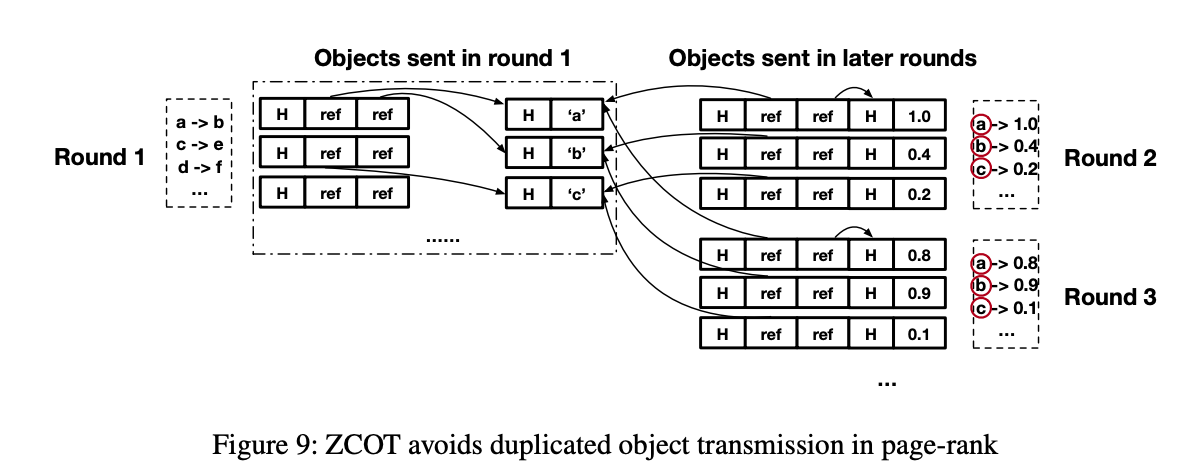
- Duplication transmission:举了 spark 的 page-rank 算法例子,这里没太理解,需要再看看。
- 大概意思是,第一轮中,传输 url 的网络拓扑关系,第二轮中,迭代的传播每个 URL 的 rank,并组织为键值对后发送。由于所有对象都被转换并合并为字节数组,jvm无法判断以前是否接收过某些对象。它们必须将所有对象作为单个字节数组接收,这导致了不必要的网络传输和OSD阶段。
复习:page-rank 算法
另一方面,并不总是需要通用的数据格式。因此,人们提出了许多优化措施来降低OSD的性能开销,包括软件[26,38,39]和硬件[16,32,40,46]。由于基于硬件的方法需要构建定制的硬件加速器来改进OSD,因此本工作主要侧重于使用现成硬件的基于软件的方法。
3.3 SOTA
本文基本思想:achieve an agreement on object representation among JVMs.
Kryo:与JSL的OSD相比,Kryo改进了二进制数据格式,以实现更小的序列化数据大小和更好的性能。但是 OSD 的步骤还是一个不少
Skyway:提出直接发送 object graph,而不是序列化字节。在Skyway中,序列化阶段几乎被移除,因为对象不再被转换为二进制格式。虽然Skyway在OSD中简化了阶段,但仍然需要修改对象。
首先,它需要将 header 中的类型信息转换为 globally-agreed 的ID,以便所有jvm都可以识别它。其次,它需要在复制之后修复引用,因为对象已经移动到不同的地址。此外,Skyway还要求程序员手动标记序列化阶段开始的点。
Naos:一种网络特有的数据传输机制。与Skyway类似,Naos也采用全球服务来达成类型协议,但它依赖于RDMA技术来实现快速的零复制对象传输。
然而,Naos仍然需要修改对象头和引用。此外,它只支持基于网络的传输,现有的应用程序需要进行重大修改才能利用Naos(兼容性不好)
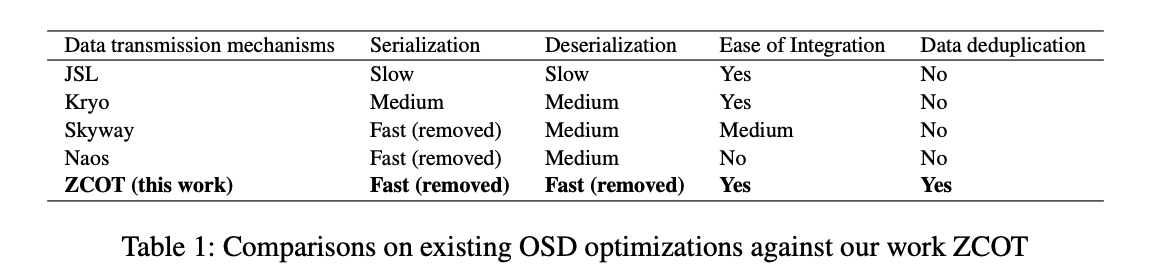
3.4.1 与 SOTA 的对比
先前的优化提出了不同的解决方案来减少OSD的开销。但是,它们不能消除整个OSD进程。尽管像Naos这样的最新工作消除了序列化阶段,但是仍然需要一个反序列化阶段来修复类型信息和引用。
此外,它们都没有考虑到重复数据传输的问题。本文提出了零变化对象传输(Zero-Change Object Transmission,简称ZCOT),旨在消除数据交换过程中的整个OSD过程。在ZCOT中,对象传输以最直接的方式进行:发送方JVM复制对象,接收方无需任何修改即可直接使用它们。ZCOT还考虑了重复传输问题,提供了重复数据删除模块。
最后,**ZCOT不绑定到特定的网络技术(如RDMA)**,并为现有的应用程序提供易于集成的接口。
3.4 goal
- 提出一个在 JVMs 之间能够全局适用的 agreement 来表示对象
- 兼容已有程序
4. Design
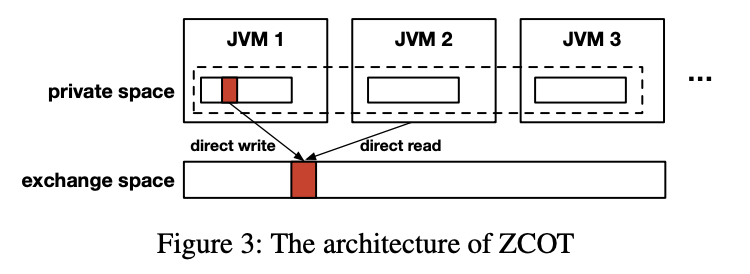
ZCOT的核心思想是为运行在不同机器上的jvm构建一个类似分布式共享内存(DSM)的抽象
在支持zcot的系统中,每个JVM的堆由两部分组成:其私有空间(原始Java堆)和全局共享交换空间。对象最初是在私有空间中管理的。当它们需要通过网络发送或持久化到磁盘时,它们将被复制到交换空间。交换空间是对所有jvm可用的抽象;每个JVM都可以直接访问其中的对象。
因此,可以通过直接复制到交换空间来实现对象传输,并且可以消除整个OSD过程
虽然我们的交换空间与DSM有着相似的智慧,但它只用于数据交换,不需要解决一致性等复杂的问题。它还假设交换空间中的对象是不可变的,这通常适用于Spark和Flink等大数据分析。如果一个写操作发生在交换空间中的对象上,ZCOT会在JVM的私有堆上为它创建一个副本。
复习:COW 机制
4.1 challenges
- 如何 build 一个所有 JVMs 都能 access 的 shared exchange space
- 如何利用 exchange-space 来支持 OSD-based applications
- 在各 JVMs 的 GC 情况下,如何管理交换区的各对象
- 如何解决冗余传输问题
4.2 DCDS
DCDS 是 exchange space 的实现基础。
ZCOT依靠其分布式类数据共享(DCDS)机制来构建一个全局可访问的共享空间。DCDS保证与类相关的元数据将映射到所有jvm的相同虚拟内存地址。这有助于jvm在类元数据上达成一致,因此不需要进行与类型相关的修改(例如,标识符)。
在这种设计中,DCDS机制帮助不同的JVM之间达成对类元数据的一致性,因此不需要对类型进行任何修改,比如标识符的修改。换句话说,不需要在不同JVM之间对类的元数据进行修改或调整。这样做的好处是,不同的JVM可以共享相同的类定义,无论是在对象传输还是在远程方法调用等场景中。
具体来说,”no type-related modifications (e.g., identifiers)”表示在ZCOT和DCDS的设计中,不需要对类型相关的内容进行修改,例如标识符的修改。这意味着不同的JVM可以共享相同的类定义,而无需在类的元数据上进行任何改动或变化。这有助于确保在分布式系统中的不同节点之间可以共享和使用相同的类定义,以便更好地实现数据传输和方法调用的一致性和可靠性。
天然保持 JVMs 之间的类数据一致性,而无需额外修改
工作流:
- 集群管理者为所有的 JVMs 准备一个共享类 archive 文件(包含在jvm间通信期间共享其对应对象实例的所有类)
- 归档文件将在JVM启动期间使用,归档文件中的类将被映射到给定的虚拟地址。(虚拟地址范围被记忆和标记为交换空间的一部分。此步骤确保jvm在类上共享相同的视图)
- 虽然DCDS要求提前知道应用程序的数据类型,但主流的大数据分析框架通常通过发送一个fat jar文件来保证这一点。
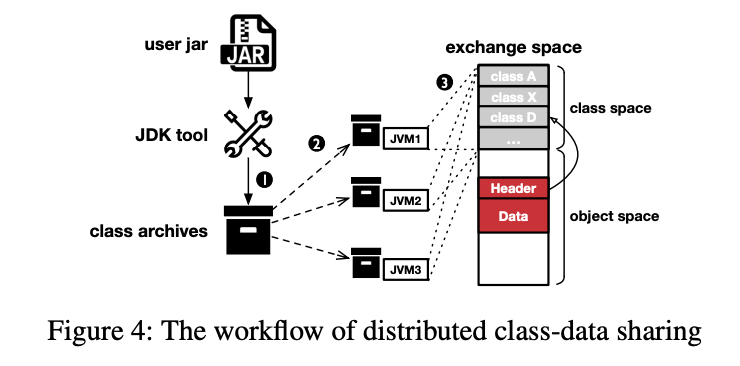
ZCOT 如何通过网络传输 objects with its DCDS support
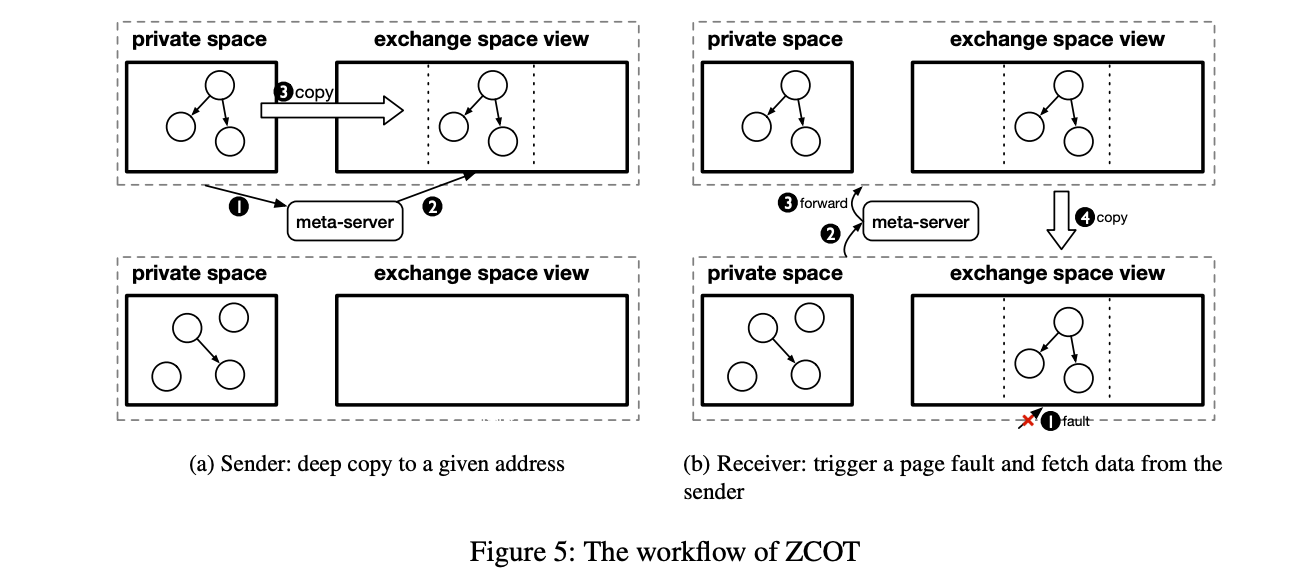
- 发送方JVM在交换空间中申请一个可用内存块用于对象复制。(这是通过与外部 metadata server 通信实现的)
- 发送方JVM将对象复制到块的内存地址。这一步类似于普通Java应用程序中的深度复制。
- 为了检测循环并避免在同一对象上重复复制,我们在每个对象头中添加一个标记字,以便在复制后存储其新地址。
- 复制的对象保存在发送方机器上,并由接收方惰性地检索。
- 只有当接收方需要用到这个对象的时候,才会去真正 retrieve
- 当接收JVM试图访问这部分数据时(图5b),它会遇到页面错误。预先注册的页面错误处理程序,会向 metadata server 请求错误页面。 metadata server 跟踪了交换空间中内存地址的 ownership,因此它将请求转发给数据的 owner。
- 发送方与接收方建立连接,并将请求的对象放置到所需的地址。现在接收者可以直接访问这些对象进行进一步处理,既不需要更新元数据,也不需要修改引用(即零更改)。
为什么原有的方案需要更新元数据,修改引用?
4.3 兼容 OSD-based 场景
4.3.1 编程接口
ZCOT应该提供用户友好的 interfaces,以便与应用程序轻松集成
JSL为OSD实现提供了基于流的类。ObjectOutputStream类提供了writeObject方法来将对象序列化为流(通常是文件或网络)。类似地,ObjectInputStream类提供了readObject方法来将数据反序列化为对象。
因此,以前的OSD优化(如Skyway)通过继承这两个类来实现新的序列化器/反序列化器,以方便集成。
ZCOT采用了类似的策略,图6显示了它的基本类:ZCObjectOutputStream和ZCObjectInputStream,它们分别是ObjectOutputStream和ObjectInputStream的子类。与ObjectOutputStream相比,ZCObjectOutputStream略微修改了writeObject的接口,以支持不同的基于osd的场景(稍后讨论)。要使用基于zcot的通信,应用程序只需要用我们的流类替换原来的流类。相比之下,先前的工作要求开发人员修改原始通信模型或注释序列化点。(了解一下)

4.3.2 OSD-compatibility
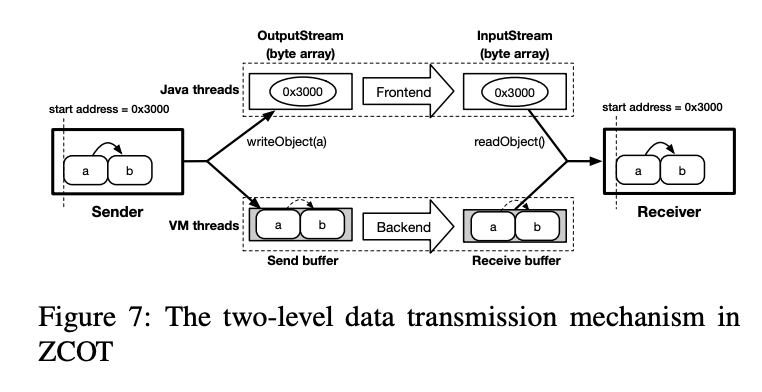
为了与OSD接口(writeObject和readObject)保持兼容,ZCOT还应该使用字节数组传输数据。
为此,ZCOT采用了 two-level transmission mechanism 。如下图所示,ZCOT通过前端和后端传输数据。前端传输兼容OSD接口,但只发送元数据,包括对象的起始地址和数据长度。当ZCObjectInputStream通过readObject接收元数据时,如果触发页面错误,它将直接访问相应的地址,并通过后端传输获取对象(如图5b所示)。ZCOT将在发送方和接收方jvm中启动专用的VM线程来传输请求的对象。
前端 wrap 了一层 OSD base 的字节传输,但只传输元信息,后端仍然使用 ZCOT 的框架进行传输
4.3.3 支持不同的 OSD 场景
在OSD库中,当调用writeObject时,对象被序列化并写入流(例如,图6中第3行定义的out变量),通常被重定向到文件或网络中。为了支持这两种情况,ZCOT在ZCObjectOutputStream的构造函数中添加了一个参数volatile(第6行)。当volatile设置为false时,复制的对象将被写入文件,并且内存页可以很快通过GC回收(详细信息请参见第4节)。
尽管如此,这些对象仍然在交换空间中保留相应的虚拟地址。当对象数据被其他jvm读取时,元数据服务器要求发送方传递该文件,以便接收方可以将其映射到相应的内存地址。当volatile为true时,情况就简单了,它表示基于网络的传输。在这种情况下,对象只保存在内存中,并且只有当它们被其他对象读取时才可以回收。
5. Memory Management
这里需要对 group 组的概念熟悉一下
5.1 Group-based management
与传统的基于dsm的系统不同,ZCOT引入了组,这是一种用于分布式内存管理的语义感知概念。
正如第2节所分析的,大数据分析框架将序列化对象视为整个数据集(单字节数组),并将它们一起检索。因此,ZCOT将在同一个writeObject调用中复制的所有对象放到一个组中,以便将它们一起管理。当接收端出现页面故障时,ZCOT会将属于同一组的所有相关数据页发送给接收端,避免以后出现故障。这种机制,即基于组的预取,利用OSD场景中的语义来减轻传统DSM中基于页面的管理开销。
5.2 Metadata Server
jvm通过远程过程调用(rpc)与元数据服务器通信,以获取或释放交换空间中的内存资源。
核心数据结构:
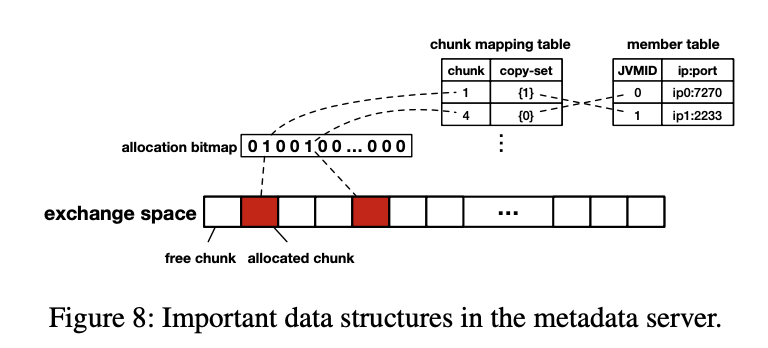
元数据服务器对组是不可知的;组仅由单个jvm管理。
元数据服务器将共享交换空间划分为大小相等的内存块(默认为256MB),
为什么设置这么大,因为是为了大数据分析应用,一次性传输字节数差不多是 256 MB
以便进行内存分配和回收。它还维护一个分配位图(allocation map)来标记是否已经分配了一个块。每个块都分配了一个整数ID,这是通过与交换空间的起始地址的相对偏移量来计算的。
为了跟踪块的存储位置,元数据服务器为每个块维护一个副本集(copy set),该副本集存储在块映射表(chunk mapping table)中。复制集包含存储相应块(在内存或磁盘中)副本的jvm,copy set 中的 JVMs 也用整数id表示。JVM的ID和信息(如IP地址)之间的映射存储在一个分离的成员表(member table)中。
由于每个JVM都需要与元数据服务器通信,因此它的可靠性变得相当高。为了容忍元数据服务器上的故障,我们可以为它引入 replicas(冗余容灾备份),并且考虑到元数据服务器和工作jvm之间的通信频率较低(在持续数秒的数据处理阶段进行多次通信),开销是可以接受的。
5.3 RPC interfaces
metadata server 提供下列四个 rpc 接口
int register(std::string ip, int port); |
register- 只有在启动JVM时才调用register。ZCOT提供了一个JVM选项-XX:+UseZCOT,启用这个选项的JVM会自动生成一个RPC线程,并向元数据服务器发送一个注册RPC,并带有它的IP地址和监听端口。接收到RPC后,元数据服务器将IP和端口号保存到成员表中,生成一个整数作为JVM的ID,并返回该ID。对于后续rpc, jvm应该始终附加返回的ID,以帮助元数据服务器维护对象的存储位置(在上面的接口中省略)。
acquire当JVM从交换空间中耗尽分配的内存时,它应该发送获取rpc以获取更多内存资源。在接收到获取请求后,元数据服务器扫描其位图以分配可用块。
之后,元数据服务器记住分配的块与JVM的ID之间的关系,并返回块。为了减少位图扫描的开销,ZCOT会记住最后一个成功分配的块的地址,并在那里开始扫描。如果扫描到的地址到达交换空间的末端,ZCOT将从开始继续扫描。为了处理同步获取请求,ZCOT引入了位图锁来确保位图被独占访问
位图锁的设计
get_remote- 被遇到 page fault 的 JVM 使用
- 由于页面错误表明请求的对象没有存储在本地,所以JVM发送
get_remote来获取相应的块。在接收到get_remote之后,元数据服务器获取包含地址的相应块,并通过扫描块映射表查找哪些jvm存储了该块。如3.2节所示,元数据服务器将请求转发给相应的JVM进行实际的数据传输。 - 由于块的大小相对较大,发送块可能会带来相当大的性能开销。为了减少传输的数据大小,发送方JVM只发送块中使用过的页面,这些页面在前端传输中表示为数据的长度(图7)。
- 由于ZCOT基于组的预取机制,发送方可以直接将同一组中的多个块发送给接收方。在这种情况下,接收方负责发送辅助RPC来更新元数据服务器中的副本集
release- 当JVM发现块中的对象不再使用时,它会发送
release以放弃该块。接收到release后,元数据服务器将从块映射表中相应的副本集中删除JVM的ID。如果没有JVM存储这个块,元数据服务器将通过在位图中将相应的位标记为空闲来回收它。
- 当JVM发现块中的对象不再使用时,它会发送
5.4 GC
由于交换空间中的对象可以从各个jvm访问,因此它们也会受到GC的影响。为此,ZCOT将其内存管理策略与OpenJDK中的默认GC算法G1集成在一起,以确保分布式内存管理的正确性并减少GC开销
5.4.1 G1 basis
分代划分内存
为每个内存区域维护名为 remember set 的元数据,保存指向该区域所有对象的引用
remember set,记忆集:
参考:https://blog.csdn.net/kang389110772/article/details/120299478
参考:https://blog.csdn.net/huangzhilin2015/article/details/115288697
G1每一个Region都会对应Remembered Set,它会记录这个Region清理时需要扫描哪几个Region。之所以这么做的原因是因为G1是分了Region,如果只使用Card Table,那么就可能不能发挥Region的作用,甚至会变成FULL GC。所以当CT更新后,会异步的去更新RS。
- 通过检测Java代码中的所有写操作(也称为写屏障)来更新记忆集
write barriers,写屏障:
参考:https://juejin.cn/post/6987298527562956831
参考:https://blog.csdn.net/nazeniwaresakini/article/details/105947623
写屏障,其实就是指在赋值操作前后,加入一些处理(可以参考AOP的概念),读屏障的含义也类似。
对一个对象引用进行写操作(即引用赋值)之前或之后附加执行的逻辑,相当于为引用赋值挂上的一小段钩子代码。
stop-the-world
在GC1期间,每个选择的区域被同时处理:一个专用的GC线程扫描区域的记忆集,找到所有可访问的对象,并将它们复制到一个空区域(称为幸存者区域)。
5.4.2 Integrated with G1
提出了 ZCRe-Region,从 metadata server 分配的一块新区域
这里的细节没太理解,读懂的大佬可以跟我交流下~
与G1中的区域相比,zcregion的大小并不固定。每个zcregion对应交换空间中的一个组,其中的所有对象都具有相同的生命周期。由于ZCRegions中的对象与其他区域中的对象具有不同的行为,因此G1应该特别对待它们。首先,我们修改写屏障的行为以考虑区域。当一个引用指向一个zcregion中的对象时,我们不需要记住这个引用,而只是将这个zcregion标记为已使用的。这是因为只有当没有引用指向zcregion中的对象时,才会收集它们。
类似地,GC线程在GC期间不需要扫描ZCRegions,因为如果存在任何指向该区域的引用,则所有对象都被视为活动对象。当GC结束时,JVM将扫描所有的zcregion,并找到那些不包含传入引用的zcregion。对于那些区域,JVM调用release RPC来回收相应的块。如果将组中的对象写入磁盘,则GC也可以回收相应的ZCRegion,但JVM不会调用释放,因为虚拟地址仍然由组保留
综上所述,我们的设计成功地将交换空间的内存管理与G1GC集成在一起。当GC结束时,根据基于可达性的算法自动回收交换空间中的内存资源。
此外,通过对交换空间中的区域进行特殊处理,避免了不必要的元数据跟踪和对象扫描。在某些情况下,这种设计甚至可以减少GC暂停时间
6. Transmission Deduplication
以 page rank 算法为例
在第一轮发送基于URL的网络拓扑时,发送方已将所有URL字符串对(以及两个字符串对象)复制到其相应的地址中。在接下来的几轮中,应用程序发送键值对来更新每个URL的排名值。
由于所有键值对都是作为对象发送的,因此ZCOT发现所有URL对象都已发送要简单得多。因此,发送方可以直接用交换空间中的地址更新那些键值对中的引用,从而消除URL对象上的重复传输。
【可拓展点】
6.1 duplication detection
ZCOT 遵循一个简单的标准:如果一个对象在 exchange space,那么对它复制的尝试是重复的
参考上图,以 page rank 为例,假设JVM在第1轮中接收到网络拓扑;它从交换空间读取URL对象,并在接下来的几轮中使用它们(而不是重新复制一份再发送出去)。因此,当它将更新后的秩值传播到其他JVM时,它仍然使用从其他JVM接收的URL对象。
可以简单理解为共享全局变量了,而不是每次函数调用都复制一份
在接下来的几轮中复制URL排名对时,ZCOT会检查每个对象的地址,从而避免复制那些已经在交换空间中的URL对象。
6.2 Dependency management
尽管ZCOT中的重复数据消除可以通过避免在同一对象上重复复制来减少网络开销,但它也通过引入组间引用使内存管理变得复杂。如第4.1节所述,每次对writeObject的调用都会为对象管理创建一个新的组(这里需要再看看!),每个组都通过调用readObject单独使用。
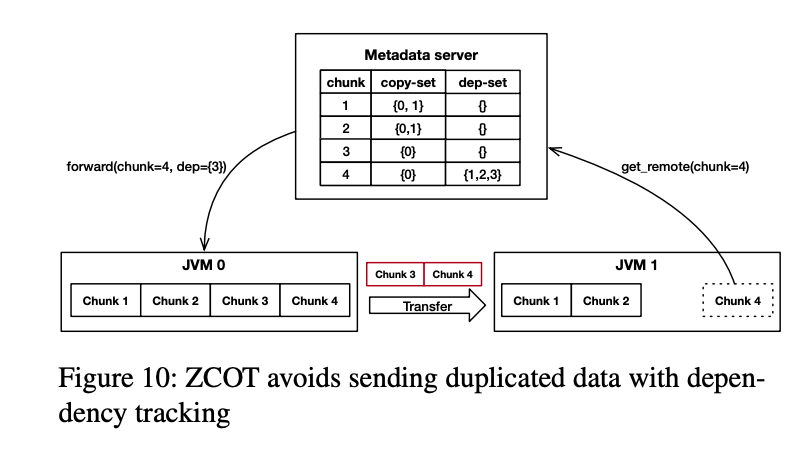
在对不同组中的对象进行重复数据消除后,一个组中的目标可以包含对另一个组的目标的引用,这一点应该在对一个组进行垃圾收集时得到正确处理。为此,ZCOT将这些引用作为组之间的 dependencies 进行了管理。
由于大量的组间引用,ZCOT不维护引用级别的依赖关系。当一个组拥有对其他组中任何对象的引用时,ZCOT会将该组标记为依赖于其他组。依赖性跟踪仍然是通过扩展写屏障来实现的(即 wrap write barrier)。为了记住所有依赖项,ZCOT扩展了元数据服务器中的块映射表,以包含每个块的依赖项集,该依赖项集存储它所依赖的所有其他块。(见 5.2 metadata server 的描述)
当JVM发现其组在重复数据消除后依赖于另一个组时,它会向元数据服务器发送一个新的RPC add_dependence。由于元数据服务器不知道组,RPC应该指定它所依赖的组所拥有的所有 chunk ID。这些块ID将被添加到元数据服务器设置的相应依赖项中。
为啥 metadata server 不知道 group?
示例:request chunk4,然后 chunk4 依赖 123,原来的方法是 123 都需要 transfer。但是发现 JVM1 已经有 chunk12 了,所以就只传输 chunk3。
具体描述见论文。
有两个关键
- 添加依赖
- 管理依赖(依赖是如何记录的?)
6.3 GC
由于远程 JVM 可能跨组引用本地 JVM 的组,因此本地 G1GC 需要考虑 remote inter-group references
改进措施:
如果 JVM 通过写屏障探测到 ZCRegion 有来自其它 ZCRegion 的引用
如何通过写屏障检测
- 则将该 ZCRegion 标记为 pinned,同时该区域无法被回收。
- 并将依赖关系通过 RPC 发送给 metadata server
- GC 结束时,pinned 的 chunk 不被收集
- 只有当所有依赖它的 chunk 都被 GC 时,pinned 的 chunk 才可被 reclaimed
- 在这种情况下,元数据服务器将向相应副本集中的所有 JVM 发送
canRelease消息,这些JVM将把 ZCRegion 标记为 unpinned,以便在以后的 GC 周期中安全地回收它。
- 在这种情况下,元数据服务器将向相应副本集中的所有 JVM 发送
6.4 Internalization
大数据分析通常会生成大量类型简单的对象,如Integer、String、Double等。OpenJDK提供了一种内部化机制,可以将具有相同内容的对象合并在一起。例如,如果值在-128和127之间的Integer对象的值相等,则它们将合并为一。ZCOT也采用了这种重复数据消除机制,但在其分布式交换空间中。它扩展了DCDS,以便所有JVM在启动期间在相同的虚拟地址分配一个小区域,以包含全局共享的Integer对象。由于这种优化,可以大大减少传输的整数的数量。
7. evaluation
overview
我们根据最先进的OSD库和微基准测试和宏基准测试的优化来评估ZCOT。
- 微基准包含基本和复杂的数据结构,用于数据传输
- 而宏观基准包含两个大数据分析框架(Spark和Flink)
微基准测试的结果表明,ZCOT优于其他OSD库,特别是对于复杂的数据结构,与Naos相比,ZCOT的加速速度高达4.35倍[39],这是对OSD最先进的优化。对于macrobenchmark, ZCOT优于Spark和Flink中的默认OSD库,从而分别将应用程序时间提高了23.6%和22.2%
7.1 测试的 workload
Microbenchmark
- 微基准标记包含先前工作[26,39]中使用的四种不同的数据类型:2-dimensional points、key-value pairs、hashmaps 和 media objects。为了模拟大数据场景,我们将它们传输到长度为65536的大数组中。由于一些基线对于大型媒体对象阵列崩溃,我们将该数据结构的长度减少到16384
Spark
- 一个数据分析引擎,需要JVM之间的大量数据传输。
Flink
ApacheFlink[6](v1.14)是一个用于批处理和流工作负载的分布式数据处理引擎。
As for baseline,将ZCOT与两个常用的OSD库(JSL和Kryo)以及两个 SOTA 的OSD优化(Naos和Skywy2)进行了比较。
我们的测试环境包括一个由100 Gbit/s Mellanox ConnectX-5 NIC连接的四个节点组成的集群。每个节点包含双Xeon E5-2650 CPU和128GB DRAM
7.2 Microbenchmark
详细表现见论文。在 2-dimensional points 表现一般。主要是因为数据转化上的优化被网络的 overhead 抵消了
7.3 Spark
- 如何集成?
要在Spark中采用ZCOT,我们需要实现一个新的数据序列化器ZCSerializer来取代默认的KryoSerializer。尽管该名称似乎涉及OSD阶段,但仅出于兼容性考虑,在传输过程中仍然保持零变化。
ZCSerializer包含70行代码,其中大部分是从JSL序列化程序继承的。此外,我们用我们的替换了来自JSL的原始流类。如果Spark用户想要启用ZCOT,ta 只需要(1)将Spark.serializer配置为ZCSerializer,(2)将XX:+UseZCOT添加到所有JVM的启动选项中
- 如何测试?
使用 spark 官网的4个经典 cases,并进一步将结果分为四个不同的阶段:写入(序列化)、读取(反序列化)、计算和垃圾收集(GC)。由于Spark中的四个阶段不重叠(GC阶段仅包含停止世界时间),因此累积时间等于总执行时间。
对比得出,ZCOT 主要的优化集中在 OSD 阶段,其中 page rank 由于 OSD 占比大,优化效果最好
- 总结
尽管ZCOT需要管理复制的组(ZCRegions),但其粗粒度收集策略避免了扫描ZCRegions内的对象。此外,ZCOT通过消除 serialization 阶段避免了生成单片字节数组,这可以减轻内存压力,并引入不太频繁的GC。
注意,ZCOT中的计算时间比JSL和Kryo中的要长一些。这可以由两个原因来解释。
- 由于ZCOT在传输过程中不压缩对象内容以实现零变化,因此传输的数据大小大于JSL和Kryo,这导致更大的网络开销(包括在计算部分中)
- 重复数据消除模块使同一数据集中的对象分散到不同的虚拟地址范围,这可能导致更多的随机内存访问和缓存未命中。
重传可以显著减少传输字节数,但由于没有使用 compact format,因此 ZCOT 仍然比 Kryo 和 JSL 的 overhead 更高
7.4 Flink
将 ZCOT 的 OSD 接口替换 Flink 的接口即可
8. Related work
8.1 OSD 优化
为了优化OSD中耗时的阶段,Kryo[38]、Skyway[26]和Naos[39]等先前的工作已经改进了传输数据格式或利用了网络硬件技术的进步。相反,ZCOT旨在消除整个OSD过程。除了基于软件的技术外,另一项工作采用基于硬件的方法来减少OSD开销。Optimus Prime[32]构建了一个数据转换加速器(DTA),以提高微服务的OSD吞吐量。麦片[16]与硬件加速器共同设计数据传输格式,以提高Spark应用程序的性能和能效。
Morpheus[40]将反序列化阶段转移到智能固态硬盘中,而Hgum[46]则利用FPGA来处理OSD任务。ZCOT基于现成的硬件,因此与那些基于硬件的优化正交
8.2 和其它工作的区别
- for Distributed language runtimes
Java/DSM[43]在用于异构计算的DSM之上构建分布式JVM。
JESSICA[21,47]提供了单个全局线程空间,并透明地迁移Java线程以实现负载平衡。
Comet[14]为在移动设备和云上运行的JVM构建了DSM抽象,并依靠其内存模型来实现有效的代码卸载。
Semeru[41]提出了一种通用的Java堆抽象,这样Java应用程序就可以在内存分解架构中自由访问所有内存资源。这些系统利用共享堆来同步不同端点之间的数据,但它们没有考虑大型应用程序的JVM间通信的性能开销。
XMem[42]能够在同一物理机器上的多个JVM之间实现高效的类型安全对象共享,但它不考虑分布式环境。
ZCOT还提出了一种分布式运行时设计,但它主要侧重于增强多个JVM之间的数据传输。
- Runtime optimizations for Java
ITask[11]使数据处理任务在面临巨大内存压力时可以中断,从而提高性能并减少内存不足错误。
Yak[27]将应用程序执行划分为历元,并在历元结束时触发GC。
Broom[12]采用基于区域的设计,并将具有相同生命周期的对象放入同一区域进行快速回收。
ScissorGC[18,19]提出了阴影区域,以提高全GC阶段的可扩展性。
Taurus[22,23]协调来自不同JVM的GC,以达到更好的性能或更小的尾部延迟。
Facade[28]和Deca[36]将大量数据对象存储在堆外内存中,以减少GC压力,而
Gerenuk[24]允许对序列化数据进行推测性执行,以减少内存占用和GC开销。
ZCOT专注于消除OSD过程。
96. 总结
主要解决四个问题
- 设计一个所有 JVMs 都能 access 的 exchange space
- 让 exchange space 的 abstraction 能适配 OSD
- 让 exchange space 的 object 适配于 individual JVM 的 GC
- 解决重复传输问题
如何集成 G1 GC
- 提出 ZCRegion,exchange space 里的 group 被对应划分为 ZCRegion
- 修改 write barrier 对 ZCRegion 的行为,只 mark 整个 region 是否被使用
- GC 线程不需要检查 ZCRegion
- GC 结束时,JVM 再检查是否有 incoming reference to ZCRegion,若无,调用 release 释放之
如何 deduplication
- 标准:如果对象在 exchange space 里,那么不需要再复制它
- 还需要维护 dependency 的关系。维护 group 粒度的 dependency,在 metadata server 的 mapping table 中增加 dep set
- get_remote 时,只 fetch 不存在的 chunk(需要 fetch 所有依赖的 chunk)。同时 fetch 时,如果对象已经在 exchange space 里,不需要 fetch 了
97. 疑问
- ZCOT 的 workflow 和直接网络传输有啥区别,虽然避免了对象改变,但本质上还是需要网络传输
- 如果有多个 jvm 持有 receiver 所需的 chunk,metadata server 如何转发请求
98. 相关知识
1. JVM object representation
header(Klass)
data
在每个 JVM 中,对象的 Klass 和 data 是不同的,不能之间跨 JVM 移动。异 JVM 无法 interpret
- 对象头(Object Header):
- 对象头是一个特定大小的数据结构,用于存储关于对象的元信息和运行时数据。
- 对象头包含了一些固定的字段,如对象的哈希码(Hash Code)、锁状态、垃圾回收标记等。
- 对象头的具体结构和字段的大小和布局可能会因不同的JVM实现而有所不同。
- 实例数据(Instance Data):
- 实例数据是对象中的实际数据,它包含了对象的字段和对应的值。
- 实例数据存储了对象的状态信息和其他实例级别的数据。
- 实例数据的大小和布局取决于对象所属的类以及其定义的字段。
JVM根据类的定义和实例数据的布局,分配足够的内存来存储对象。对象的内存分配通常是在堆上进行的,可以通过垃圾回收来管理对象的生命周期和内存释放。
需要注意的是,JVM对对象的内部表示是实现特定的,并且可能因JVM实现、JVM版本和垃圾回收器的不同而有所差异。对象的内部表示通常是透明的,开发人员可以通过使用Java编程语言中的对象操作(如字段访问、方法调用)来访问和操作对象的数据。
2. reference fixing problem
klass 在不同的 jvm 中不同,传输的时候需要修改 klass 的引用。
解决:在 exchange space 中开辟共享区,存放 klass
99. 术语表
OSD
The object serialization and deserialization
ZCOT
Zero-Change Object Transmission
DCDS
distributed class-data sharing,分布式类数据共享
本文的 dcds 是对 openJDK dcds 功能的扩展
RDMA
Remote Direct Memory Access,远程直接数据存取(远程直接内存访问)
DSM
distributed-shared memory
group
主要是因为大数据分析应用把序列化后的数据当作一个整体进行发送和接受,因此 ZCOT 也成组发送,防止频繁的 page fault
元数据服务器对组是不可知的;组仅由单独的JVM管理
memory chunk
ZCRegion
为了集成 G1 GC 时提出的概念。和 G1 分配的 regions 相比,ZCRegion 的大小不固定
APPCDS
Application Class-Data Sharing