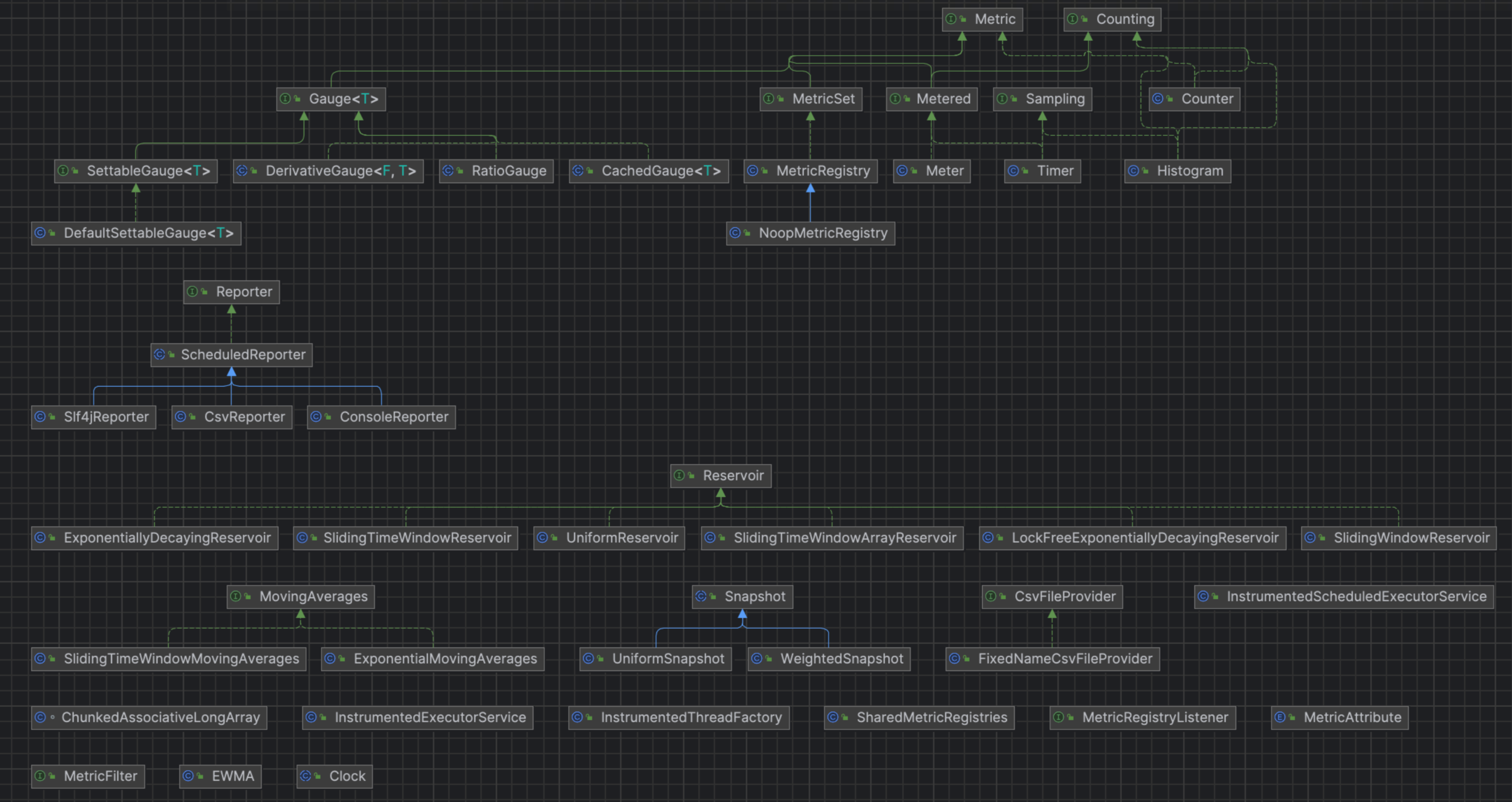
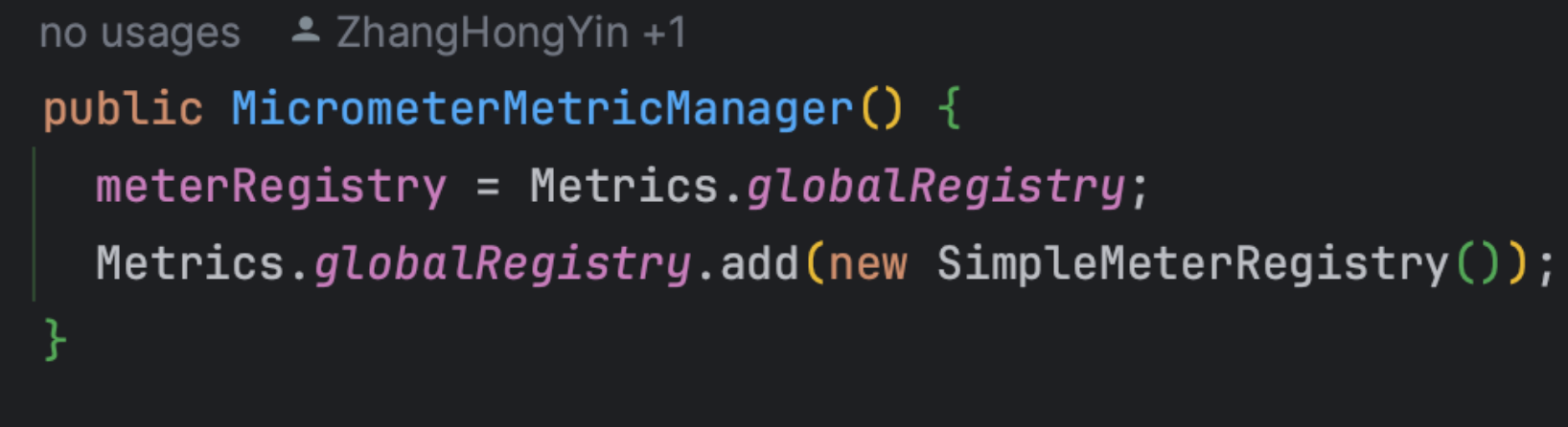
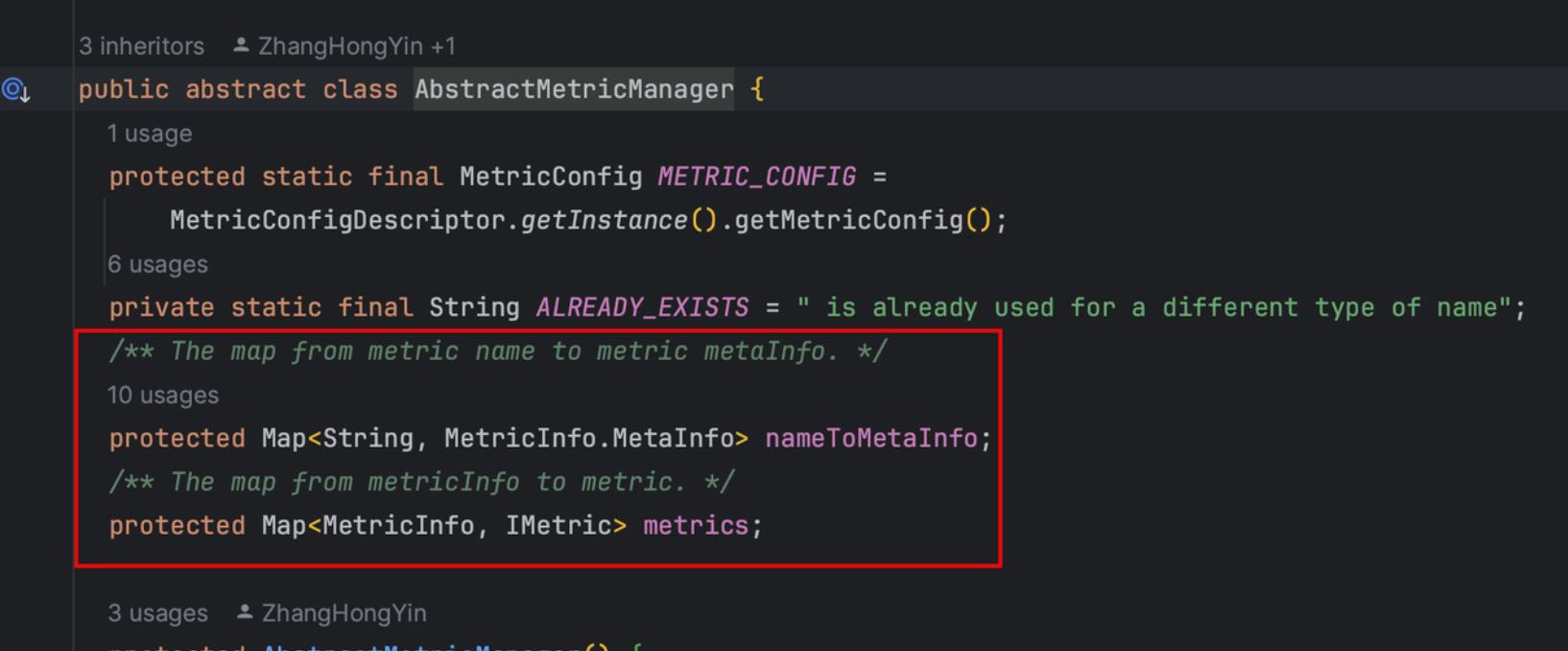
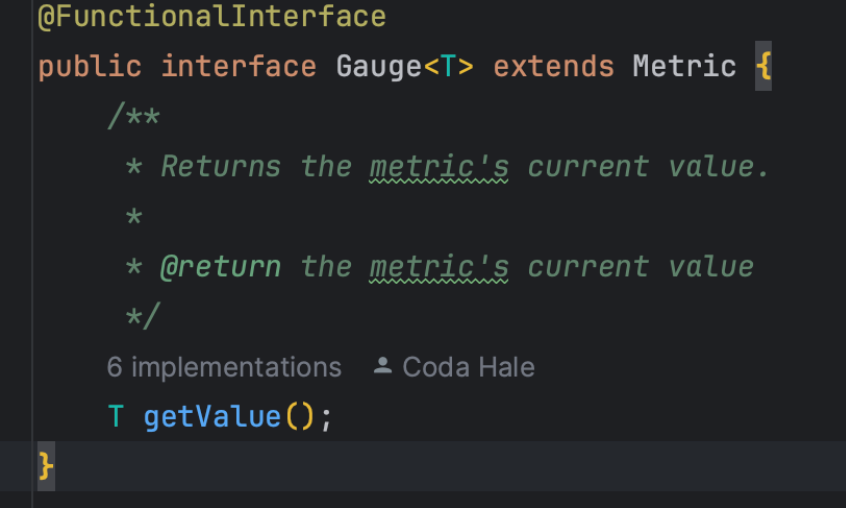
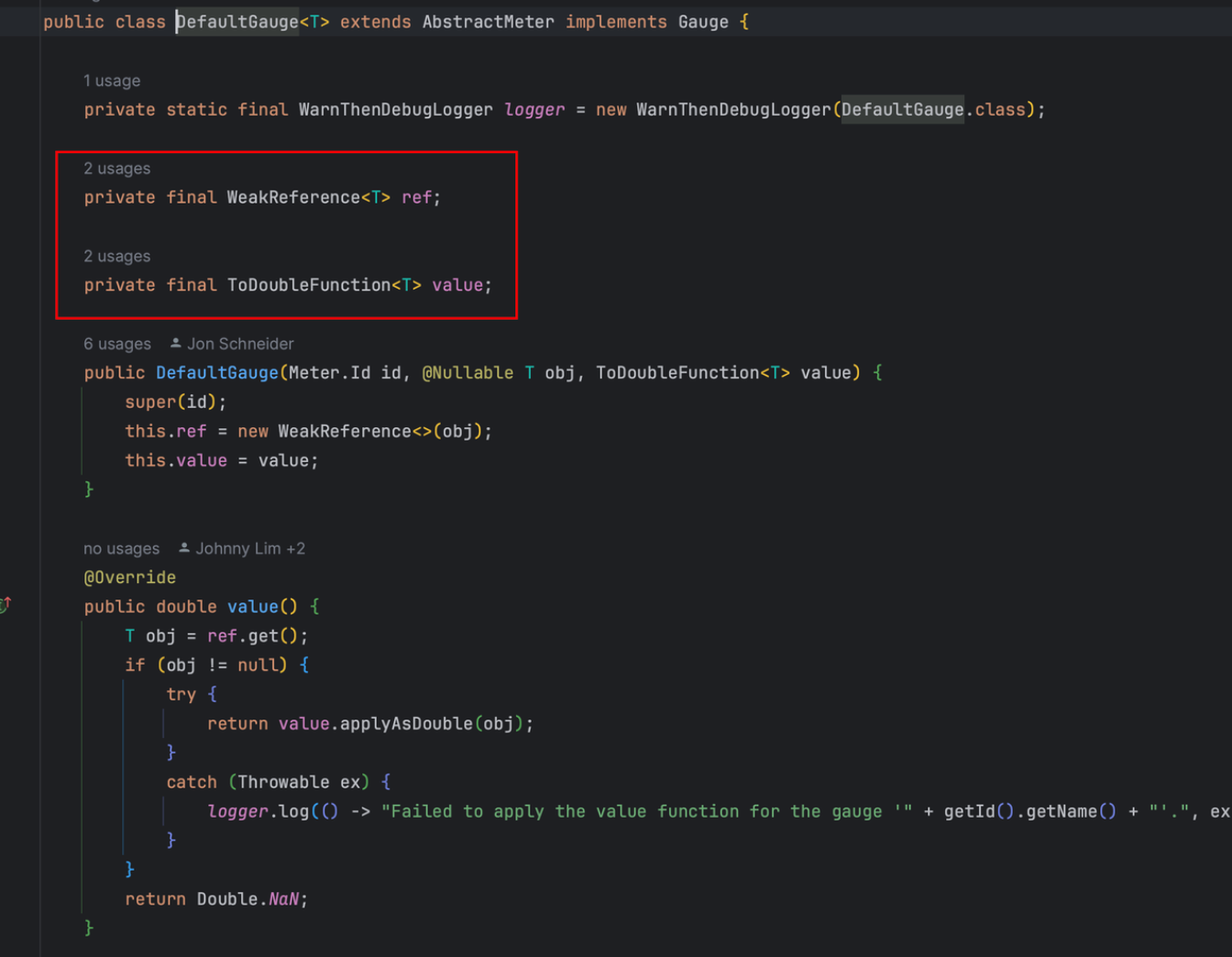
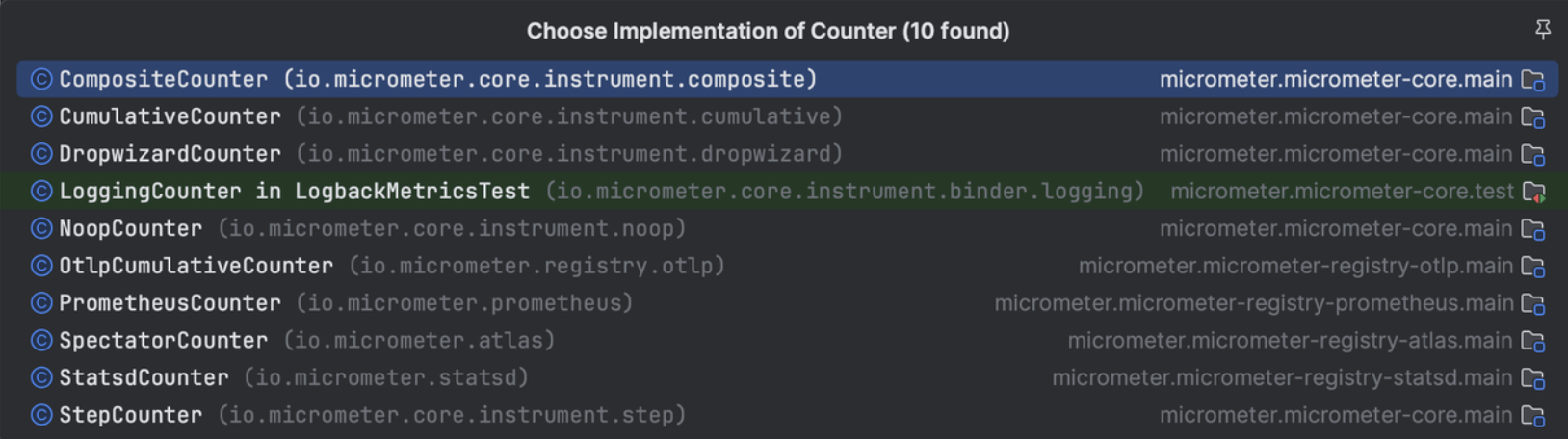
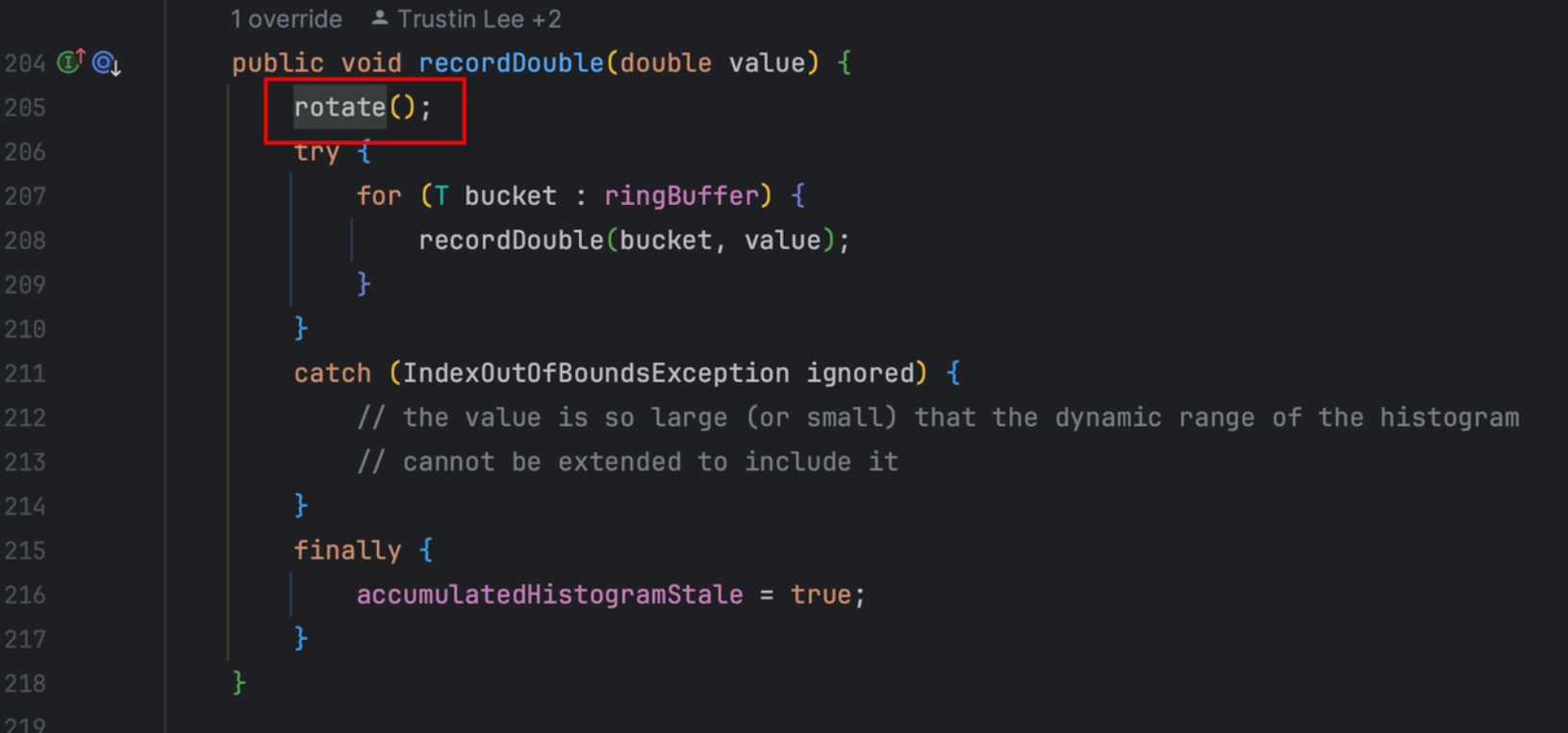
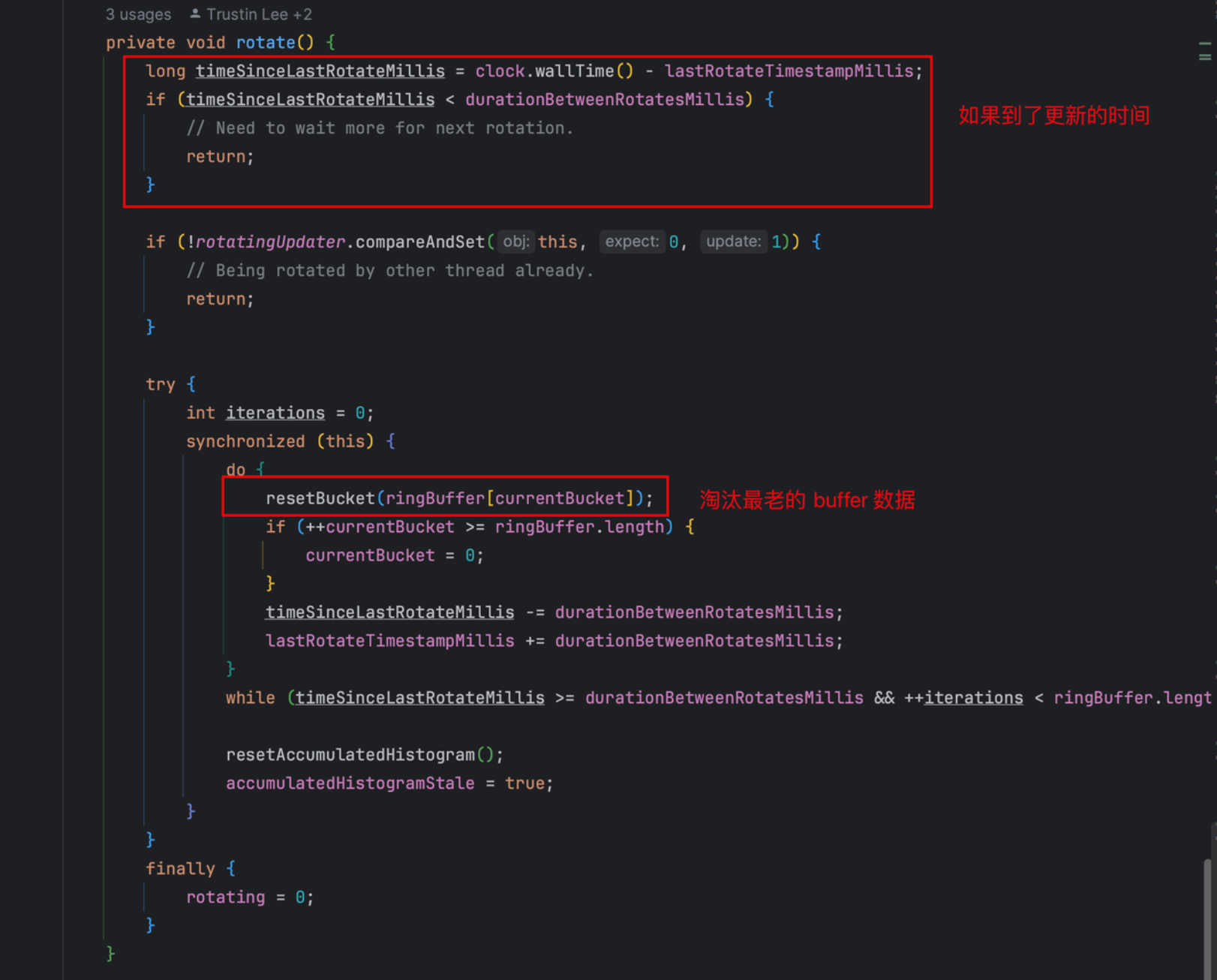
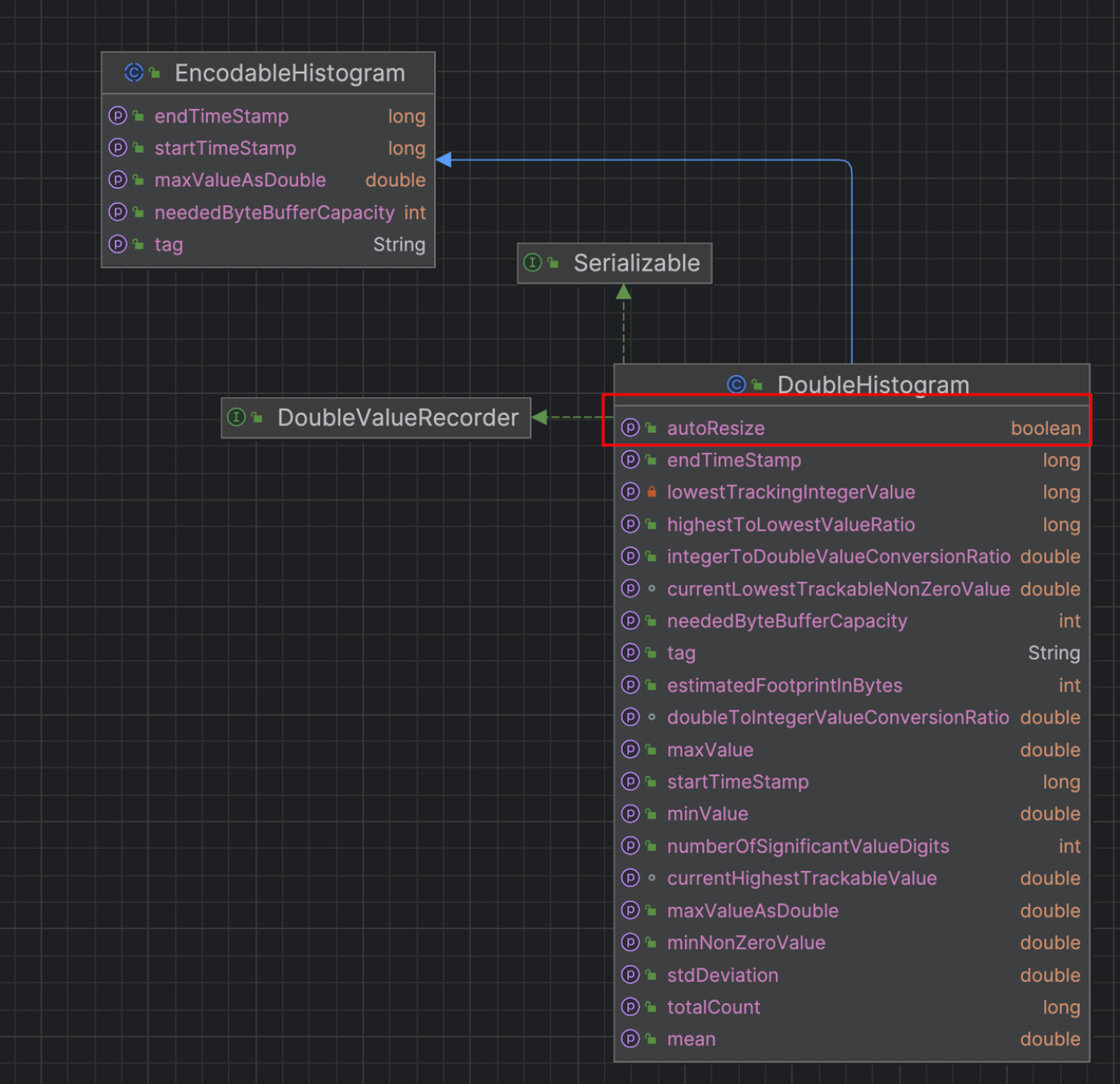
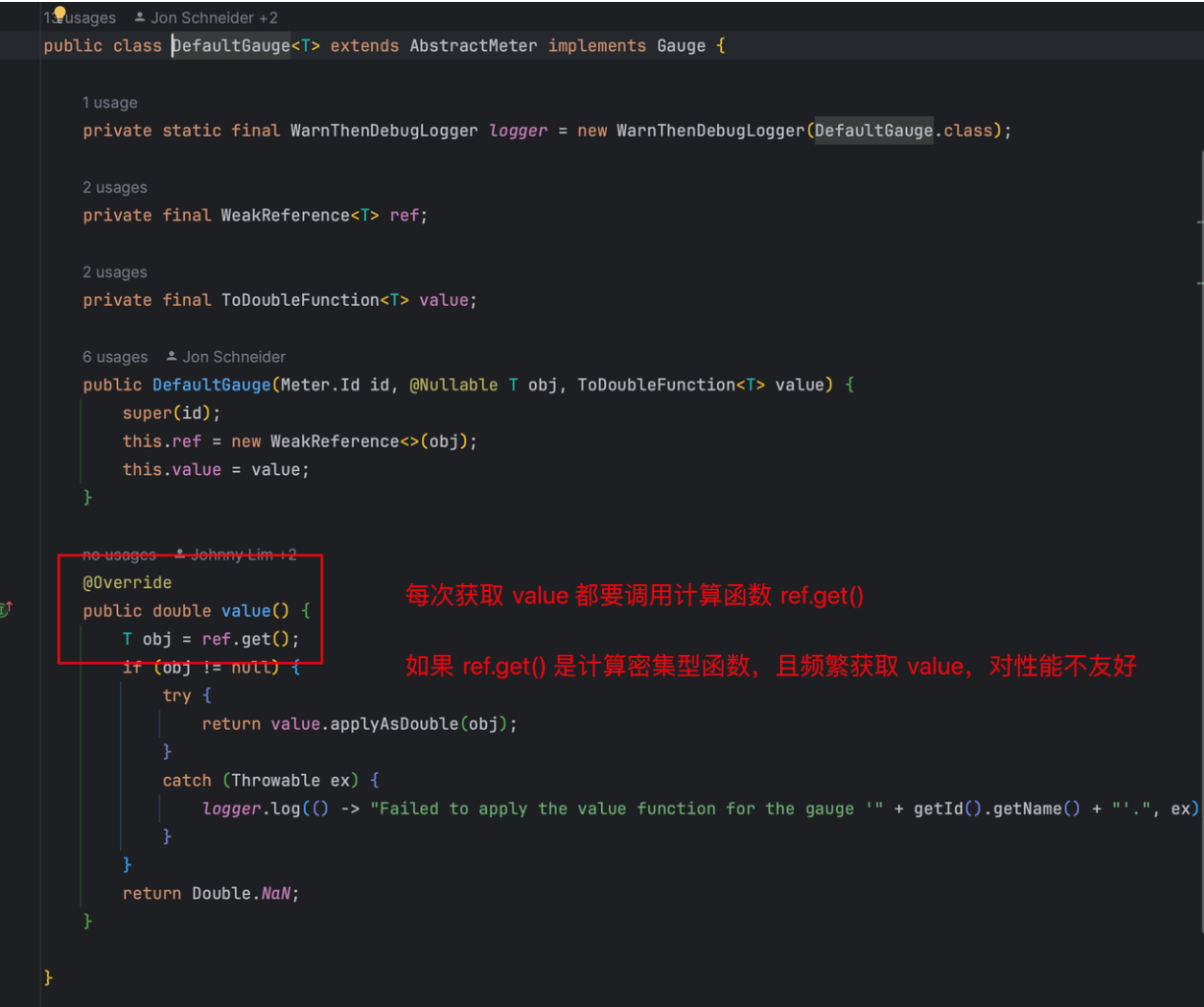
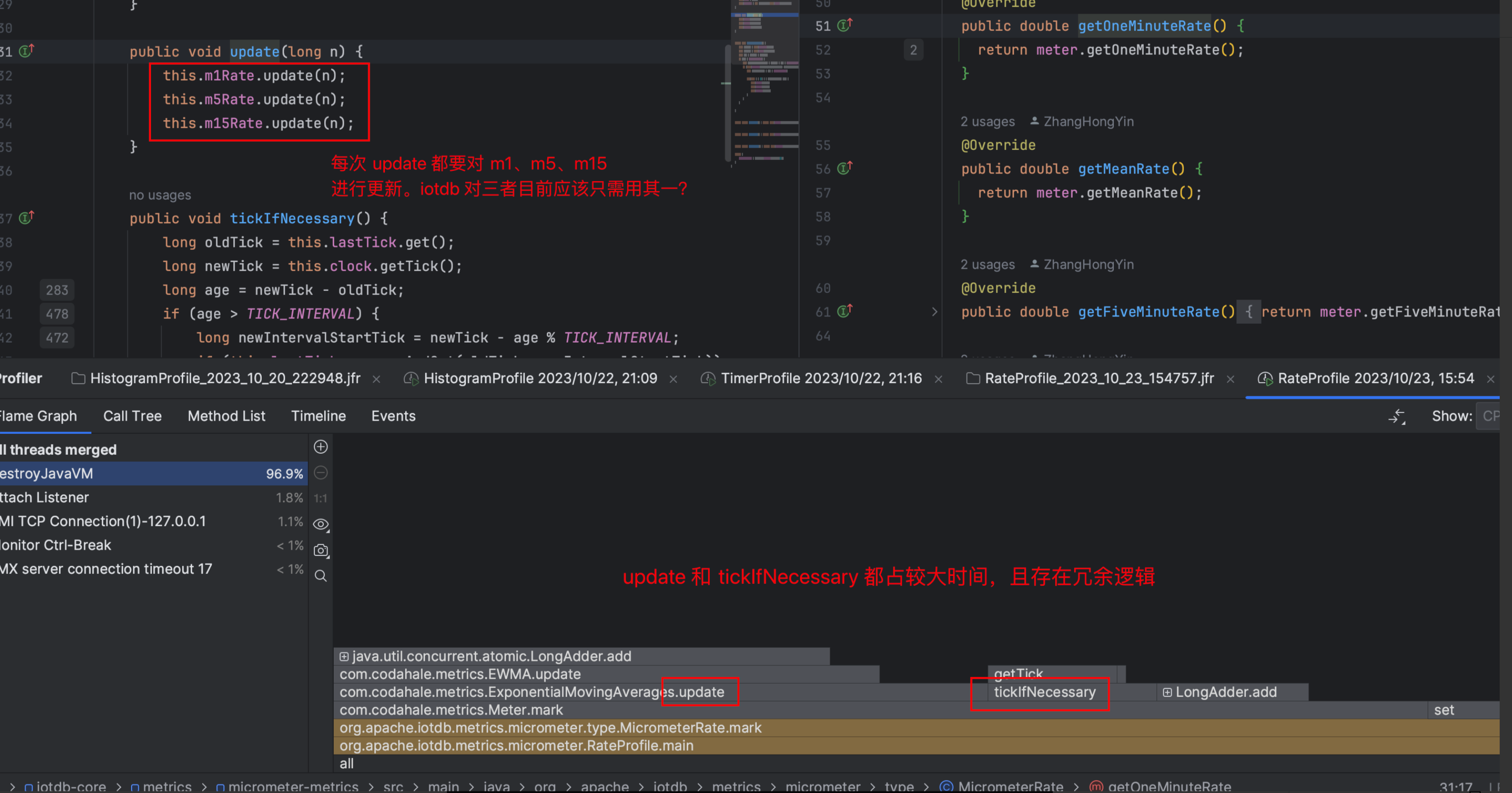
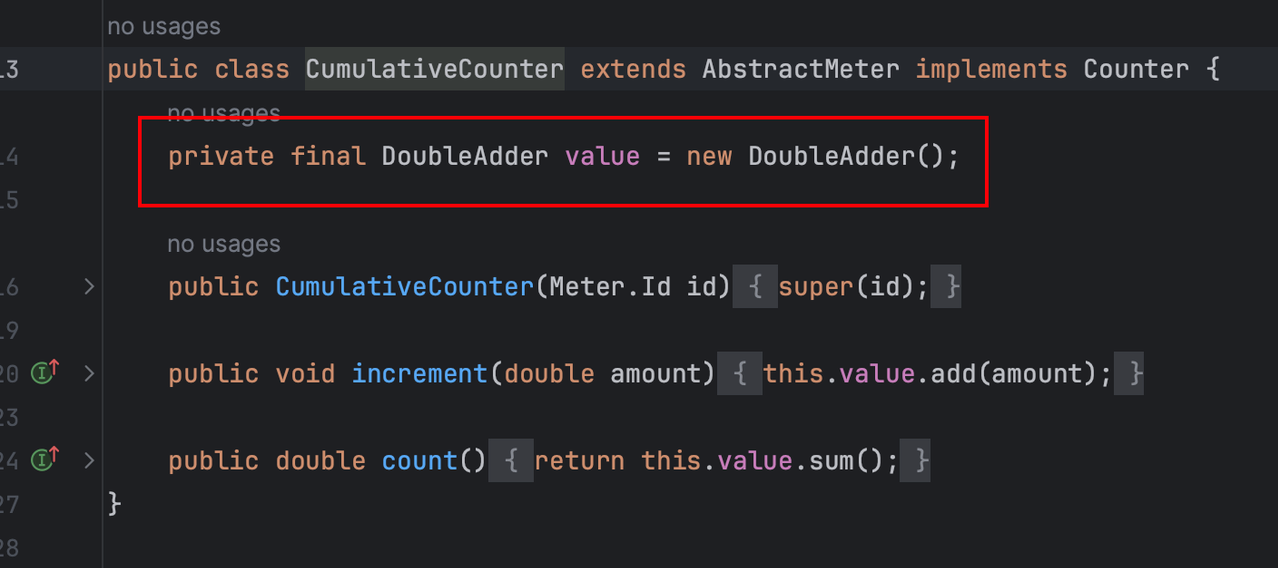
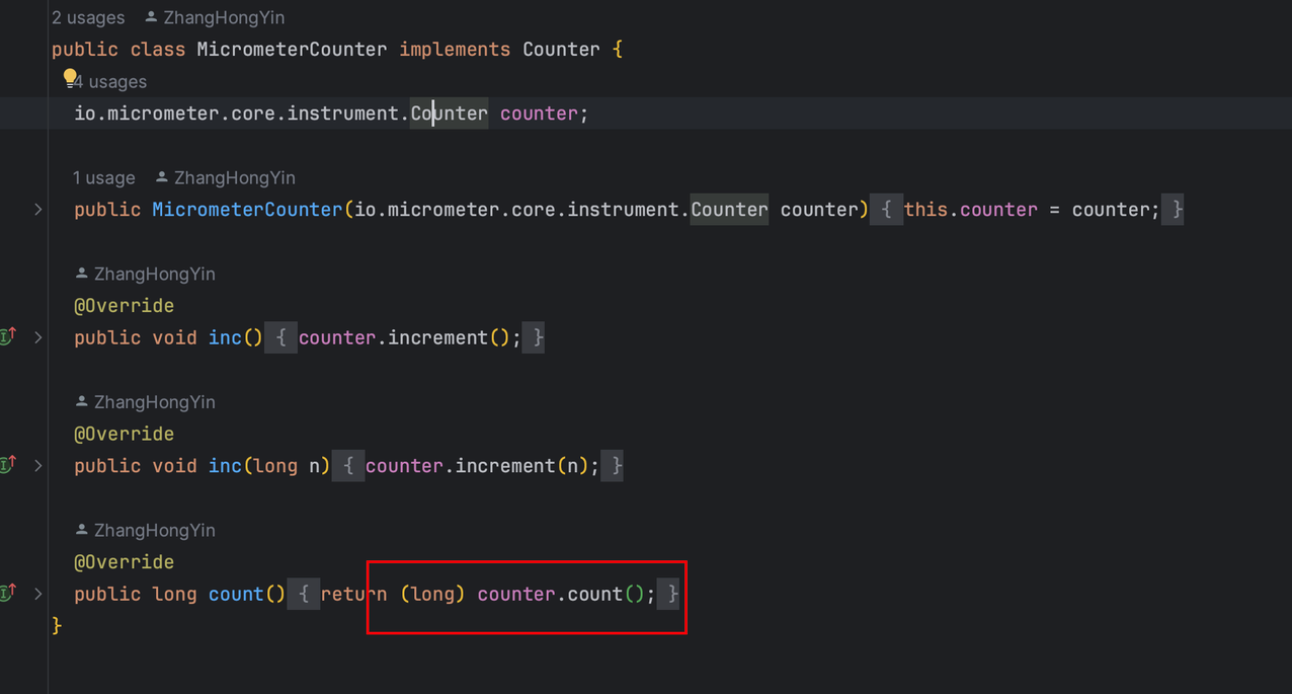
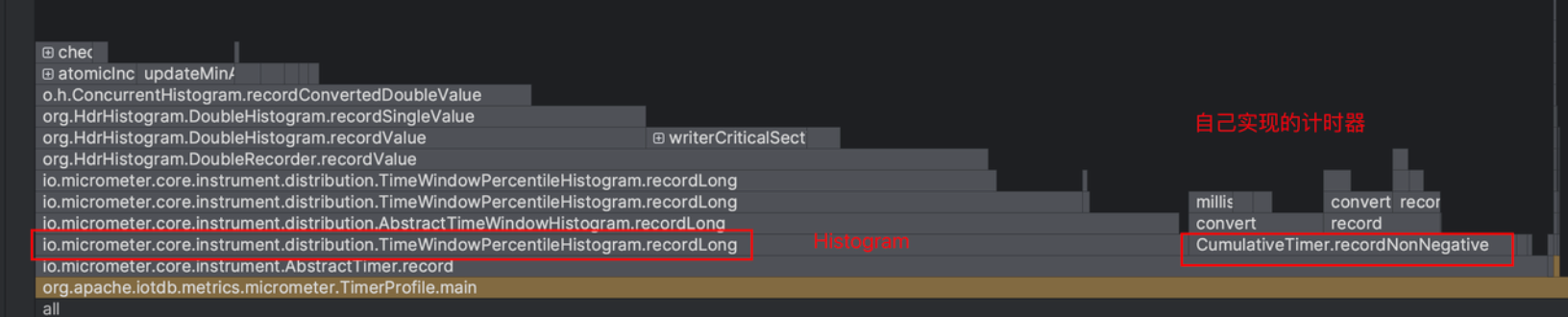
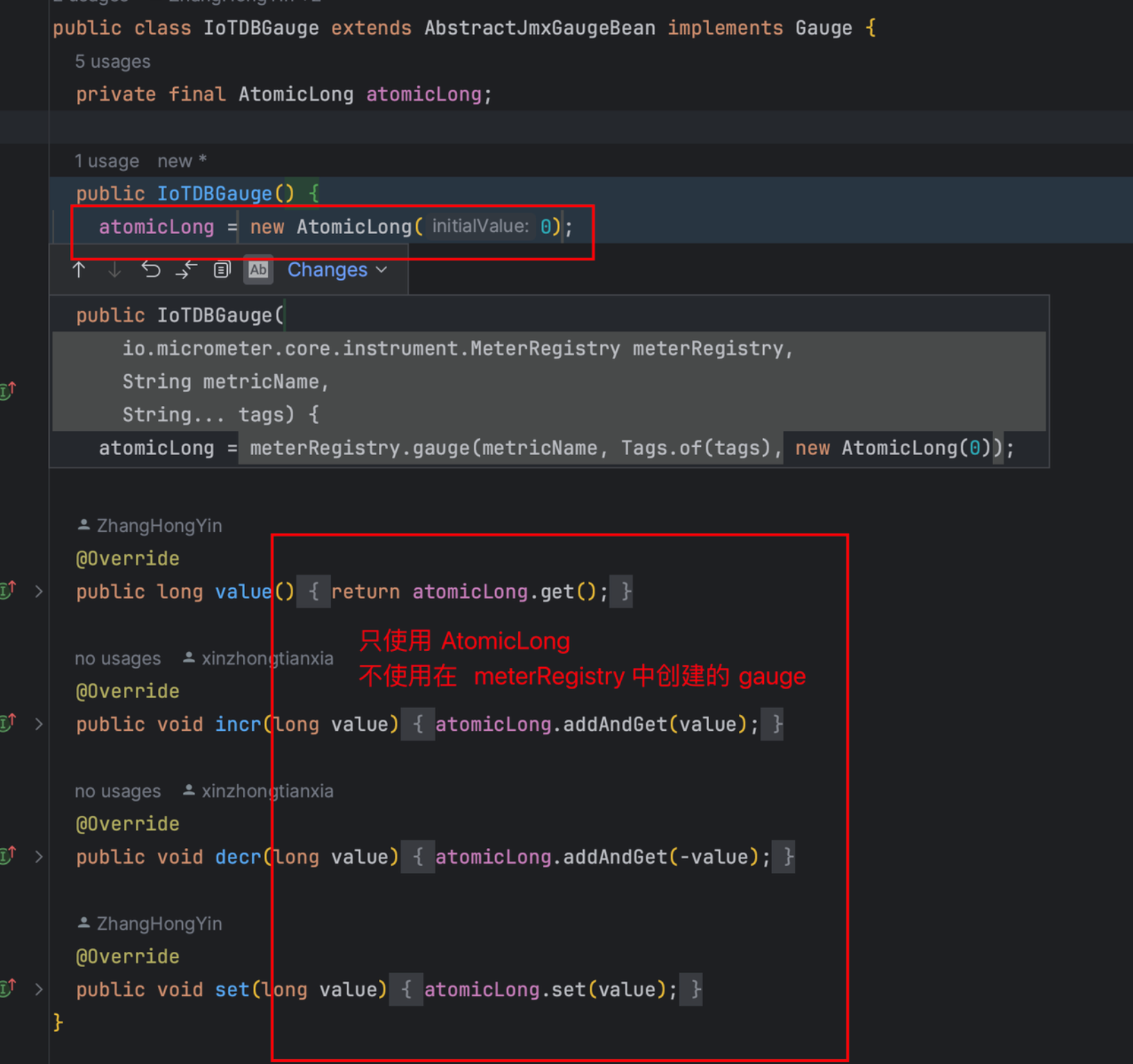
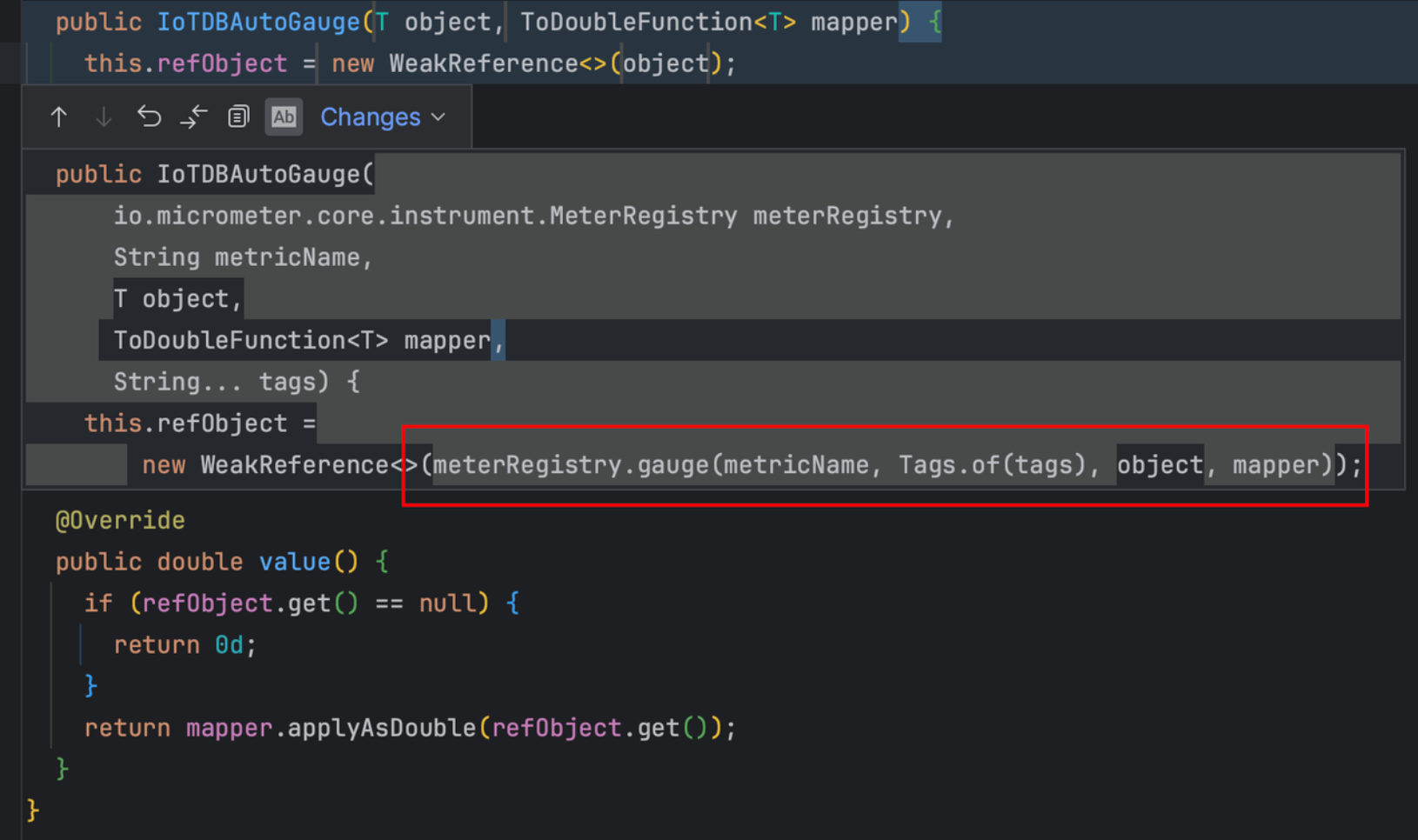
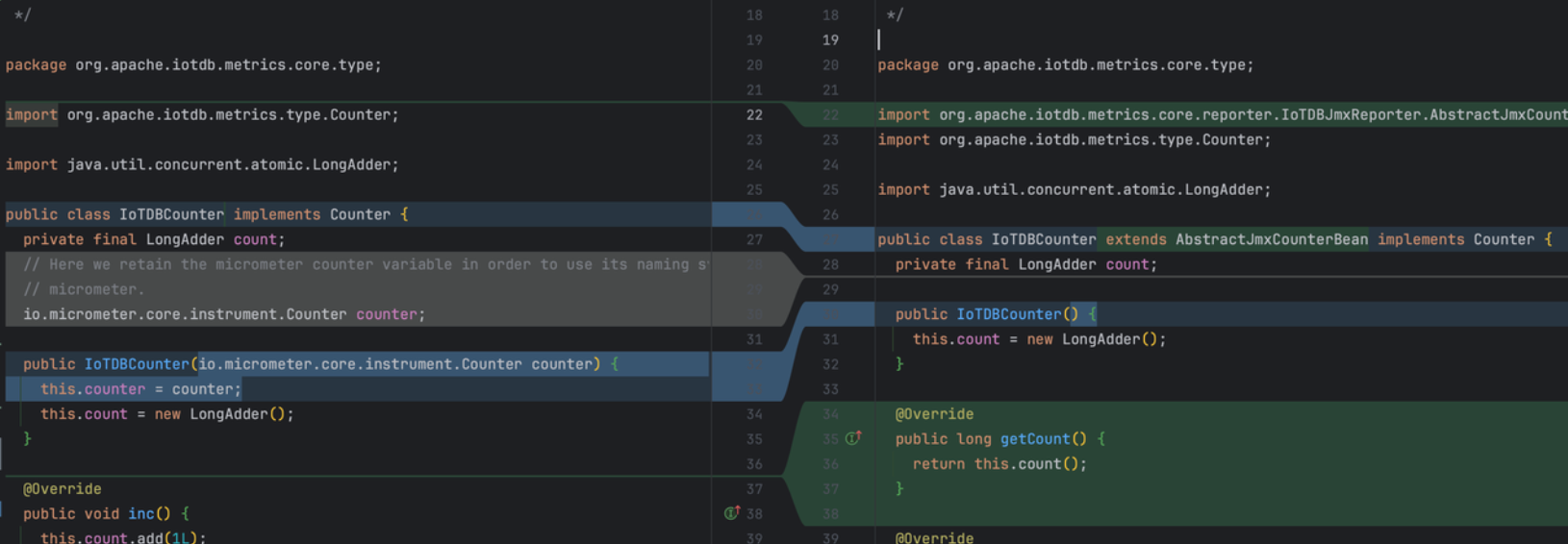
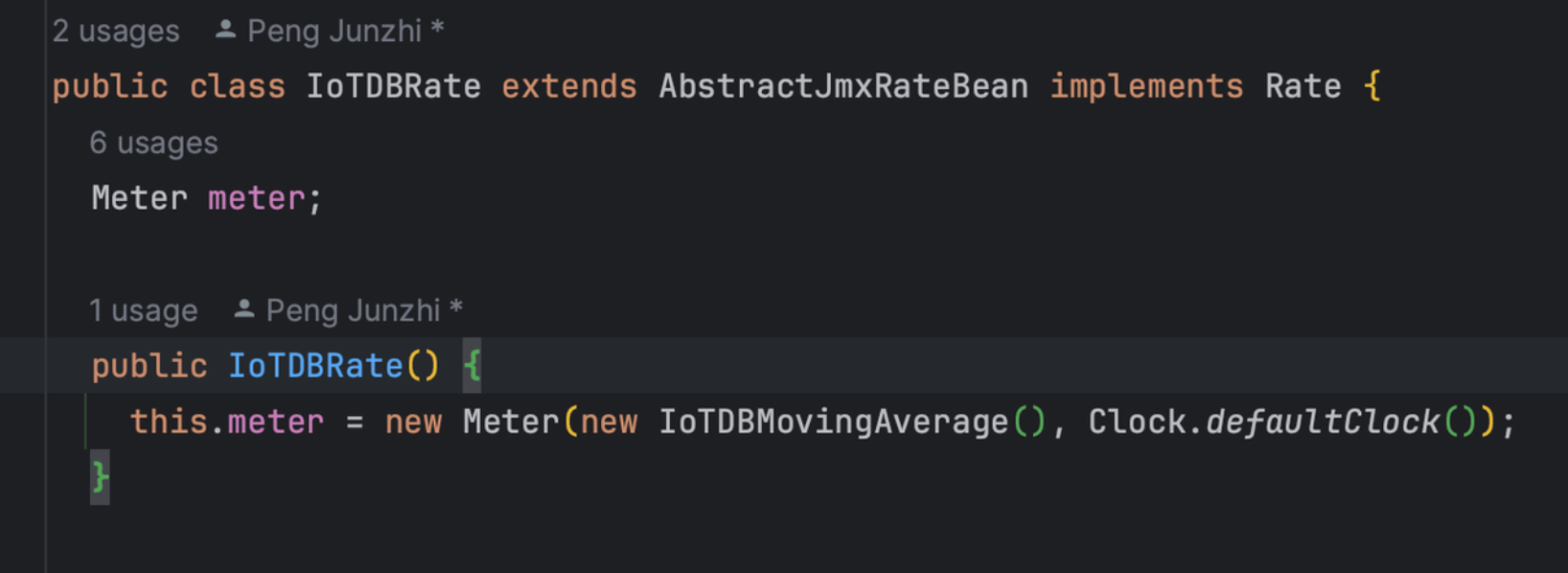
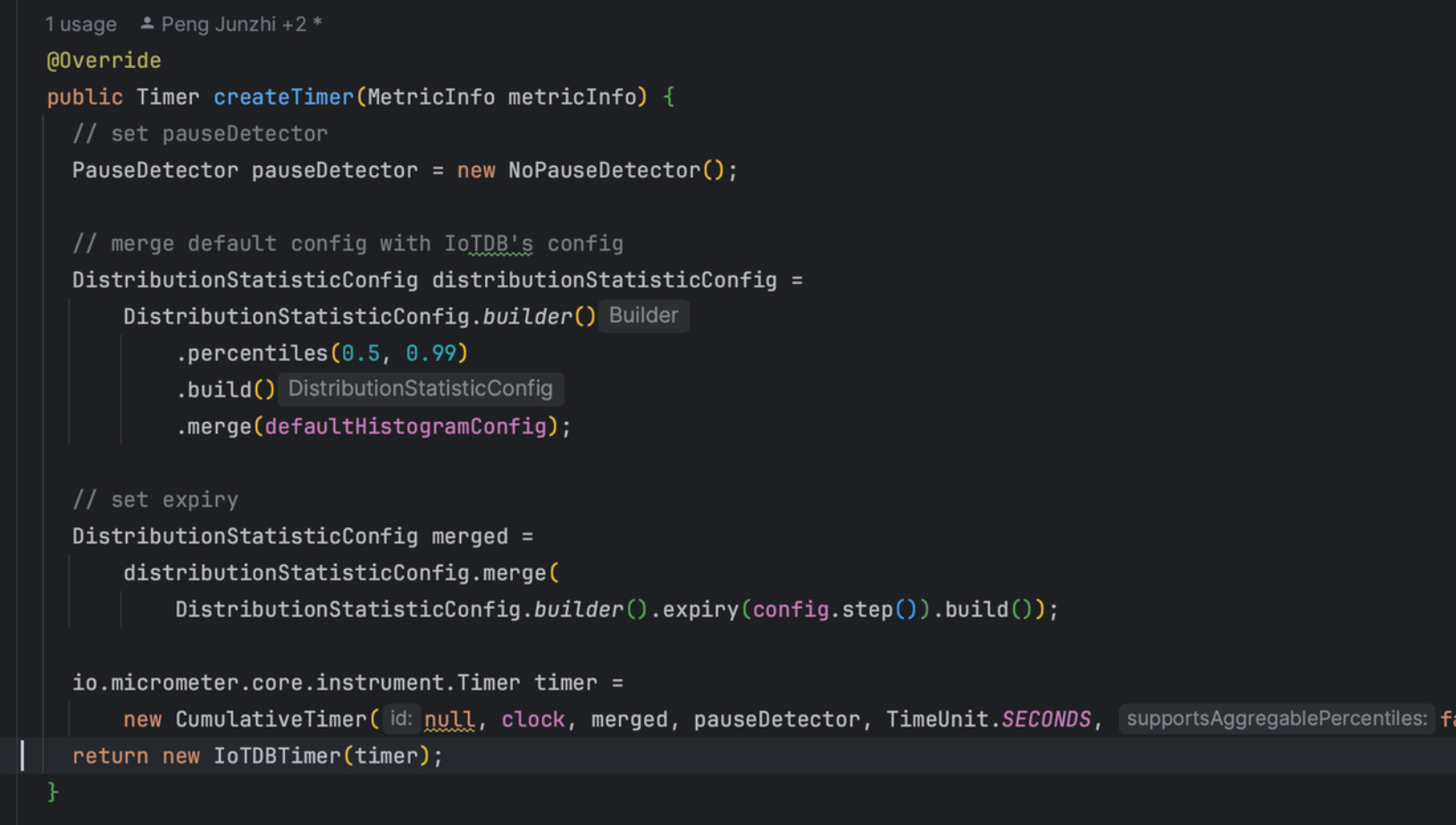
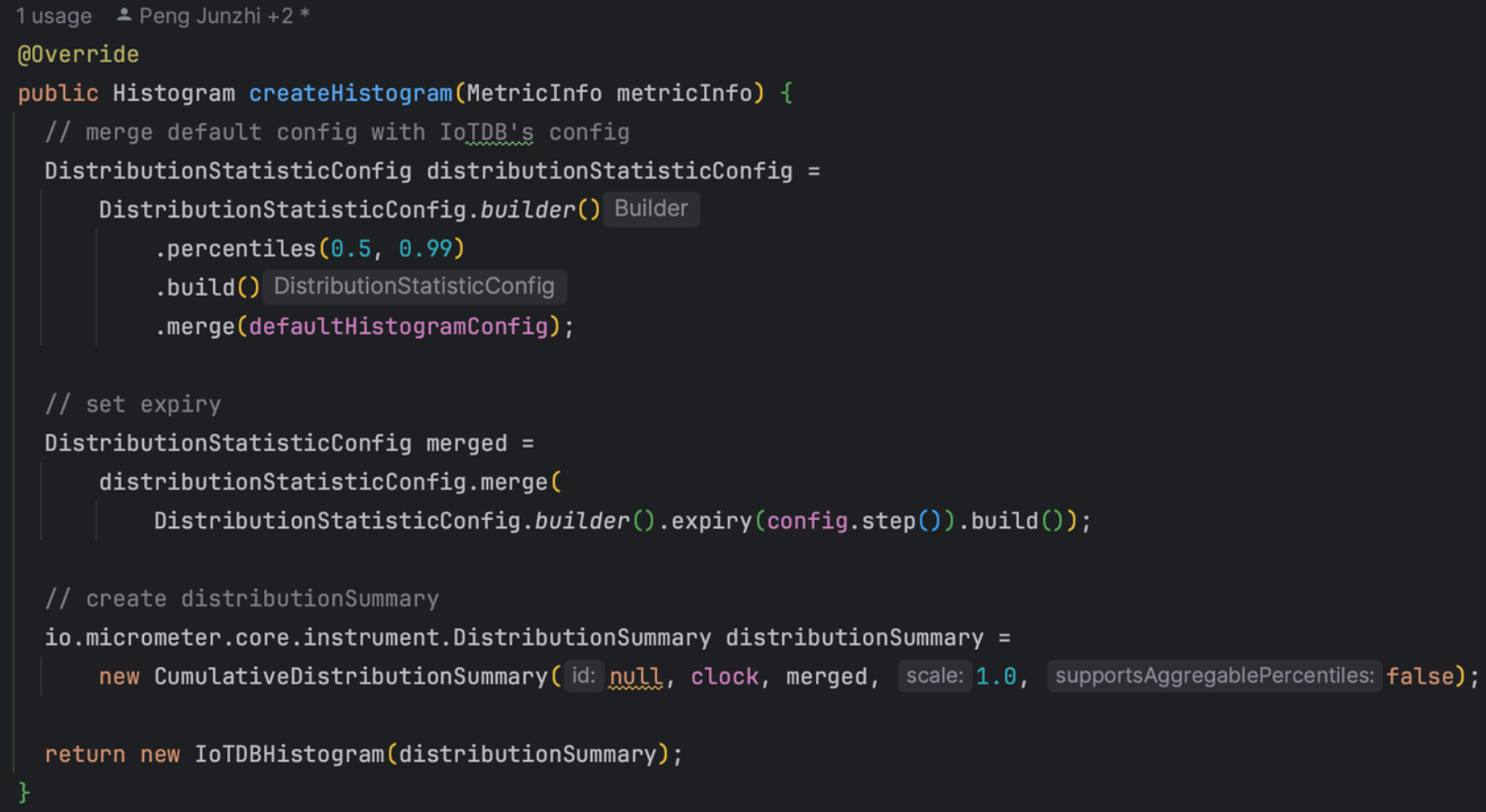
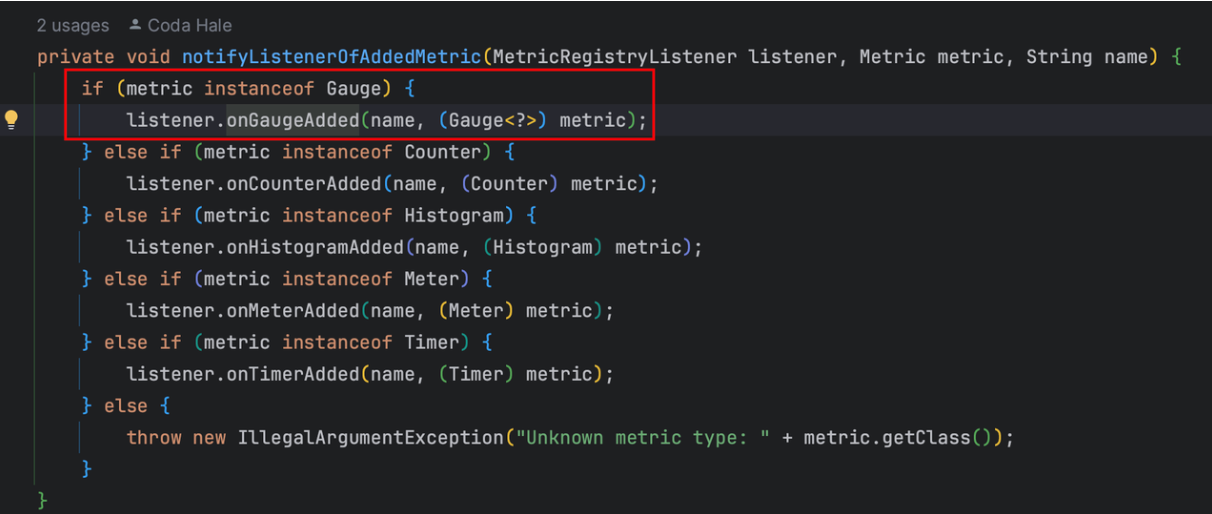
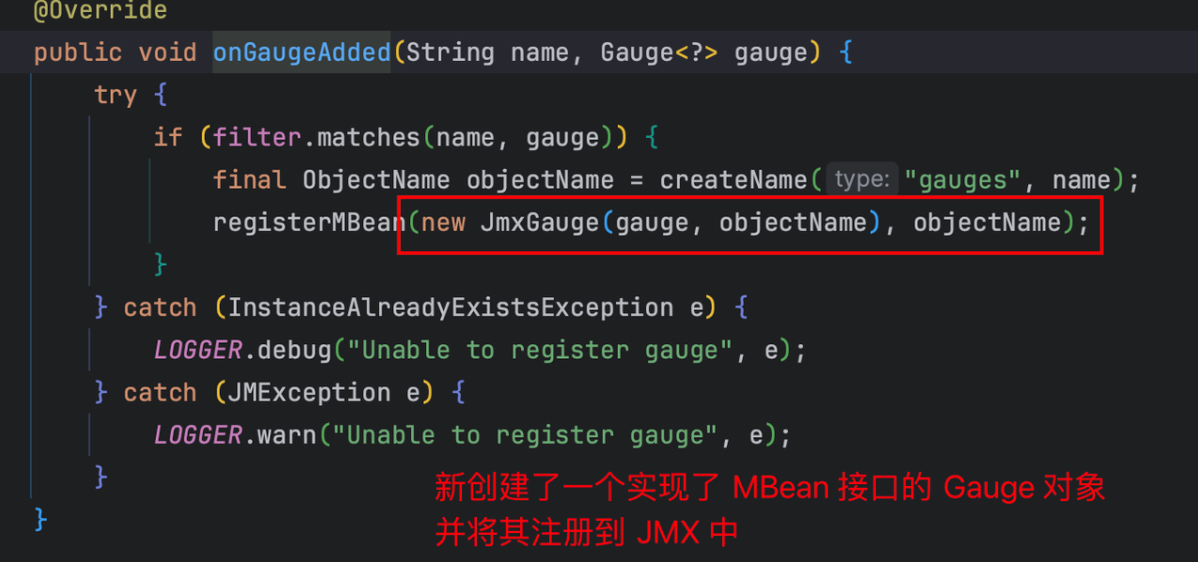
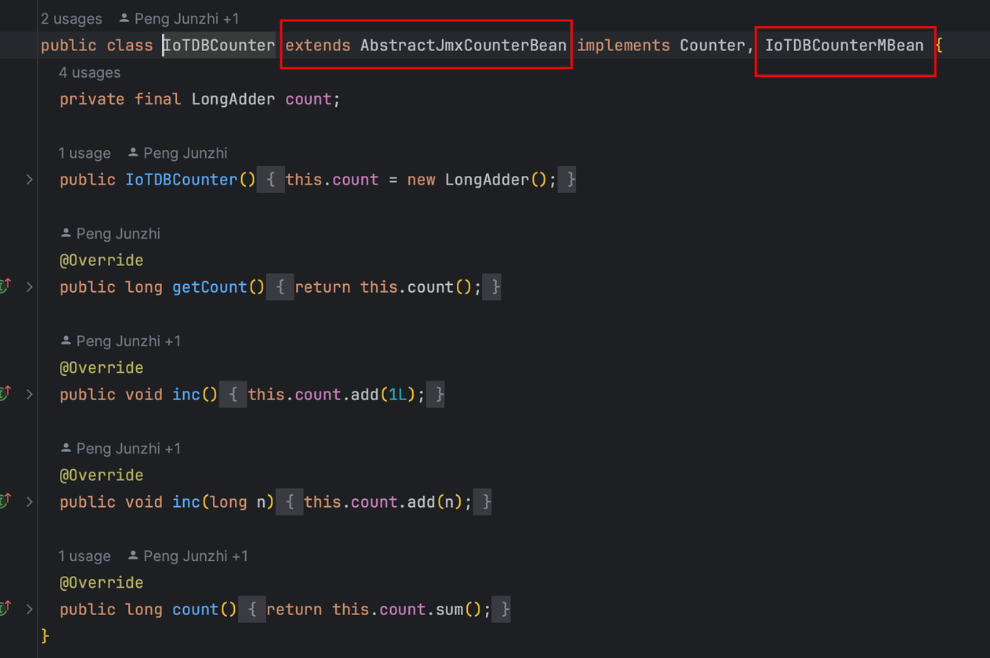
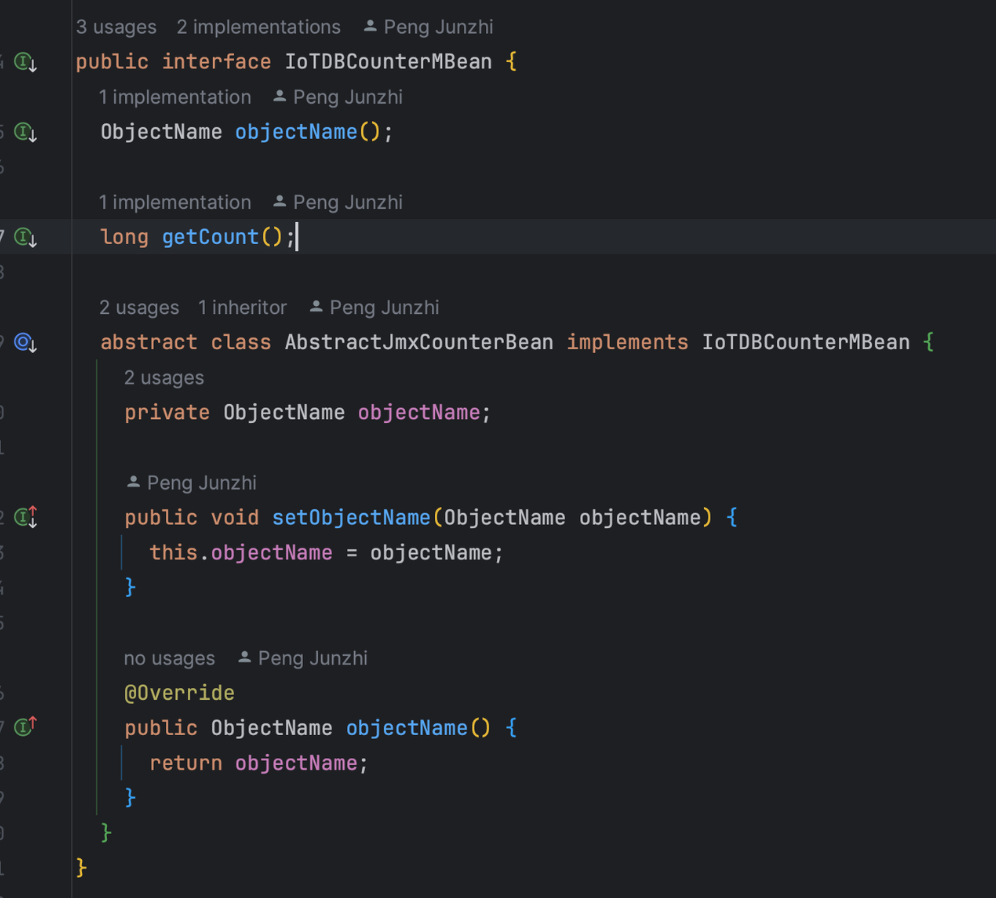
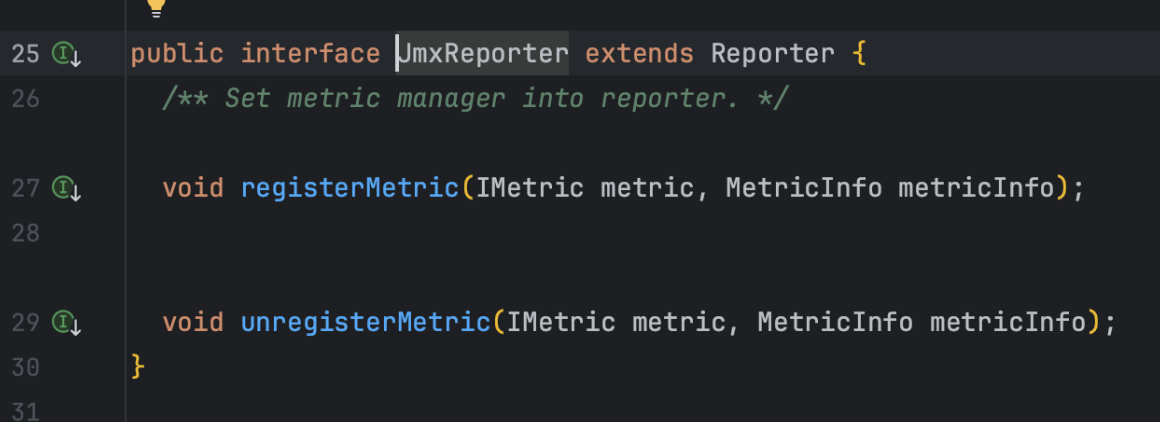
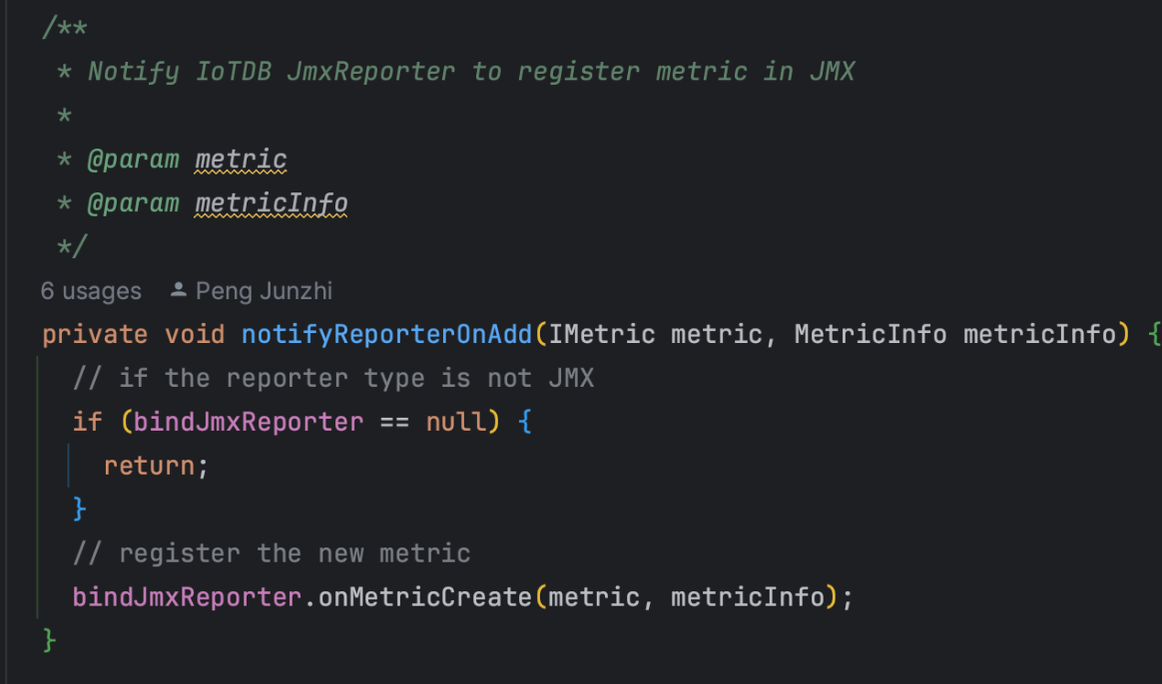
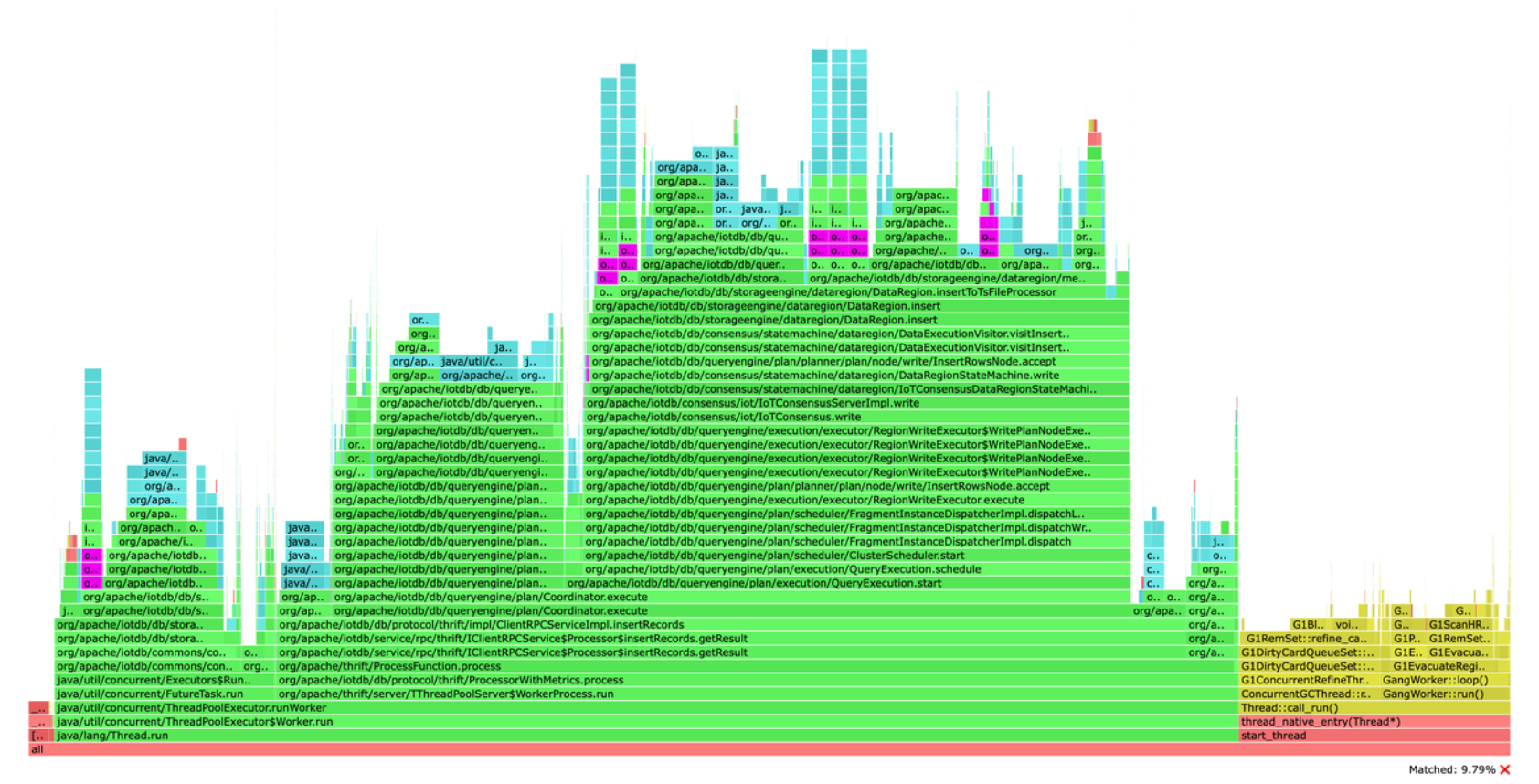
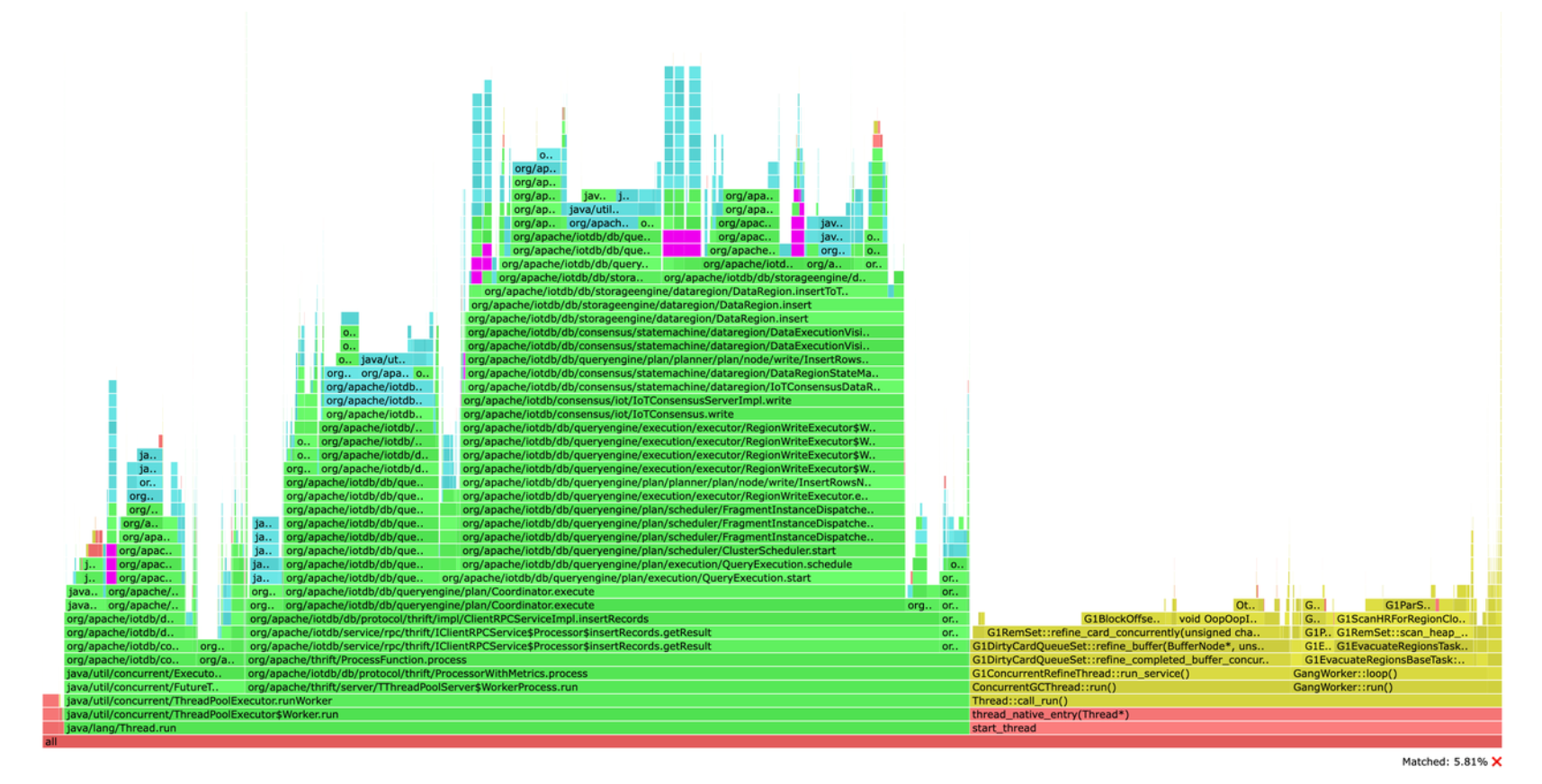
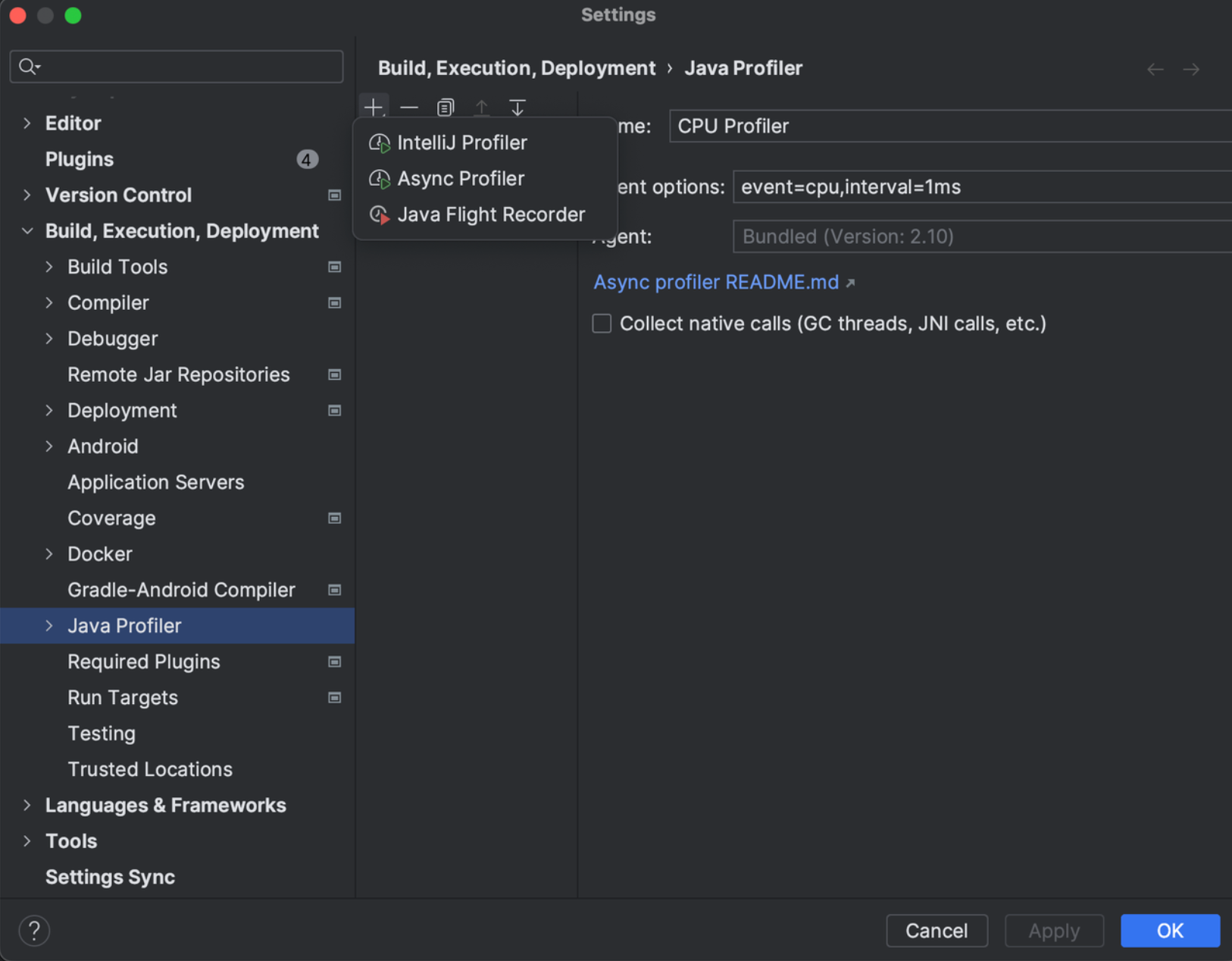
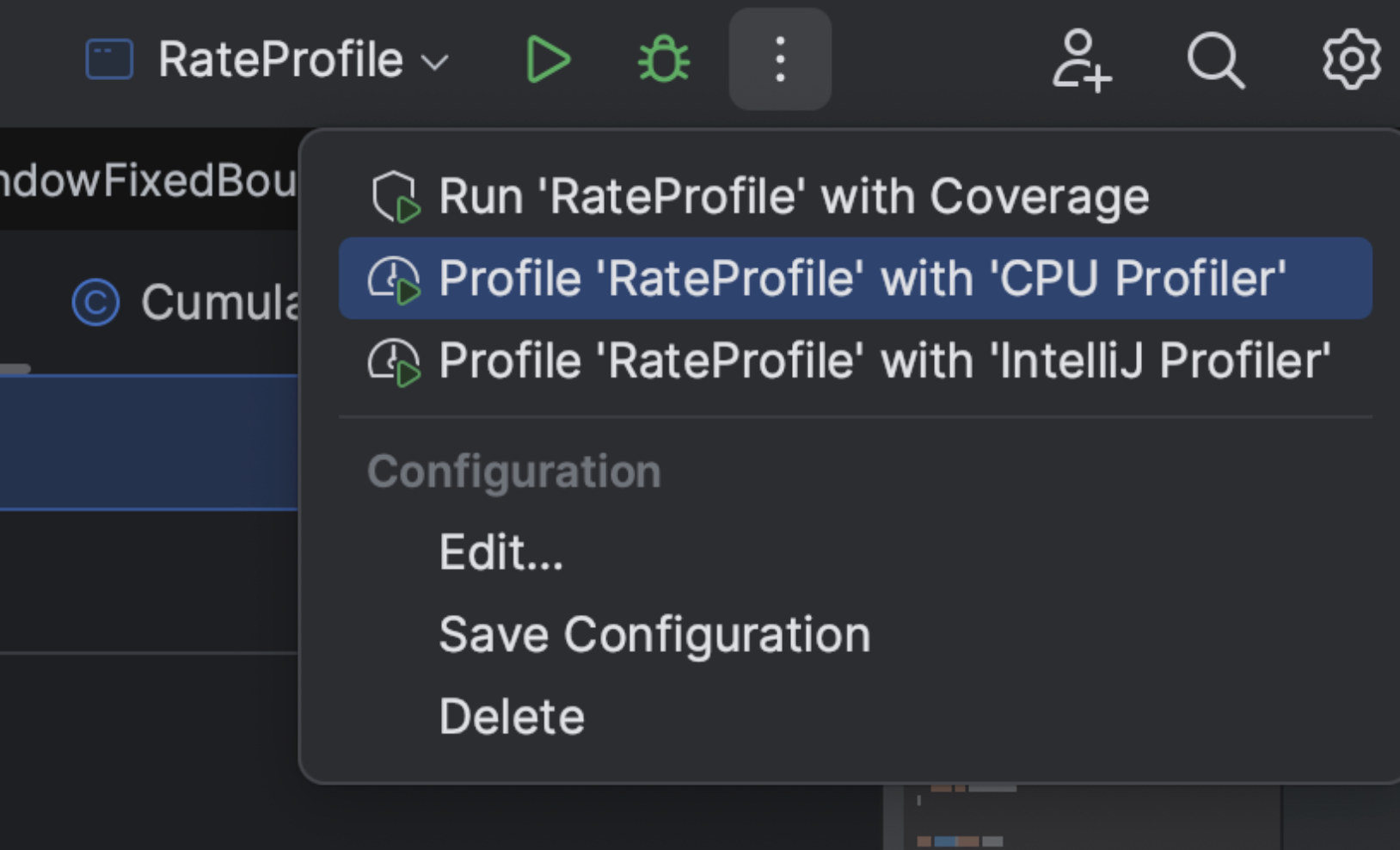
Micrometer提供了与供应商无关的接口,包括 timers(计时器), gauges(量规), counters(计数器), distribution summaries(分布式摘要), long task timers(长任务定时器)。它具有维度数据模型,当与维度监视系统结合使用时,可以高效地访问特定的命名度量,并能够跨维度深入研究。
/** * Adds an old value with a fixed timestamp to the reservoir. * * @param value the value to be added * @param timestamp the epoch timestamp of {@code value} in seconds */ publicvoidupdate(long value, long timestamp) { rescaleIfNeeded(); lockForRegularUsage(); try { finaldoubleitemWeight= weight(timestamp - startTime); finalWeightedSamplesample=newWeightedSample(value, itemWeight); finaldoublepriority= itemWeight / ThreadLocalRandom.current().nextDouble();
finallongnewCount= count.incrementAndGet(); if (newCount <= size || values.isEmpty()) { values.put(priority, sample); } else { Doublefirst= values.firstKey(); if (first < priority && values.putIfAbsent(priority, sample) == null) { // ensure we always remove an item while (values.remove(first) == null) { first = values.firstKey(); } } } } finally { unlockForRegularUsage(); } }
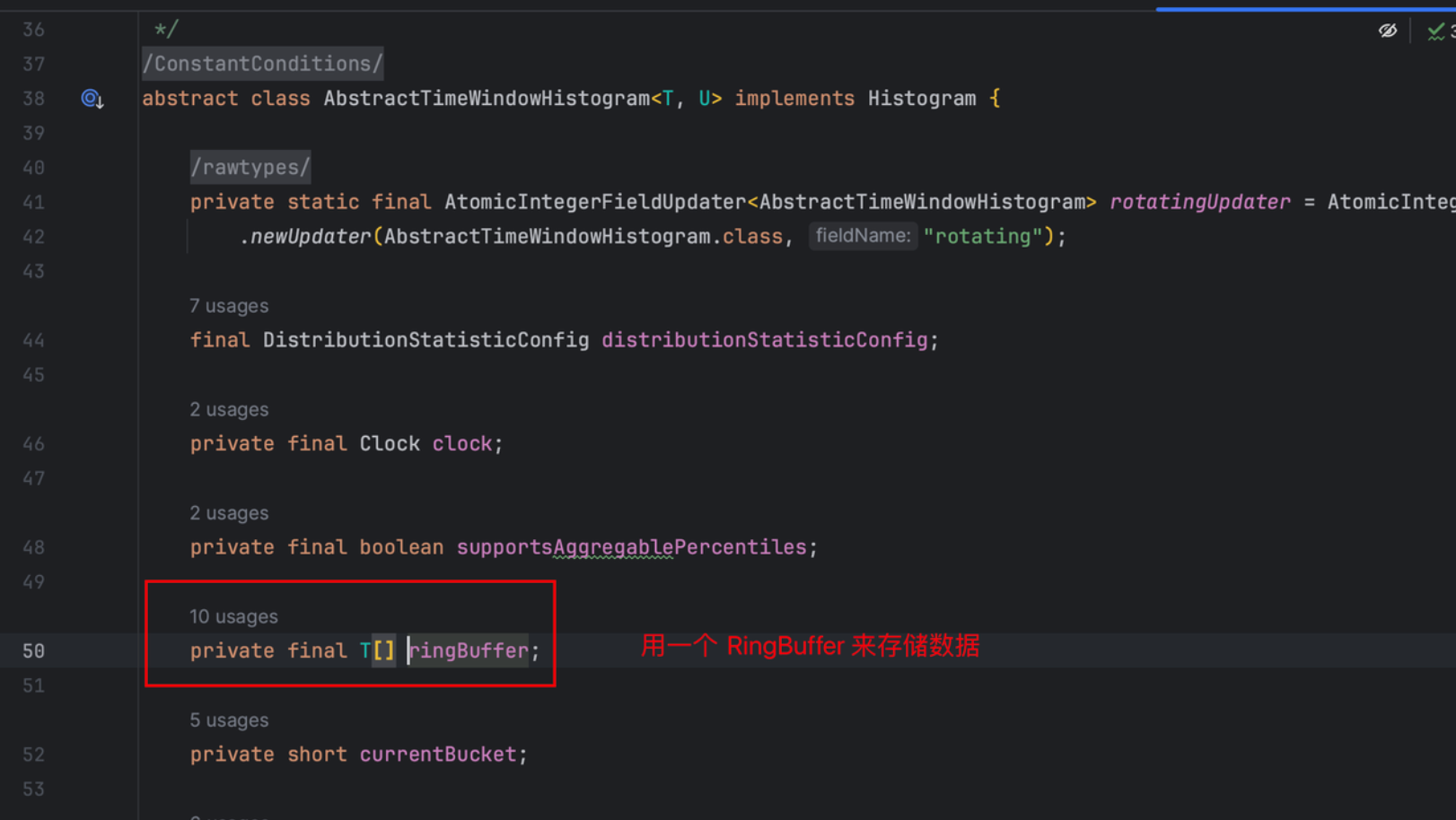
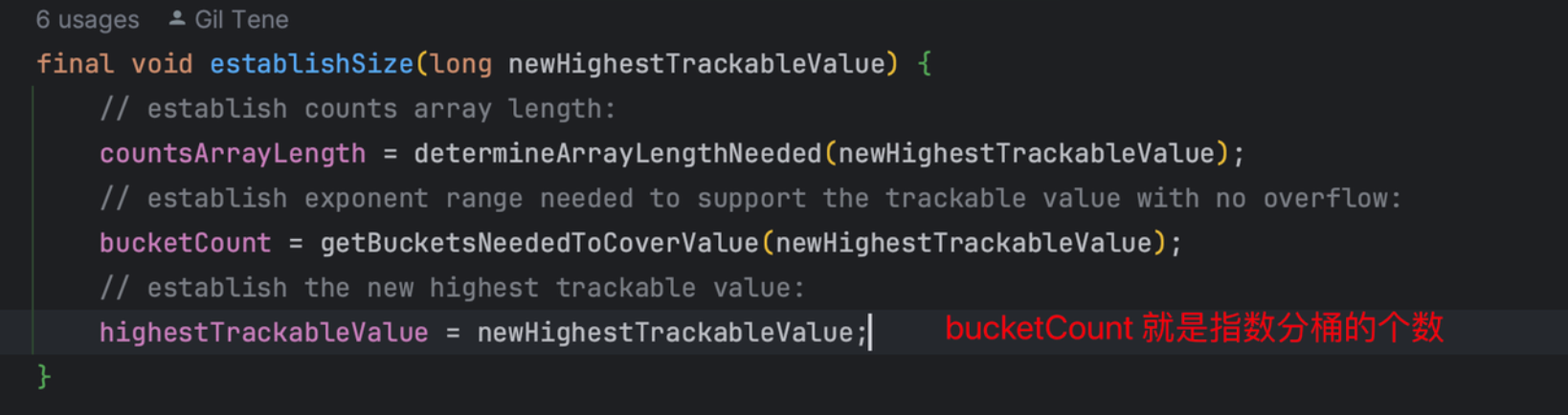
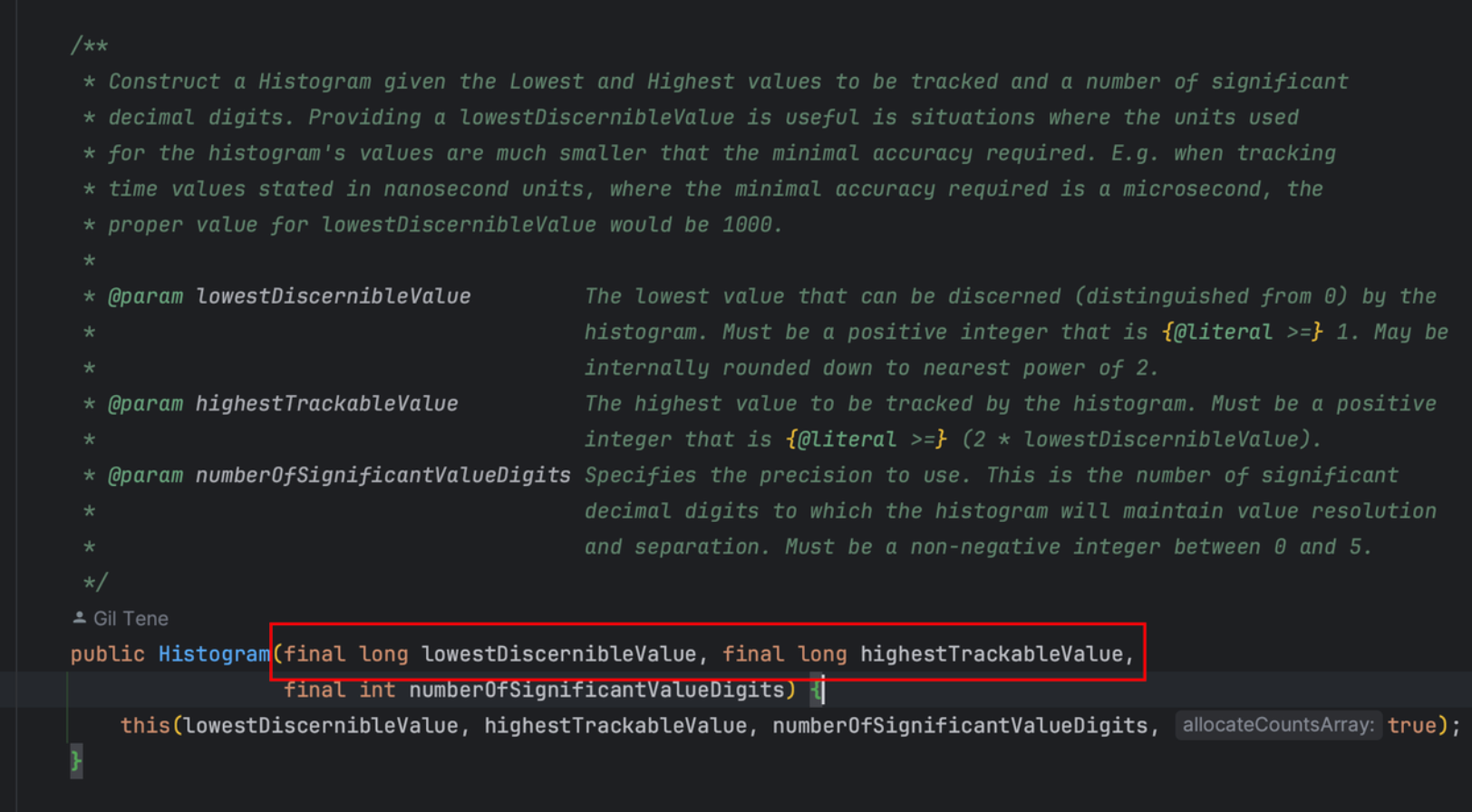
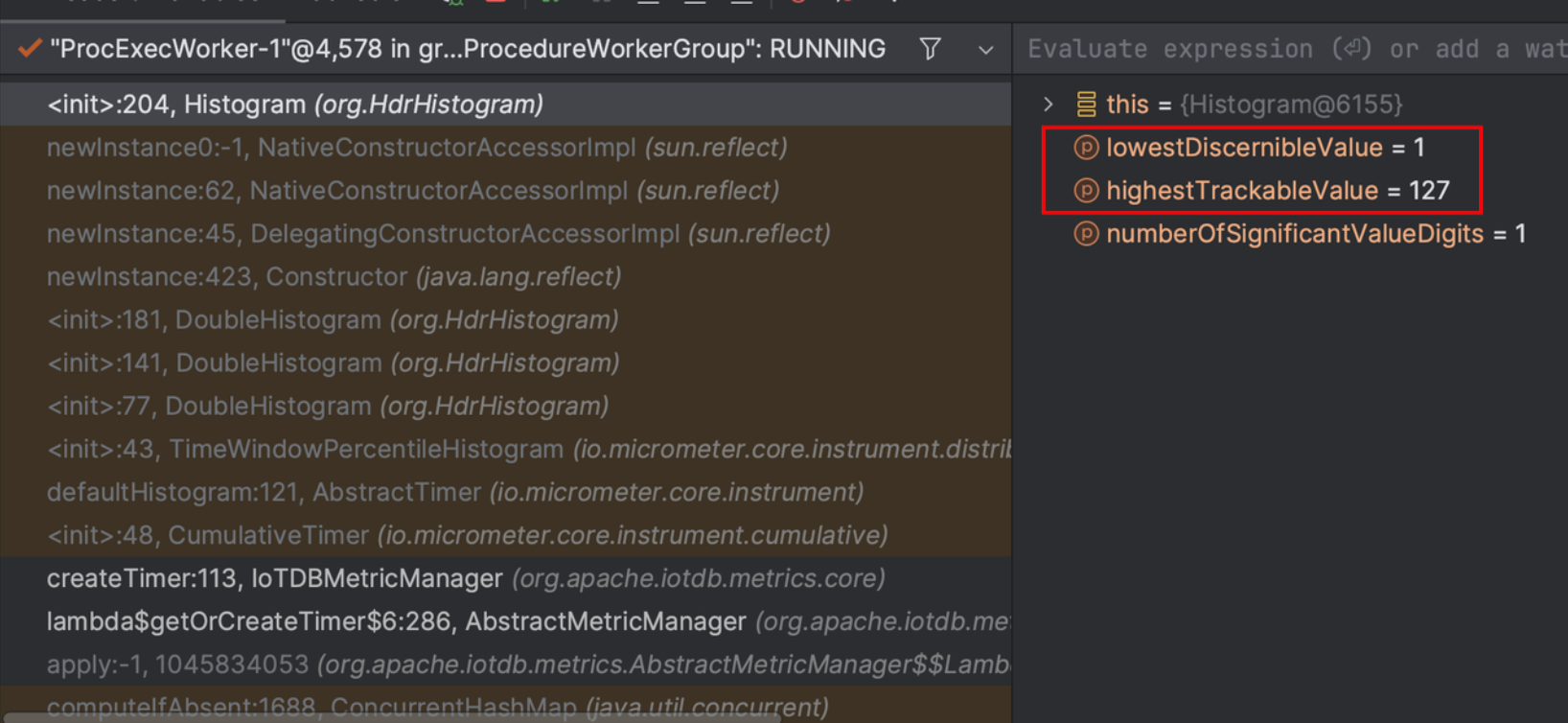
static int numberOfSubBuckets(final int numberOfSignificantValueDigits) {
final long largestValueWithSingleUnitResolution = 2 * (long) Math.pow(10, numberOfSignificantValueDigits);
// We need to maintain power-of-two subBucketCount (for clean direct indexing) that is large enough to
// provide unit resolution to at least largestValueWithSingleUnitResolution. So figure out
// largestValueWithSingleUnitResolution's nearest power-of-two (rounded up), and use that:
int subBucketCountMagnitude = (int) Math.ceil(Math.log(largestValueWithSingleUnitResolution)/Math.log(2));
int subBucketCount = (int) Math.pow(2, subBucketCountMagnitude);
return subBucketCount;
}
@Benchmark publicvoiddropwizardCountSum() { for (inti=0; i < 100; i++) { dropwizardCounter.inc(); } }
@Benchmark publicvoidmicrometerCountSum() { for (inti=0; i < 100; i++) { micrometerCounter.increment(); } } }
测试结果:
> Task :micrometer-benchmarks-core:CounterBenchmark.main() # JMH version: 1.37 # VM version: JDK 17.0.8.1, OpenJDK 64-Bit Server VM, 17.0.8.1+8-LTS # VM invoker: /Users/pengjunzhi/Library/Java/JavaVirtualMachines/corretto-17.0.8.1/Contents/Home/bin/java # VM options: -Dfile.encoding=UTF-8 -Duser.country=CN -Duser.language=zh -Duser.variant # Blackhole mode: compiler (auto-detected, use -Djmh.blackhole.autoDetect=false to disable) # Warmup: 1 iterations, 10 s each # Measurement: 2 iterations, 10 s each # Timeout: 10 min per iteration # Threads: 1 thread, will synchronize iterations # Benchmark mode: Average time, time/op # Benchmark: io.micrometer.benchmark.core.CounterBenchmark.dropwizardCountSum
# Run progress: 0.00% complete, ETA 00:05:00 # Fork: 1 of 5 # Warmup Iteration 1: 504.794 ns/op Iteration 1: 506.459 ns/op Iteration 2: 506.261 ns/op
# Run progress: 10.00% complete, ETA 00:04:31 # Fork: 2 of 5 # Warmup Iteration 1: 506.972 ns/op Iteration 1: 505.873 ns/op Iteration 2: 498.922 ns/op
# Run progress: 20.00% complete, ETA 00:04:01 # Fork: 3 of 5 # Warmup Iteration 1: 506.325 ns/op Iteration 1: 506.829 ns/op Iteration 2: 504.362 ns/op
# Run progress: 30.00% complete, ETA 00:03:32 # Fork: 4 of 5 # Warmup Iteration 1: 503.179 ns/op Iteration 1: 503.631 ns/op Iteration 2: 518.545 ns/op
# Run progress: 40.00% complete, ETA 00:03:01 # Fork: 5 of 5 # Warmup Iteration 1: 509.092 ns/op Iteration 1: 509.741 ns/op Iteration 2: 505.743 ns/op
Result "io.micrometer.benchmark.core.CounterBenchmark.dropwizardCountSum": 506.637 ±(99.9%) 7.589 ns/op [Average] (min, avg, max) = (498.922, 506.637, 518.545), stdev = 5.020 CI (99.9%): [499.048, 514.225] (assumes normal distribution)
# JMH version: 1.37 # VM version: JDK 17.0.8.1, OpenJDK 64-Bit Server VM, 17.0.8.1+8-LTS # VM invoker: /Users/pengjunzhi/Library/Java/JavaVirtualMachines/corretto-17.0.8.1/Contents/Home/bin/java # VM options: -Dfile.encoding=UTF-8 -Duser.country=CN -Duser.language=zh -Duser.variant # Blackhole mode: compiler (auto-detected, use -Djmh.blackhole.autoDetect=false to disable) # Warmup: 1 iterations, 10 s each # Measurement: 2 iterations, 10 s each # Timeout: 10 min per iteration # Threads: 1 thread, will synchronize iterations # Benchmark mode: Average time, time/op # Benchmark: io.micrometer.benchmark.core.CounterBenchmark.micrometerCountSum
# Run progress: 50.00% complete, ETA 00:02:31 # Fork: 1 of 5 # Warmup Iteration 1: 761.443 ns/op Iteration 1: 750.091 ns/op Iteration 2: 717.163 ns/op
# Run progress: 60.00% complete, ETA 00:02:01 # Fork: 2 of 5 # Warmup Iteration 1: 730.985 ns/op Iteration 1: 786.655 ns/op Iteration 2: 583.315 ns/op
# Run progress: 70.00% complete, ETA 00:01:30 # Fork: 3 of 5 # Warmup Iteration 1: 564.985 ns/op Iteration 1: 567.606 ns/op Iteration 2: 675.625 ns/op
# Run progress: 80.00% complete, ETA 00:01:00 # Fork: 4 of 5 # Warmup Iteration 1: 626.955 ns/op Iteration 1: 560.499 ns/op Iteration 2: 692.164 ns/op
# Run progress: 90.00% complete, ETA 00:00:30 # Fork: 5 of 5 # Warmup Iteration 1: 720.045 ns/op Iteration 1: 733.850 ns/op Iteration 2: 753.365 ns/op
Result "io.micrometer.benchmark.core.CounterBenchmark.micrometerCountSum": 682.033 ±(99.9%) 125.825 ns/op [Average] (min, avg, max) = (560.499, 682.033, 786.655), stdev = 83.225 CI (99.9%): [556.208, 807.858] (assumes normal distribution)
# Run complete. Total time: 00:05:02
REMEMBER: The numbers below are just data. To gain reusable insights, you need to follow up on why the numbers are the way they are. Use profilers (see -prof, -lprof), design factorial experiments, perform baseline and negative tests that provide experimental control, make sure the benchmarking environment is safe on JVM/OS/HW level, ask for reviews from the domain experts. Do not assume the numbers tell you what you want them to tell.
NOTE: Current JVM experimentally supports Compiler Blackholes, and they are in use. Please exercise extra caution when trusting the results, look into the generated code to check the benchmark still works, and factorin a small probability of new VM bugs. Additionally, while comparisons between different JVMs are already problematic, the performance difference caused by different Blackhole modes can be very significant. Please make sure you use the consistent Blackhole mode for comparisons.
@Benchmark publicvoiddropwizardRecord() { for (inti=0; i < 100; i++) { dropwizardHistogram.update(i); dropwizardHistogram.getCount(); } }
@Benchmark publicvoidmicrometerRecord() { for (inti=0; i < 100; i++) { micrometerHistogram.record(i); micrometerHistogram.count(); } } }
测试结果:
# JMH version: 1.37 # VM version: JDK 17.0.8.1, OpenJDK 64-Bit Server VM, 17.0.8.1+8-LTS # VM invoker: /Users/pengjunzhi/Library/Java/JavaVirtualMachines/corretto-17.0.8.1/Contents/Home/bin/java # VM options: -Dfile.encoding=UTF-8 -Duser.country=CN -Duser.language=zh -Duser.variant # Blackhole mode: compiler (auto-detected, use -Djmh.blackhole.autoDetect=false to disable) # Warmup: 1 iterations, 10 s each # Measurement: 2 iterations, 10 s each # Timeout: 10 min per iteration # Threads: 1 thread, will synchronize iterations # Benchmark mode: Average time, time/op # Benchmark: io.micrometer.benchmark.core.HistogramBenchmark.dropwizardRecord
# Run progress: 0.00% complete, ETA 00:05:00 # Fork: 1 of 5 # Warmup Iteration 1: 15:22:52.331 [io.micrometer.benchmark.core.HistogramBenchmark.dropwizardRecord-jmh-worker-1] DEBUG io.micrometer.common.util.internal.logging.InternalLoggerFactory - Using SLF4J as the default logging framework 10174.613 ns/op Iteration 1: 9998.056 ns/op Iteration 2: 10828.580 ns/op
# Run progress: 10.00% complete, ETA 00:04:32 # Fork: 2 of 5 # Warmup Iteration 1: 15:23:22.545 [io.micrometer.benchmark.core.HistogramBenchmark.dropwizardRecord-jmh-worker-1] DEBUG io.micrometer.common.util.internal.logging.InternalLoggerFactory - Using SLF4J as the default logging framework 10024.374 ns/op Iteration 1: 9990.595 ns/op Iteration 2: 10488.892 ns/op
# Run progress: 20.00% complete, ETA 00:04:01 # Fork: 3 of 5 # Warmup Iteration 1: 15:23:52.910 [io.micrometer.benchmark.core.HistogramBenchmark.dropwizardRecord-jmh-worker-1] DEBUG io.micrometer.common.util.internal.logging.InternalLoggerFactory - Using SLF4J as the default logging framework 10204.101 ns/op Iteration 1: 10101.247 ns/op Iteration 2: 10982.767 ns/op
# Run progress: 30.00% complete, ETA 00:03:31 # Fork: 4 of 5 # Warmup Iteration 1: 15:24:23.120 [io.micrometer.benchmark.core.HistogramBenchmark.dropwizardRecord-jmh-worker-1] DEBUG io.micrometer.common.util.internal.logging.InternalLoggerFactory - Using SLF4J as the default logging framework 9942.547 ns/op Iteration 1: 10305.283 ns/op Iteration 2: 10703.590 ns/op
# Run progress: 40.00% complete, ETA 00:03:01 # Fork: 5 of 5 # Warmup Iteration 1: 15:24:53.335 [io.micrometer.benchmark.core.HistogramBenchmark.dropwizardRecord-jmh-worker-1] DEBUG io.micrometer.common.util.internal.logging.InternalLoggerFactory - Using SLF4J as the default logging framework 9863.582 ns/op Iteration 1: 9955.748 ns/op Iteration 2: 10482.406 ns/op
Result "io.micrometer.benchmark.core.HistogramBenchmark.dropwizardRecord": 10383.716 ±(99.9%) 563.945 ns/op [Average] (min, avg, max) = (9955.748, 10383.716, 10982.767), stdev = 373.015 CI (99.9%): [9819.771, 10947.662] (assumes normal distribution)
# JMH version: 1.37 # VM version: JDK 17.0.8.1, OpenJDK 64-Bit Server VM, 17.0.8.1+8-LTS # VM invoker: /Users/pengjunzhi/Library/Java/JavaVirtualMachines/corretto-17.0.8.1/Contents/Home/bin/java # VM options: -Dfile.encoding=UTF-8 -Duser.country=CN -Duser.language=zh -Duser.variant # Blackhole mode: compiler (auto-detected, use -Djmh.blackhole.autoDetect=false to disable) # Warmup: 1 iterations, 10 s each # Measurement: 2 iterations, 10 s each # Timeout: 10 min per iteration # Threads: 1 thread, will synchronize iterations # Benchmark mode: Average time, time/op # Benchmark: io.micrometer.benchmark.core.HistogramBenchmark.micrometerRecord
# Run progress: 50.00% complete, ETA 00:02:31 # Fork: 1 of 5 # Warmup Iteration 1: 15:25:23.556 [io.micrometer.benchmark.core.HistogramBenchmark.micrometerRecord-jmh-worker-1] DEBUG io.micrometer.common.util.internal.logging.InternalLoggerFactory - Using SLF4J as the default logging framework 6960.654 ns/op Iteration 1: 6775.768 ns/op Iteration 2: 6614.436 ns/op
# Run progress: 60.00% complete, ETA 00:02:00 # Fork: 2 of 5 # Warmup Iteration 1: 15:25:53.835 [io.micrometer.benchmark.core.HistogramBenchmark.micrometerRecord-jmh-worker-1] DEBUG io.micrometer.common.util.internal.logging.InternalLoggerFactory - Using SLF4J as the default logging framework 6919.224 ns/op Iteration 1: 6918.534 ns/op Iteration 2: 6843.185 ns/op
# Run progress: 70.00% complete, ETA 00:01:30 # Fork: 3 of 5 # Warmup Iteration 1: 15:26:24.055 [io.micrometer.benchmark.core.HistogramBenchmark.micrometerRecord-jmh-worker-1] DEBUG io.micrometer.common.util.internal.logging.InternalLoggerFactory - Using SLF4J as the default logging framework 6957.126 ns/op Iteration 1: 6853.690 ns/op Iteration 2: 6840.857 ns/op
# Run progress: 80.00% complete, ETA 00:01:00 # Fork: 4 of 5 # Warmup Iteration 1: 15:26:54.287 [io.micrometer.benchmark.core.HistogramBenchmark.micrometerRecord-jmh-worker-1] DEBUG io.micrometer.common.util.internal.logging.InternalLoggerFactory - Using SLF4J as the default logging framework 6924.513 ns/op Iteration 1: 6958.296 ns/op Iteration 2: 6813.379 ns/op
# Run progress: 90.00% complete, ETA 00:00:30 # Fork: 5 of 5 # Warmup Iteration 1: 15:27:24.499 [io.micrometer.benchmark.core.HistogramBenchmark.micrometerRecord-jmh-worker-1] DEBUG io.micrometer.common.util.internal.logging.InternalLoggerFactory - Using SLF4J as the default logging framework 7021.623 ns/op Iteration 1: 6887.827 ns/op Iteration 2: 6698.237 ns/op
Result "io.micrometer.benchmark.core.HistogramBenchmark.micrometerRecord": 6820.421 ±(99.9%) 155.021 ns/op [Average] (min, avg, max) = (6614.436, 6820.421, 6958.296), stdev = 102.537 CI (99.9%): [6665.400, 6975.442] (assumes normal distribution)
# Run complete. Total time: 00:05:02
REMEMBER: The numbers below are just data. To gain reusable insights, you need to follow up on why the numbers are the way they are. Use profilers (see -prof, -lprof), design factorial experiments, perform baseline and negative tests that provide experimental control, make sure the benchmarking environment is safe on JVM/OS/HW level, ask for reviews from the domain experts. Do not assume the numbers tell you what you want them to tell.
NOTE: Current JVM experimentally supports Compiler Blackholes, and they are in use. Please exercise extra caution when trusting the results, look into the generated code to check the benchmark still works, and factorin a small probability of new VM bugs. Additionally, while comparisons between different JVMs are already problematic, the performance difference caused by different Blackhole modes can be very significant. Please make sure you use the consistent Blackhole mode for comparisons.
Deprecated Gradle features were used in this build, making it incompatible with Gradle 9.0.
You can use '--warning-mode all' to show the individual deprecation warnings and determine if they come from your own scripts or plugins.
For more on this, please refer to https://docs.gradle.org/8.3/userguide/command_line_interface.html#sec:command_line_warnings in the Gradle documentation.
@Benchmark publicvoidmicrometerSumTimedWithSupplier() { for (inti=0; i < 100; i++) { micrometerTimer.record(x + y, TimeUnit.MILLISECONDS); } }
@Benchmark publicvoiddropwizardSumTimedWithSupplier() { for (inti=0; i < 100; i++) { dropwizardTimer.update(x + y, TimeUnit.MILLISECONDS); } }
@Benchmark publicvoidmicrometerSumTimedWithSample() { for (inti=0; i < 10; i++) { Timer.Samplesample= Timer.start(micrometerRegistry); intsum= sum(); sample.stop(micrometerTimer); } }
@Benchmark publicvoiddropwizardSumTimedWithSample()throws Exception { for (inti=0; i < 10; i++) { dropwizardTimer.time(this::sum); } }
publicintsum() { return x + y; }
}
测试结果:
> Task :micrometer-benchmarks-core:TimerBenchmark.main() # JMH version: 1.37 # VM version: JDK 17.0.8.1, OpenJDK 64-Bit Server VM, 17.0.8.1+8-LTS # VM invoker: /Users/pengjunzhi/Library/Java/JavaVirtualMachines/corretto-17.0.8.1/Contents/Home/bin/java # VM options: -Dfile.encoding=UTF-8 -Duser.country=CN -Duser.language=zh -Duser.variant # Blackhole mode: compiler (auto-detected, use -Djmh.blackhole.autoDetect=false to disable) # Warmup: 1 iterations, 10 s each # Measurement: 2 iterations, 10 s each # Timeout: 10 min per iteration # Threads: 1 thread, will synchronize iterations # Benchmark mode: Average time, time/op # Benchmark: io.micrometer.benchmark.core.TimerBenchmark.dropwizardSumTimedWithSample
# Run progress: 0.00% complete, ETA 00:10:00 # Fork: 1 of 5 # Warmup Iteration 1: 1516.590 ns/op Iteration 1: 1530.353 ns/op Iteration 2: 1605.669 ns/op
# Run progress: 5.00% complete, ETA 00:09:33 # Fork: 2 of 5 # Warmup Iteration 1: 1507.719 ns/op Iteration 1: 1488.804 ns/op Iteration 2: 1576.604 ns/op
# Run progress: 10.00% complete, ETA 00:09:03 # Fork: 3 of 5 # Warmup Iteration 1: 1502.103 ns/op Iteration 1: 1497.555 ns/op Iteration 2: 1555.023 ns/op
# Run progress: 15.00% complete, ETA 00:08:32 # Fork: 4 of 5 # Warmup Iteration 1: 1556.940 ns/op Iteration 1: 1458.053 ns/op Iteration 2: 1505.888 ns/op
# Run progress: 20.00% complete, ETA 00:08:02 # Fork: 5 of 5 # Warmup Iteration 1: 1505.264 ns/op Iteration 1: 1516.316 ns/op Iteration 2: 1580.754 ns/op
Result "io.micrometer.benchmark.core.TimerBenchmark.dropwizardSumTimedWithSample": 1531.502 ±(99.9%) 70.863 ns/op [Average] (min, avg, max) = (1458.053, 1531.502, 1605.669), stdev = 46.871 CI (99.9%): [1460.639, 1602.365] (assumes normal distribution)
# JMH version: 1.37 # VM version: JDK 17.0.8.1, OpenJDK 64-Bit Server VM, 17.0.8.1+8-LTS # VM invoker: /Users/pengjunzhi/Library/Java/JavaVirtualMachines/corretto-17.0.8.1/Contents/Home/bin/java # VM options: -Dfile.encoding=UTF-8 -Duser.country=CN -Duser.language=zh -Duser.variant # Blackhole mode: compiler (auto-detected, use -Djmh.blackhole.autoDetect=false to disable) # Warmup: 1 iterations, 10 s each # Measurement: 2 iterations, 10 s each # Timeout: 10 min per iteration # Threads: 1 thread, will synchronize iterations # Benchmark mode: Average time, time/op # Benchmark: io.micrometer.benchmark.core.TimerBenchmark.dropwizardSumTimedWithSupplier
# Run progress: 25.00% complete, ETA 00:07:32 # Fork: 1 of 5 # Warmup Iteration 1: 12358.755 ns/op Iteration 1: 12309.136 ns/op Iteration 2: 12922.583 ns/op
# Run progress: 30.00% complete, ETA 00:07:02 # Fork: 2 of 5 # Warmup Iteration 1: 12072.889 ns/op Iteration 1: 11971.788 ns/op Iteration 2: 12708.188 ns/op
# Run progress: 35.00% complete, ETA 00:06:32 # Fork: 3 of 5 # Warmup Iteration 1: 12240.725 ns/op Iteration 1: 12189.390 ns/op Iteration 2: 12794.850 ns/op
# Run progress: 40.00% complete, ETA 00:06:02 # Fork: 4 of 5 # Warmup Iteration 1: 11909.155 ns/op Iteration 1: 12186.550 ns/op Iteration 2: 13181.730 ns/op
# Run progress: 45.00% complete, ETA 00:05:31 # Fork: 5 of 5 # Warmup Iteration 1: 12192.867 ns/op Iteration 1: 12209.921 ns/op Iteration 2: 12930.563 ns/op
Result "io.micrometer.benchmark.core.TimerBenchmark.dropwizardSumTimedWithSupplier": 12540.470 ±(99.9%) 624.765 ns/op [Average] (min, avg, max) = (11971.788, 12540.470, 13181.730), stdev = 413.243 CI (99.9%): [11915.705, 13165.235] (assumes normal distribution)
# JMH version: 1.37 # VM version: JDK 17.0.8.1, OpenJDK 64-Bit Server VM, 17.0.8.1+8-LTS # VM invoker: /Users/pengjunzhi/Library/Java/JavaVirtualMachines/corretto-17.0.8.1/Contents/Home/bin/java # VM options: -Dfile.encoding=UTF-8 -Duser.country=CN -Duser.language=zh -Duser.variant # Blackhole mode: compiler (auto-detected, use -Djmh.blackhole.autoDetect=false to disable) # Warmup: 1 iterations, 10 s each # Measurement: 2 iterations, 10 s each # Timeout: 10 min per iteration # Threads: 1 thread, will synchronize iterations # Benchmark mode: Average time, time/op # Benchmark: io.micrometer.benchmark.core.TimerBenchmark.micrometerSumTimedWithSample
# Run progress: 50.00% complete, ETA 00:05:01 # Fork: 1 of 5 # Warmup Iteration 1: 520.268 ns/op Iteration 1: 520.347 ns/op Iteration 2: 515.323 ns/op
# Run progress: 55.00% complete, ETA 00:04:31 # Fork: 2 of 5 # Warmup Iteration 1: 516.566 ns/op Iteration 1: 520.164 ns/op Iteration 2: 509.640 ns/op
# Run progress: 60.00% complete, ETA 00:04:01 # Fork: 3 of 5 # Warmup Iteration 1: 509.843 ns/op Iteration 1: 507.147 ns/op Iteration 2: 506.309 ns/op
# Run progress: 65.00% complete, ETA 00:03:31 # Fork: 4 of 5 # Warmup Iteration 1: 510.824 ns/op Iteration 1: 504.709 ns/op Iteration 2: 505.124 ns/op
# Run progress: 70.00% complete, ETA 00:03:00 # Fork: 5 of 5 # Warmup Iteration 1: 509.629 ns/op Iteration 1: 516.369 ns/op Iteration 2: 501.427 ns/op
Result "io.micrometer.benchmark.core.TimerBenchmark.micrometerSumTimedWithSample": 510.656 ±(99.9%) 10.354 ns/op [Average] (min, avg, max) = (501.427, 510.656, 520.347), stdev = 6.849 CI (99.9%): [500.302, 521.010] (assumes normal distribution)
# JMH version: 1.37 # VM version: JDK 17.0.8.1, OpenJDK 64-Bit Server VM, 17.0.8.1+8-LTS # VM invoker: /Users/pengjunzhi/Library/Java/JavaVirtualMachines/corretto-17.0.8.1/Contents/Home/bin/java # VM options: -Dfile.encoding=UTF-8 -Duser.country=CN -Duser.language=zh -Duser.variant # Blackhole mode: compiler (auto-detected, use -Djmh.blackhole.autoDetect=false to disable) # Warmup: 1 iterations, 10 s each # Measurement: 2 iterations, 10 s each # Timeout: 10 min per iteration # Threads: 1 thread, will synchronize iterations # Benchmark mode: Average time, time/op # Benchmark: io.micrometer.benchmark.core.TimerBenchmark.micrometerSumTimedWithSupplier
# Run progress: 75.00% complete, ETA 00:02:30 # Fork: 1 of 5 # Warmup Iteration 1: 2741.534 ns/op Iteration 1: 2716.235 ns/op Iteration 2: 2762.197 ns/op
# Run progress: 80.00% complete, ETA 00:02:00 # Fork: 2 of 5 # Warmup Iteration 1: 2764.662 ns/op Iteration 1: 2788.028 ns/op Iteration 2: 2801.328 ns/op
# Run progress: 85.00% complete, ETA 00:01:30 # Fork: 3 of 5 # Warmup Iteration 1: 2775.788 ns/op Iteration 1: 2794.196 ns/op Iteration 2: 2833.326 ns/op
# Run progress: 90.00% complete, ETA 00:01:00 # Fork: 4 of 5 # Warmup Iteration 1: 2793.570 ns/op Iteration 1: 2774.927 ns/op Iteration 2: 2818.794 ns/op
# Run progress: 95.00% complete, ETA 00:00:30 # Fork: 5 of 5 # Warmup Iteration 1: 2773.815 ns/op Iteration 1: 2752.855 ns/op Iteration 2: 2816.498 ns/op
Result "io.micrometer.benchmark.core.TimerBenchmark.micrometerSumTimedWithSupplier": 2785.839 ±(99.9%) 53.348 ns/op [Average] (min, avg, max) = (2716.235, 2785.839, 2833.326), stdev = 35.287 CI (99.9%): [2732.490, 2839.187] (assumes normal distribution)
# Run complete. Total time: 00:10:03
REMEMBER: The numbers below are just data. To gain reusable insights, you need to follow up on why the numbers are the way they are. Use profilers(see -prof, -lprof), design factorial experiments, perform baseline and negative tests that provide experimental control, make sure the benchmarking environment is safe on JVM/OS/HW level, ask for reviews from the domain experts. Do not assume the numbers tell you what you want them to tell.
NOTE: Current JVM experimentally supports Compiler Blackholes, and they are in use. Please exercise extra caution when trusting the results, look into the generated code to check the benchmark still works, and factor in a small probability of newVM bugs. Additionally, while comparisons between different JVMs are already problematic, the performance difference caused by different Blackhole modes can be very significant. Please make sure you use the consistent Blackhole mode for comparisons.