Jul 06, 2023
论文阅读-ElasticFlow:Training Plf for Distributed DL
ElasticFlow: An Elastic Serverless Training Platform for Distributed Deep Learning
由于笔者将原阅读报告写在 word 上,本文是从 word 复制过来,因此在中英文之间的空格等方面可能有一些格式问题。请读者见谅~
1. 论文研究背景、动机与主要贡献
1.1. 研究背景
Distributed Training for Deep Learning: Deep Learning(DL)发展火热,为许多应用程序和服务提供支持。相应地,训练DL模型成为一项重要工作。而对于包括许多迭代的DL训练任务,其非常耗时,因此分布式训练被广泛用于加速DL训练过程。
Serverless Computing(或FaaS): Serverless Computing能够对用户屏蔽底层硬件资源的使用和配置,使得用户只需要用函数描述workload并提交至Serverless平台即可。这种计算模式将System相关的底层资源管理offload给服务提供商,让用户专注于解决业务问题。
Elastic Training:相比于已提出的许多解决方案,ElasticFlow 不关注如何加速单个 job,而是基于弹性训练的研究进展,在多任务场景的任务调度下实现应用弹性缩放,在云中调度多个作业并利用弹性特性以无服务的方式为作业提供性能保证。
1.2. 动机
本文从已有的DL分布式训练痛点出发,主要提出了以下2点动机:
Server centric架构中DL相关问题与系统问题高度耦合。 对于DL开发者来说,使用server-centric风格的分布式训练时除了配置编写DL相关的业务问题,还需要配置低层的系统问题,显式地请求硬件资源并配置实体物理机的各种参数,如GPU的local batch size、worker数量等。这些系统方面的底层工作对DL开发者来说尤具挑战性。
大多数现有解决方案不具备DL作业资源运行时的弹性扩展功能 ,从而无法提供性能保证,即保证在DDL(截止日期)之前完成作业。大多数现有解决方案侧重于优化JCT(作业完成时间),但却忽略了对作业DDL的性能保证。它们缺乏弹性向上或向下扩展调整作业资源以优化集群范围内的资源利用率并满足DDL的能力和灵活性。
1.3. 主要贡献
设计出了分布式DL训练的弹性Serverless Computing平台ElasticFlow解决上述痛点,ElasticFlow将DL业务问题与资源管理配置等系统问题解耦,对用户屏蔽底层系统细节,同时利用弹性扩展来保证DL任务的DDL。
提出了minimum satisfactory share的metric来获取作业在非线性scaling曲线下满足DDL所需的最小GPU数量。
设计了admission control算法 ,基于minimum satisfactory share进行准入控制,保证所有被允许的作业都能在DDL前完成。
设计了一种弹性资源分配算法 ,基于递减收益为已允许的作业弹性分配GPU以最大化资源利用率。
实现了ElasticFlow的系统原型 ,并将其与PyTorch集成。测试显示,在满足DDL作业数量的指标上,ElasticFlow的效果比STOA优秀1.46-7.65倍。
2. 论文问题描述或定义
本文的问题描述有2个方面:
2.1. 分布式训练的2个问题
- 训练吞吐(throughput)随 GPU 的数量非线性增长 (non-linear scaling curve) 。由于参数同步和其他开销,吞吐量不会随着工作线程的数量线性增加。传统的最早截止日期优先(early-deadline-firt,EDF)算法虽然对满足截止日期是有效的,但这种解决方案将整个集群视作一个逻辑工作者,不适用于非线性scaling任务。ElasticFlow的DDL感知调度应该考虑非线性scaling场景。
- Worker的拓扑位置(placement)影响分布式任务的性能。 并且拓扑相关的布局进一步影响训练吞吐的scaling曲线(Topology-aware),使得该问题与前述问题交织在一起。在为作业分配资源时,ElasticFlow应该结合实际的worker placement考虑一组scaling曲线。
2.2. 算法设计时的具体优化目标
Minimum satisfactory share: 对于每个作业,找到能满足其DDL所需的最低资源数量
Admission control: 对于新到达的作业,只有ElasticFlow能保证其作业截止日期时作业才能被接受。具体定义如下:
在如下约束条件下(具体解释:约束1表示每个job_i都能在DDL前达到终止条件,约束2表示对于任何时隙t,所有job所分配的GPU数量总和不能超过系统资源总和)
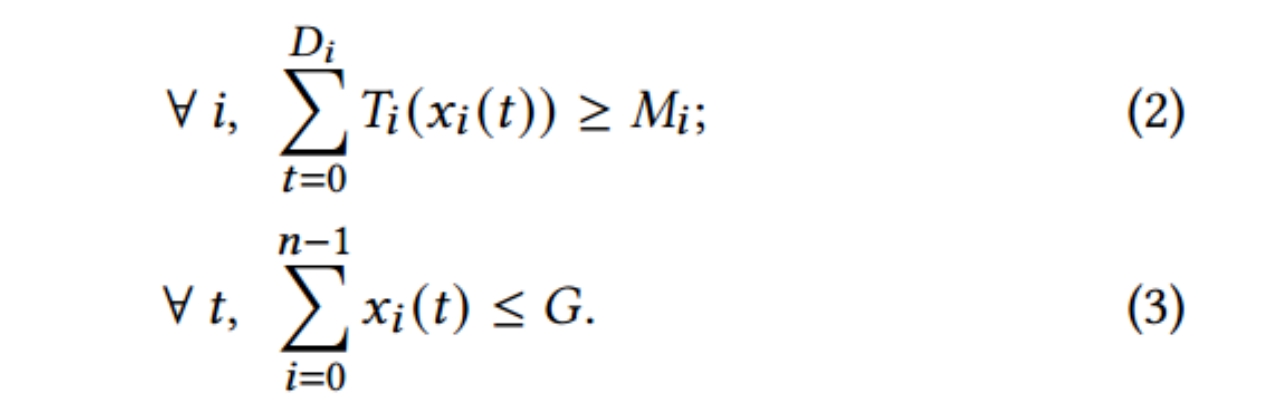
对所有job按照DDL进行升序排序, 若下式成立(对于任意i,前i个job的GPU时间总和小于系统GPU总数与第i个工作DDL(单位为time unit)的乘积)
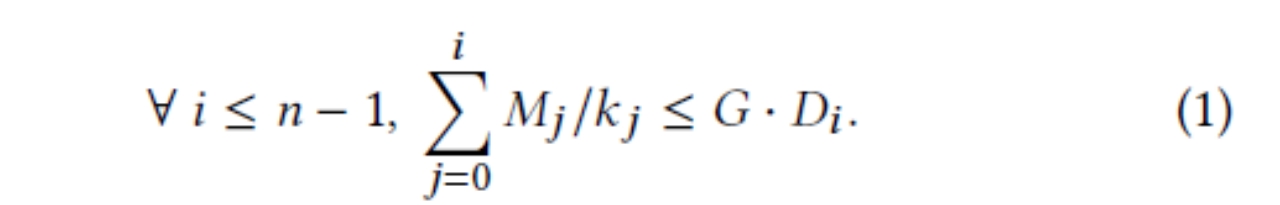 则存在合法的资源分配,可以保证作业能在DDL之前完成。
则存在合法的资源分配,可以保证作业能在DDL之前完成。Resource allocation: 在满足minimum satisfactory share的基础上,将剩余的空闲资源分配给作业,以进一步提高资源利用率。分配时,需要考虑收益递减效益,即:由于GPU的吞吐scaling曲线随GPU数量是非线性的,一个工作拥有的GPU数量越多,其消耗的GPU时间越多。
对于每一个作业,考虑下一个时隙的资源分配情况,优化目标如下式所述:在满足三个约束条件(1.满足所有工作的DDL 2.总分配GPU数目不超过当前可用 GPU 数目 3.在下一个时隙中所有GPU均被分配,除非给任一工作分配更多资源都会导致执行更慢)的情况下, 最小化所有工作的GPU时间之和 。
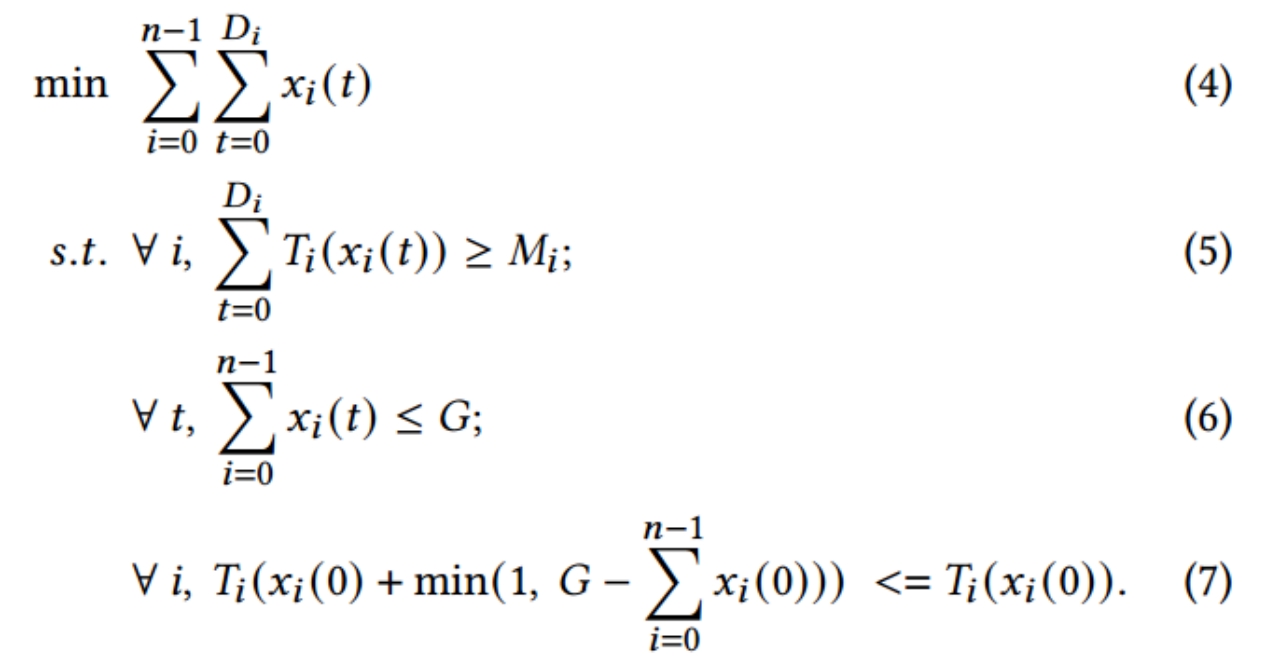
3. 论文提出的新思路、新理论、或新方法
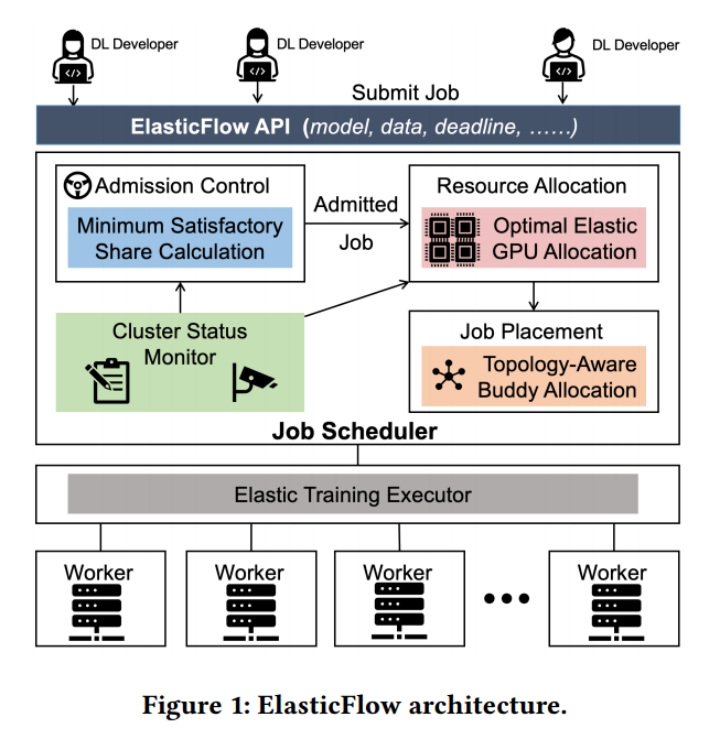
3.1. 架构层面
ElasticFlow只对DL开发者暴露一个高层次的serverless API。DL开发人员将他们的工作作为serverless function提交给ElasticFlow,随后ElasticFlow利用资源弹性,根据作业的截止日期和集群状态动态地为作业分配资源。Serveless function的参数如下:
| 参数名称 | 说明 |
|---|---|
| DNN模型 | 要参与训练的DNN模型 |
| 超参数 | 如Global batch size、学习率等 |
| 终止条件 | 指示工作完成的条件,如最大迭代次数 |
| DDL | DL开发者希望完成训练的时间节点 |
| 其它训练组件 | 数据集、优化器等 |
在serverless API下层加入admission control、resource allocation等组件,对DL开发者屏蔽底层系统资源调度细节。
3.2. 实现层面
Minimum satisfactory share: 提出minimum satisfactory share这一指标,将其定义为:每个作业能满足其DDL所需的最低资源数量,以解决深度学习任务中scaling凹曲线所带来的GPU数量增加收益递减问题。
Admission control: 基于minimum satisfactory share进行准入控制,对提交的任务进行submit或drop操作,保证所有任务都能在DDL前完成。
- 当集群中没有其它任务时,可以通过二分查找来获得满足已有任务DDL需求的最少GPU,从而完成分配。
- 当集群中有其它任务时,考虑某个任务完成DDL所需的GPU需要依赖于其它任务的资源占用情况。而由于DL任务的吞吐scaling曲线是非线性的,本文提出使用 渐进式填充算法(progressive filling) 来判断新任务是否能够被满足。
- 该算法的具体描述如下: 该算法本质上是一个贪心算法,对于每次需要调度任务时,先将新添加的任务添加到任务队列中并按照DDL升序排序,随后按顺序逐个从任务队列中取出任务并调用渐进式填充算法。对每一个任务,渐进地增加GPU分配数量,并计算每个时隙下的工作量,对工作量求和,判断总工作量是否满足任务所需工作量。如果在系统已有GPU资源范围内,找不到一种调度策略满足任务在DDL前完成工作,则丢弃(drop)该工作;否则,提交(submit)该工作。

- Resource allocation: 目标是在满足minimum satisfactory share的基础上,将剩余的空闲资源分配给作业,充分利用GPU,同时保证所有已提交任务的DDL。
- 本文为资源分配开发了一个贪心算法,将剩余的GPU分配给具有最高边际效益的任务。
- 该算法的具体描述如下: 在保证分配给任务新GPU不会导致任务完成时间变长以及minimum satisfactory share的基础上,对任务逐个分配 GPU,计算任务分配GPU后的效益,并以此确定任务的优先级添加至优先队列中。随后在队列中的任务依次出队,实际分配GPU时每次分配给边际效益最高的任务,直到所有GPU被分配完。

- Job placement: 目标是尽量减少任务拓扑位置(worker placement)对DL任务效益的影响。本文提出了两个具体策略来实现上述目标:
- 开发了一种 topology - aware的工作分配算法 :使用多层分层树来获取GPU拓扑,树的叶节点代表GPU,每个内部结点代表某种连接。为了放置作业,每次找到一个合适的子树,其中包含足够的GPU来容纳作业。而寻找合适子树的方法是 Best - Fit ,每次选择空闲GPU数量最接近所需GPU数量的子树,使得作业尽可能分配导同一拓扑的集群中,分配尽可能高的带宽,避免吞吐的低估和资源用量的高估。
- 使用 buddy allocation和job migration 来消除resource fragmentation,通过buddy allocation和job migration来消除资源碎片。并将每个工作的worker数量限定为2的幂次,如此能保证如果集群中有足够的空闲GPU用于某个作业,则存在包含足够GPU的子树。
4. 论文方法的理论分析或实验评估方法与效果
4.1. 评估方法
本文在16台服务器的集群上进行测试,其共包含128个NVIDIA A100 GPU。每台服务器配备8个40GB NVIDIA A100 GPU、96核、900GB RAM和8个NVIDIA Mellanox HDR InfiniBand HCAs。
本文在A100 GPU上开发了用于模拟作业级事件的模拟器,通过测试台的物理GPU服务器作为模拟器的输入,对每个作业的吞吐量展开分析
对于每个作业,本文随机选择一个具有batch size的DNN模型,使用跟踪中的持续事件和预先测量的吞吐量来计算每个作业所需的迭代次数。
本文主要对以下 2个指标 进行评估:
Deadline satisfactory ratio,即作业在截止日期前完成的比例。
Cluster efficiency(CE),它衡量集群中资源的利用效率,具体数学定义如下(其中M是集群中GPU数量,tpt是吞吐量):
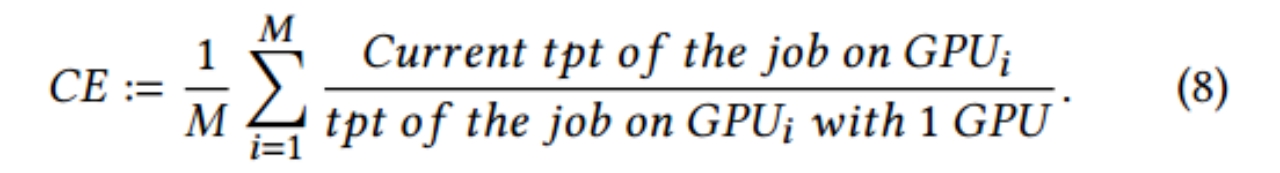
对于SLO作业,使用上述两个指标;对于best-effort作业,主要比较其JCT(作业完成时间)
4.2. 效果
本文选取了6个baseline进行比较,分别是:
- Earliest-Deadline-First (EDF)
- Gandiva
- Tiresias
- Themis
- Chronus
- Pollux(STOA)
与EDF、Gandiva、Tiresias、Themis、Chronus和Pollux相比,ElasticFlow将能够满足截止日期的作业数量分别提高了8.0倍、2.7倍、2.0倍、2.3倍、1.6倍和2.0倍。在更大的规模上(在16台服务器上,128个GPU),与EDF、Gandiva、Tiresias、Themis和Chronus相比,ElasticFlow能够满足截止日期的作业数量分别提高了7.65倍、3.17倍、1.46倍、1.71倍和1.62倍。平均而言,与EDF、Gandiva、Tiresias、Themis和Chronus相比,ElasticFlow将截止日期满意率分别提高到12.95倍、2.58倍、2.15倍、1.76倍和1.68倍。
5. 总结
5.1. 论文优点
- 敏锐察觉到现有分布式DL训练平台的痛点,能够有效结合STOA和现有大部分方法优点,提出了一个serverless架构的弹性计算平台ElasticFlow,大大简化DL开发人员们的使用过程,并能为DL任务提供DDL前完成的性能保证。
- 考虑到了分布式训练中的两个挑战:训练吞吐随GPU数量非线性增长以及Worker placement对scaling的影响。同时考虑到了两个问题之间的相互影响,能够从现实情景出发,设计admission control、resource allocation、job placement等方法解决上述挑战。
- 本文所提出的ElasticFlow还考虑了SLO和best-effort两种作业的调度情况,对于两种不同类型的作业保持了兼容和可扩展性。
- 实验对比验证环境使用了严谨的指标,选取当下主流方法作为baseline,测试数据可信度高,结果令人欣喜。
- 本文还对ElasticFlow的系统开销如profiling以及Scaling和migration进行了测试,得出在一般真实场景下,ElasticFlow的系统开销较小,相比于DL任务的训练时长几乎可以忽略不计。
5.2. 论文缺点
- 在serverless架构的ElasticFlow平台中未对GPU加速话题进行探究。
- 对于有恶意的用户(即恶意提交DL任务、挤兑系统资源等),本文未提出详细的额外策略和定价模型来防止此类情况发生。即:本文假定所有用户都是无恶意的,并根据他们的实际需求来按需设定DDL。
- 对于集群中结点发生错误的情况,本文未设计详细策略。
5.3. 本文的启示
Serverless架构可以对计算平台使用者屏蔽底层资源配置等系统方面知识,从而将专业使用(如DL业务知识)与底层系统解耦,让开发者专注于完成自己的开发任务。
分布式计算集群中需要设定弹性资源分配策略,以保证时刻最优工作效率。
实际算法设计中需要考虑现实中训练吞吐随GPU数量非线性增长以及Worker placement对scaling的影响,而不是用理想的线性模型进行概括。实际的集群worker分配时需要考虑到topology-aware。
5.4. 后续研究思路
探究serverless架构下的加速器设计,如对GPU加速以支持更高的workload。
对于有恶意的用户(即恶意提交DL任务、挤兑系统资源等),设计详细的额外策略和定价模型来防止此类情况发生。
设计容错策略,处理集群中结点发生故障的情况,保证集群的高可用。