Nov 26, 2023
Java 进程内存占用及可观测性调研&内存异常排查最佳实践
在以往实践中 IoTDB 团队对 Java 内存发现了一些问题:
- IoTDB 的实际占用内存超过了我们「以往认知 」的 “堆内存 +
MAX_DIRECT_MEMORY_SIZE” - 堆外内存泄漏,亟需堆外内存管理的最佳实践
本文从上述问题出发,以 Java 进程(JVM)的视角,调研其所占内存。力求把「概念」理清,并探究「监控」手段和「最佳实践」,最终达到「补齐」IoTDB 目前相关板块的目的。
注:作为调研工作,本文大量参考互联网资料(均放在了结尾的 Reference 里),亦有作者的思考与总结。文档难免有疏忽错误,欢迎大家批评指正!可以通过博客上方的 github、邮箱或微信联系我。
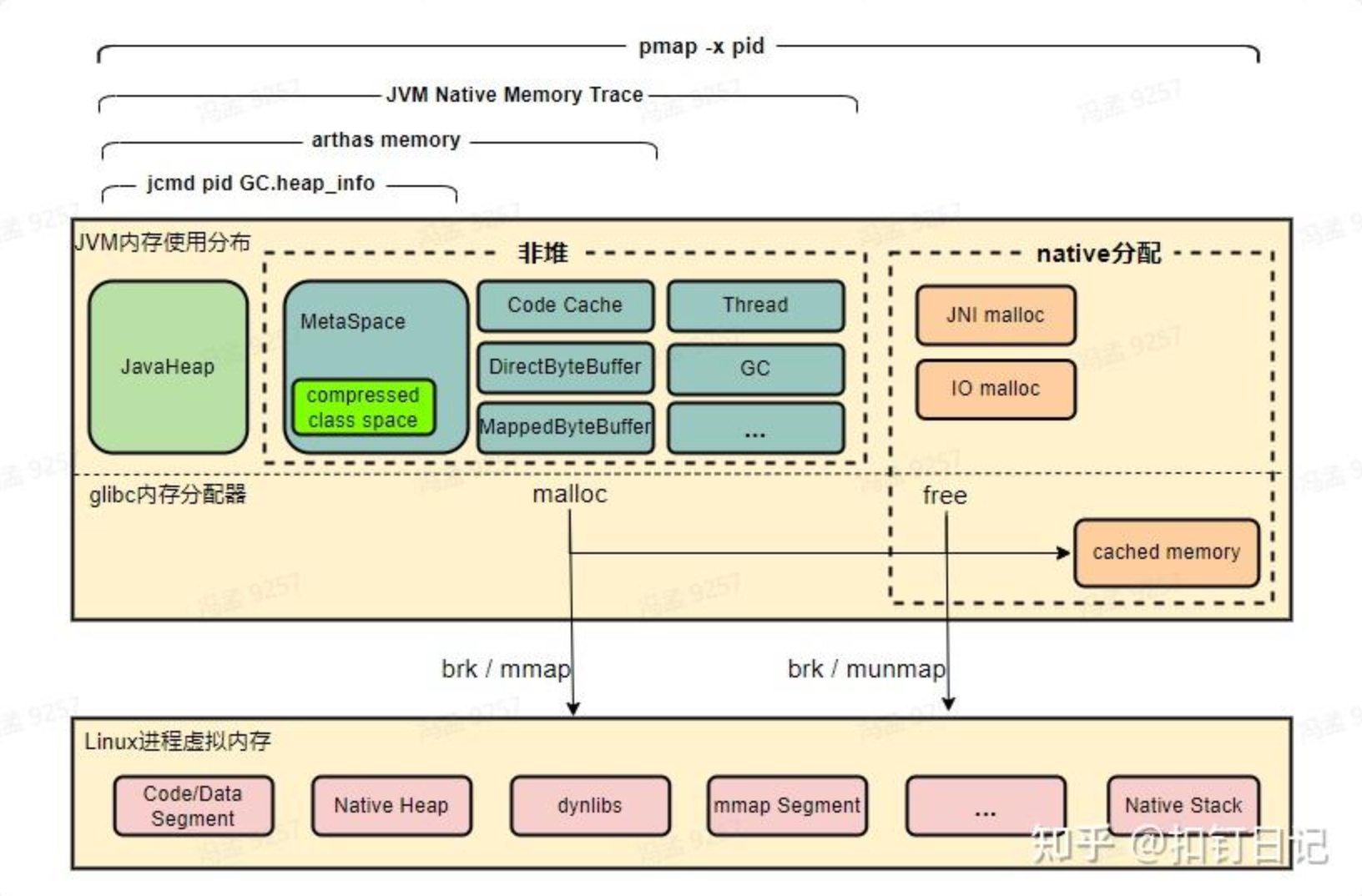
【概念】Java 进程所用内存
开门见山,先画出 Java 进程所占内存图:
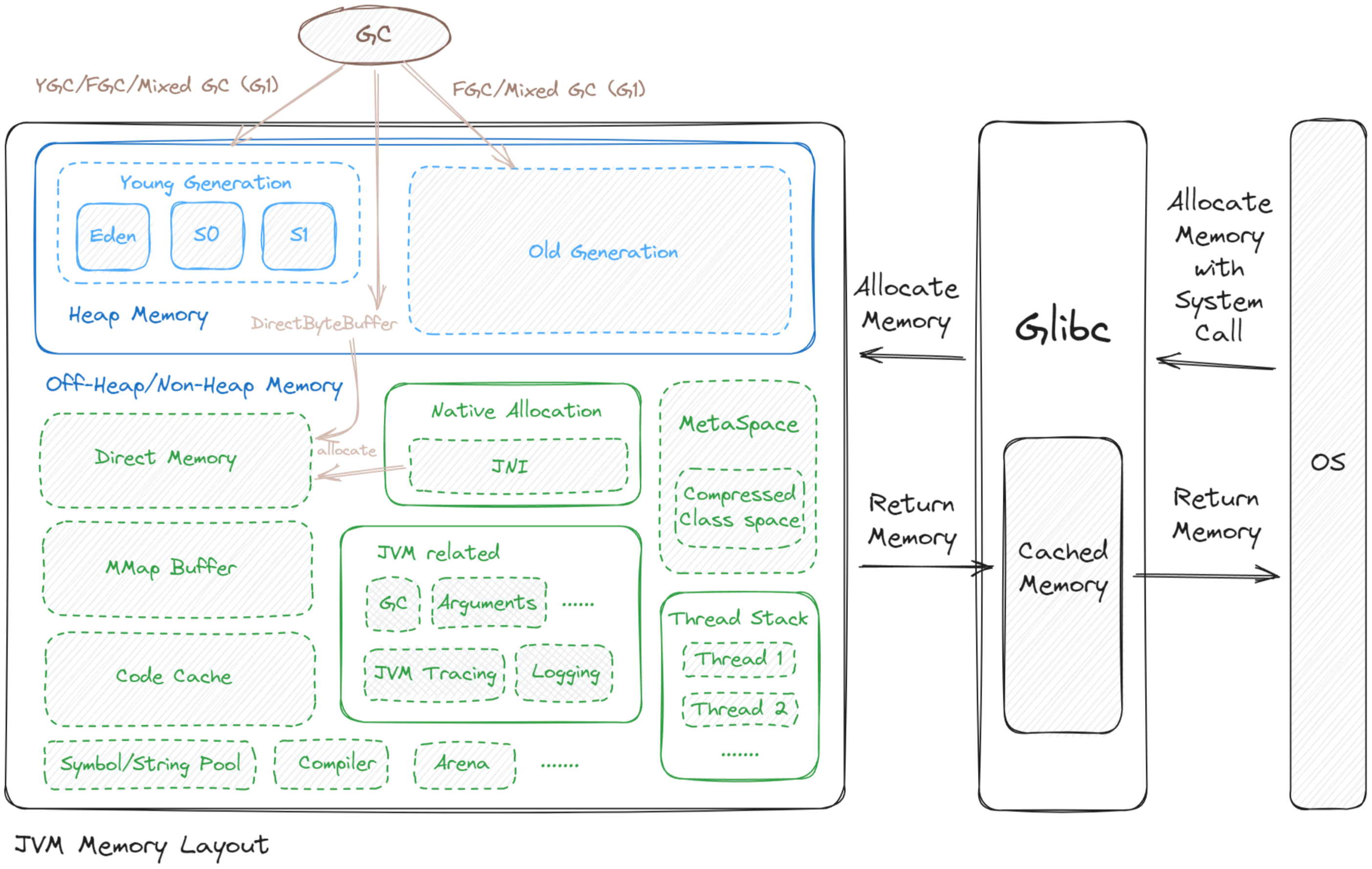
可以看到:
- JVM 的内存被分为了不同的区域,主要由 Java 堆内存、非堆内存组成,在 Linux 上,JVM 通过 glibc 与 OS 进行内存分配与去配。
- 我们分析 Java 进程所占内存,可以从上图的各个板块着手切入。
我们从 Java 提供的原生内存监控工具 Native Memory Tracking(NMT) 切入,一一介绍上图中所涉及的内存板块。这里贴出一段 NMT 的输出:
Total: reserved=10575644KB, committed=443024KB |
可以看到,Java 进程所占内存项有 Java Heap、Class、Thread、Code 等等。
除了 Native Memory Tracking 记录的内存使用,还有两种内存 Native Memory Tracking 没有记录,那就是:
- MMap Buffer:文件映射内存
- JNI 方法里的内存分配
这些内存项可以分为:「Java 堆内存」和「非(Java)堆内存」。后文将基于这一分类展开,一一进行介绍。
Java 堆内存
Java 堆内存,所有 Java 对象分配占用内存的来源,由 JVM GC 管理回收。
//堆内存占用,reserve 了 8323072KB,当前 commit 了 192512KB 用于实际使用 |
需要注意的是:堆这个词可以指代很多,操作系统里有堆;JVM 中有堆;Java 中还有 native 堆(C heap)
- 我们一般说的「堆内存」在 Java 开发语境下指的是「Java 堆内存」
- 而 C heap 虽然也可以叫「堆内存」,但在 Java 开发语境下实际上习惯被划分到「非堆内存」
因此为了严谨,本文对于 Java 开发语境下的「堆内存」统一叫为「Java 堆内存」
JVM 堆内存是分代的,分为 Young、Old Generation。
我们经常看到的可能是 Xmx 以及 Xms 这两个参数:
Xmx:对应 最大堆大小MaxHeapSizeXms:相当于同时设置最小堆*大小MinHeapSize和初始堆大小InitialHeapSize
这部分大家经常打交道,都比较熟悉,不多赘述。
非堆内存
什么是非堆内存/堆外内存?
这里要明晰一个概念:
非堆内存:是指不受到 Java 堆垃圾回收直接管理的内存。
- 从 JVM 内存模型角度来看,甚至方法区也属于非堆内存(即使在主流 JVM 实现中,方法区内部包含堆内存实现),包括 Java 方法栈区内存和 native 内存等都属于非堆内存。
堆外内存:理论上语义等同于非堆内存。但笔者在调研时,发现实际上很多语境下特指 DirectMemory(java.nio.DirectByteBuffer)
二者有区别!为了明确概念,避免混淆,本文中:
- 非堆内存是指不受到 Java 托管堆垃圾回收管理的内存
- 堆外内存特指 DirectMemory(native heap)
堆外内存有什么好处?
使用堆外内存(DirectMemory)的好处主要有以下两个:
- 避免堆内内存 Full GC 造成的 stop-the-world 延迟,当然也可以降低 OOM 风险,前提是要妥善管理堆外内存
- 绕过用户态到内核态的切换,实现高效数据读写,如零拷贝和内存映射。(一般 nio 中它可以减少一次 Java 堆向native 堆做的内存拷贝以及可以直接做 Memory Mapping 以提高速度。)
因此 Spark、Flink、Kafka 等这些鼎鼎大名的大数据组件都会积极地使用堆外内存,Netty 也有大量使用。
补充:
- 为什么堆外内存能提高 I/O 效率?
- 因为从堆内向磁盘/网卡读写数据时,数据会被先复制到堆外内存,然后堆外内存的数据被拷贝到硬件,如下图所示,直接写入堆外内存可避免堆内到堆外的一次数据拷贝。
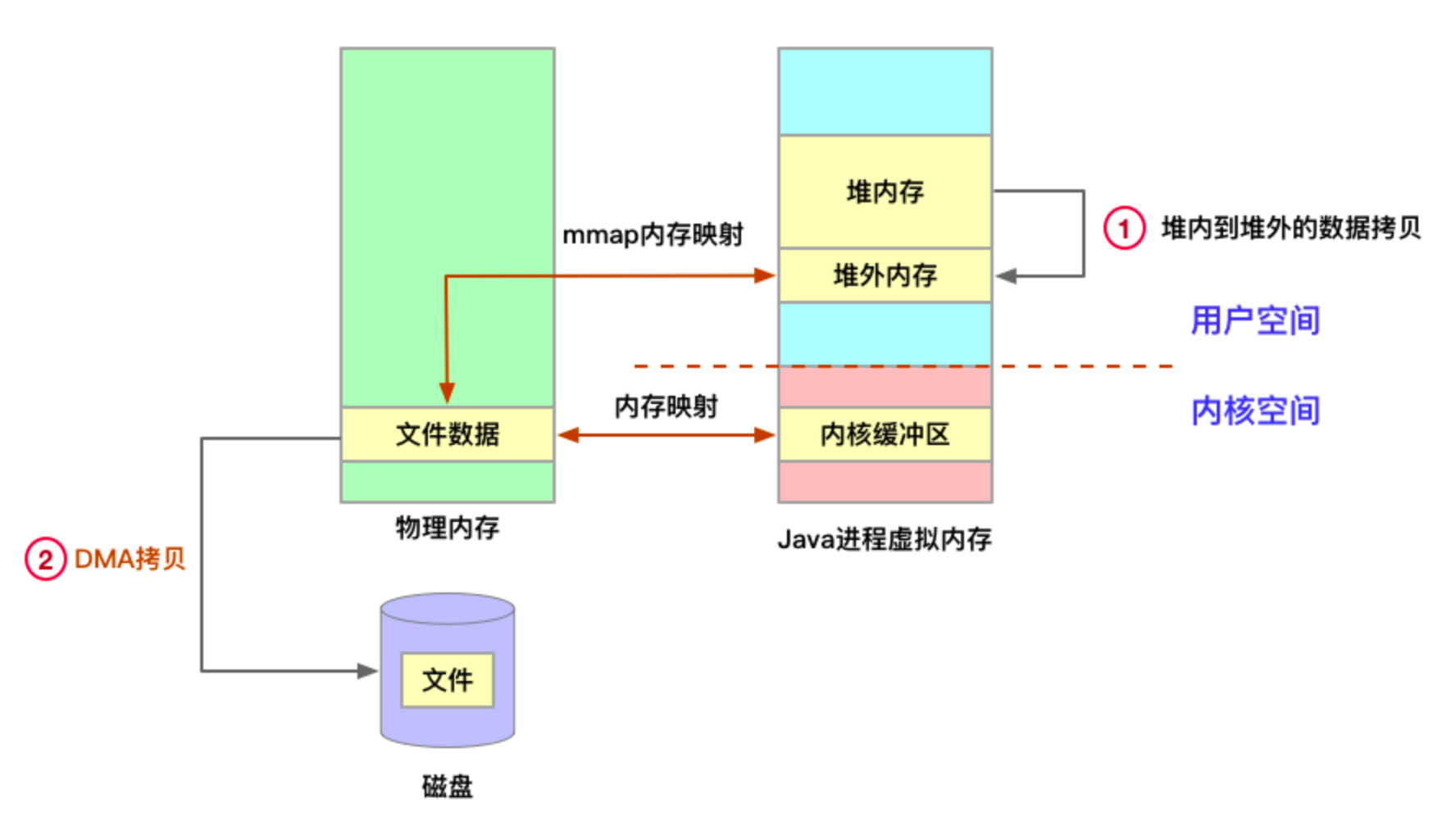
- 为什么操作系统一定要将 Java 数据拷贝到堆外内存再进行 I/O 呢?
这是由于write、read等函数进行系统调用时,参数传的是内存地址,而 JVM 进行 GC 时,会对 Java 堆进行碎片整理,移动对象在内存中的位置,进而导致内存地址的变化。如果在 I/O 操作进行中发生了 GC,内存地址发生变化,I/O 操作的数据就全乱套了。而堆外内存是不受 GC 控制的,因此需要把数据拷贝到堆外内存之后再进行 I/O 操作。
(R 大在知乎上有更详细的回答,感兴趣的可以看下)
这里其实是在迁就 OpenJDK 里的 HotSpot VM 的一点实现细节。
HotSpot VM 里的 GC 除了 CMS 之外都是要移动对象的,是所谓“compacting GC”。
如果要把一个Java里的 byte[] 对象的引用传给native代码,让native代码直接访问数组的内容的话,就必须要保证native代码在访问的时候这个 byte[] 对象不能被移动,也就是要被“pin”(钉)住。
可惜 HotSpot VM 出于一些取舍而决定不实现单个对象层面的 object pinning,要 pin 的话就得暂时禁用 GC——也就等于把整个 Java 堆都给 pin 住。
所以 Oracle/Sun JDK / OpenJDK 的这个地方就用了点绕弯的做法。它假设把 HeapByteBuffer 背后的 byte[] 里的内容拷贝一次是一个时间开销可以接受的操作,同时假设真正的 I/O 可能是一个很慢的操作。
于是它就先把 HeapByteBuffer 背后的 byte[] 的内容拷贝到一个 DirectByteBuffer 背后的 native memory去,这个拷贝会涉及 sun.misc.Unsafe.copyMemory() 的调用,背后是类似 memcpy() 的实现。这个操作本质上是会在整个拷贝过程中暂时不允许发生 GC 的。
然后数据被拷贝到 native memory 之后就好办了,就去做真正的 I/O,把 DirectByteBuffer 背后的 native memory 地址传给真正做 I/O 的函数。这边就不需要再去访问 Java 对象去读写要做 I/O 的数据了。
非堆内存有哪些?
承接上文 NMT 的各项补充展开说明。此处整理各网络资料:
- Java Class,JVM 将类文件加载到内存中用于后续使用所占用的空间,注意是 JVM C++ 层面的内存占用,主要包括类文件中在 JVM 解析为 C++ 的 Klass 类(Klass 是 JVM 源码中的一个 C++ 类,可以理解为类在 JVM 中的内存形式)以及相关元素,对应的 Java 反射类 Class 还是在堆内存空间中。
包含两部分:
一是 metadata,被
-XX:MaxMetaspaceSize限制最大大小。对应我们比较熟悉的 Metaspace。二是 class space,被
-XX:CompressedClassSpaceSize限制最大大小。对应我们比较熟悉的 Compressed Class Space。对于 metaspace 和 compressed class space,补充说明:
元空间保存的数据,目前分为两大类:
- Java 类数据:即加载的 Java 类对应 JVM 中的 Klass 对象,但是这个 Klass 对象中存储的很多数据都是指针,具体的数据存储属于非 Java 类数据,一般非 Java 类数据远比 Java 类数据占用空间大。
- 非 Java 类数据:即被 Klass 对象引用的一些数据,例如:类中的各种方法,注解,执行采集与统计信息、静态变量等等。
如果是 64 位的 JVM 虚拟机,并且开启了压缩类指针(-XX:+UseCompressedClassPointers,默认是开启的),那么元空间会被划分成两部分:
- 类元空间:存储上面说的Java 类数据的空间(compressed class space)
- 数据元空间:存储上面说的非 Java 类数据的空间(metaspace)
// reserved、committed、used 含义,后文有详细介绍 :Java 内存占用分类 & 观测手段 调研 |
- Symbol:加载类的时候,有很多字符串信息,不同类的字符串信息可能会重复。所以统一放入符号表复用。 包含 SymbolTable:(存储 names signatures)和 StringTable:(存储 interned strings)。可以通过
-XX:+PrintStringTableStatistics打印具体的信息
- StringTable 这个数据结构的大小受
-XX:StringTableSize限制,但总内存大小不受限制。
StringTable 是一个本地固定大小的哈希表,其用来保存内部字符串。
String.intern()被调用时会往 StringTable 插入一个 String(若该 String 不存在)我们能够通过-XX:StringTableSize 标志配置 StringTable 的大小,-XX:StringTableSize 的含义是:Number of buckets in the interned String table
该参数主要 trade off 了哈希碰撞概率和哈希表内存大小,参数越大,StringTable 占用内存越大,但插入速度越快。参数越小,StringTable 占用内存越小,但由于哈希碰撞插入速度慢。
(https://www.baeldung.com/native-memory-tracking-in-jvm、https://www.baeldung.com/java-string-pool)
经过经过实测和调研,从 Java 7u40 到 JDK11 默认大小是 60013 ,JDK11及其之后是 65536。下图是 JDK 17 的默认大小:

Symbol (reserved=18629KB, committed=18629KB)(malloc=16479KB #445877) // 通过 malloc 系统调用方式一共分配了 16479KB,一共调用了 445877 次 malloc(arena=2150KB #1) //通过 arena 系统调用方式一共分配了 2150KB,一共调用了 1 次 arena |
- Thread:线程占用*内存,主要是每个线程的线程栈,一般也主要关注线程栈占用空间,其他的管理线程占用的空间很小,可以忽略不计。
JVM 中比较消耗内存的数据区域之一,它与每个线程同时创建。 线程栈存储局部变量和部分结果,在方法调用中发挥着重要作用。根据 Oracle jdk 官网的说明,默认线程堆栈大小取决于平台,在大多数现代 64位操作系统中(Linux、MacOS),为 1 MB(jdk8、11、17 均一致)
每个线程栈占用大小受
-Xss限制,但是总大小没有限制,当线程数量没有限制时,分配给堆栈的总内存实际上是无限的。- 如果该值设置过小,可能会出现栈溢出,特别是在该线程内有递归、大的循环时出现溢出的可能性更大。
- 如果该值设置过大,可能会影响系统整体的内存。
-Xss 调优:JVM 的默认值一般偏高(1M),意在保证不受线程栈溢出的影响。可以根据项目情况和经验调小。
- 调研网络资料,建议栈深度设置在 3000-5000(调用深度)即 -Xss256K 或 -Xss512K,一般 512K 设置的比较多(https://zhuanlan.zhihu.com/p/243064867)
- 实验显示,-Xss512K 时,较简单的函数调研(无参)可以支持 16979 的调用深度(https://cloud.tencent.com/developer/article/1888586)
//总共 reserve 了 669351KB,commit 了 41775KB |
- 受
-XX:ReservedCodeCacheSize限制,主要对应我们比较熟悉的 Code Cache
为了在不同的平台上运行 JVM 字节码,JIT 编译器需要将代码编译转换为机器码。
当 JVM 编译字节码到汇编指令时,它保存这些指令在一个特殊的非堆区域,该区域称为 CodeCache。JVM 可以像管理其他区域一样管理 CodeCache。
-XX:InitialCodeCacheSize和-XX:ReservedCodeCacheSize标记决定了CodeCache 的初始值和可能的最大值。
- 根据 Oracle jdk 官网说明,initialCodeCacheSize 的默认值取决于平台,但不能比 OS 的 minimal page size 更小。对于 Unix和 windows,默认大小是 500KB
- 默认最大 Code Cache 大小为 240 MB; 如果使用选项 -XX:-TieredCompilation 禁用分层编译,则默认大小为 48 MB。
-XX:ReservedCodeCacheSize的限制为 2 GB, 否则会产生错误。- 如果 Code cache 内存占用超过上限,会停止JIT编译。同时还会收到 “CodeCache is full… The compiler has been disabled” 之类的告警消息
Code (reserved=50742KB, committed=17786KB) |
- Compiler:JIT 编译器(C1 C2 编译器)本身占用的空间和标记占用的内存,不受限制,一般比较小。
Compiler (reserved=159KB, committed=159KB) |
- Arena 数据结构占用空间,所有通过 arena 方式分配的内存。我们看到 Native Memory Tracking 中有很多通过 arena 分配的内存,这个就是管理 Arena 数据结构占用空间。
Arena Chunk (reserved=187KB, committed=187KB)(malloc=187KB) |
- JVM Tracing 占用*内存,所有采集占用的内存。包括 JVM perf 以及 JFR 占用的空间,如果开启了 JFR 则主要是 JFR 占用的内存。
Tracing (reserved=32KB, committed=32KB)(arena=32KB #1) |
- JVM GC 需要的数据结构与记录信息占用的空间,例如垃圾回收需要的 CardTable,标记数,区域划分记录,还有标记 GC Root 等等。这块内存可能会比较大,尤其是对于那种专注于低延迟的 GC,例如 ZGC。(ZGC 是一种以空间换时间的思路,提高 CPU 消耗与内存占用,但是消灭全局暂停)
GC (reserved=370980KB, committed=69260KB)(malloc=28516KB #8340) |
- Direct Buffer & Other:直接内存。在 NMT 中表现为 “Other”,意为:其他占用 (不是 JVM 本身而是操作系统的某些系统调用导致额外占的空间)。此项为我们大多数使用的非堆内存,也是「堆外内存」一词通常所指。
- 这里说的堆外内存主要针对
java.nio.DirectByteBuffer,这些对象的创建过程会通过 Unsafe 接口直接通过os::malloc来分配内存,然后将内存的起始地址和大小存到java.nio.DirectByteBuffer对象里,这样就可以直接操作这些内存。这些内存要么在 DirectByteBuffer 回收掉之后才有机会被回收,要么被程序员手动回收。
Other (reserved=12348KB, committed=12348KB)(malloc=12348KB #14) |
还有两项 NMT 没有列出,但非常重要的堆外内存:
- MMap Buffer:Java 文件映射内存大小,也是我们在 I/O 中经常用到的非堆内存,可以通过 JMX 监控
Java 中的内存映射缓存区(Memory-mapped buffer)是一种将文件或文件的一部分直接映射到程序内存中的技术。简单来说,内存映射缓存区允许 Java 程序在处理文件时像处理一个非常大的字节数组一样进行操作,而不用担心过多的 I/O 负担或频繁的磁盘访问。
- Native 分配:即直接调用 malloc 分配的,如 JNI 调用、磁盘与网络 io 操作等,可通过 pmap 命令、malloc_stats 函数观测。
以下几种堆外内存比较小,我们一般不会关心:
Logging:写 JVM 日志占用的内存
- 日志是指
-Xlog参数指定的日志输出 - Java 17 之后引入了异步 JVM 日志
-Xlog:async(https://bugs.openjdk.org/browse/JDK-8229517)
- 「异步日志」是指写日志动作与主应用程序是异步的,降低了写日志开销
- 异步日志所需的 buffer 也在这里
- 日志是指
日志用法:https://docs.oracle.com/en/java/javase/17/docs/specs/man/java.html#xlog-usage-examples
Logging (reserved=5KB, committed=5KB)(malloc=5KB #216) |
- Arguments:JVM 参数占用内存,我们需要保存并处理当前的 JVM 参数以及用户启动 JVM 的是传入的各种参数(有时候称为 flag)。
Arguments (reserved=31KB, committed=31KB)(malloc=31KB #90) |
- Safepoint:JVM 安全点占用内存,是固定的两页内存(这个页大小与操作系统相关),用于 JVM 安全点的实现,不会随着 JVM 运行时的内存占用而变化。
Safepoint (reserved=8KB, committed=8KB)(mmap: reserved=8KB, committed=8KB) |
- Synchronization:Java 同步机制(例如
synchronized,还有 AQS 的基础LockSupport)底层依赖的 C++ 的数据结构,系统内部的 mutex 等占用的内存。
Synchronization (reserved=56KB, committed=56KB)(malloc=56KB #789) |
- Serviceability:JVM TI 相关内存。
JVMTI 是 Java 虚拟机工具接口(Java Virtual Machine Tool Interface)的缩写。它是 Java 虚拟机(JVM)的一部分,提供了一组 API,使开发人员可以开发自己的 Java 工具和代理程序,以监视、分析和调试 Java 应用程序。
JVMTI API 是一组 C/C++ 函数,可以通过 JVM TI Agent Library 和 JVM 进行交互。开发人员可以使用 JVMTI API 开发自己的 JVM 代理程序或工具,以监视和操作 Java 应用程序。例如,可以使用 JVMTI API 开发性能分析工具、代码覆盖率工具、内存泄漏检测工具等等。
- 这里的内存就是调用了 JVMTI API 之后 JVM 为了生成数据占用的内存。
Serviceability (reserved=1KB, committed=1KB)(malloc=1KB #18) |
- String Deduplication:Java 字符串去重占用内存。
- 这是一种字符串去重的机制,该机制只有在 G1GC 中才能使用(https://openjdk.org/jeps/192),所以默认是关闭的。可以通过
-XX:+UseStringDedupl``ication+-XX:UseG1GC来启用。
String Deduplication 实现:
- 当 G1 工作的时候,会访问堆上存活的对象。对每一个访问的对象都会检查是否是候选的要去重的 string 对象。
- 如果是,把这个对象的一个引用插入到队列中等待后续的处理。一个去重的线程在后台运行,处理这个队列。当有空闲 CPU 周期可用时,该线程会扫描堆,查找重复的字符串。
- 使用一个 hashtable 来记录所有的被 string 对象使用的不重复的 char 数组。当去重的时候,会查这个 hashtable,来看堆上是否已经存在一个一模一样的 char 数组。当找到两个具有相同值的不同 string 时 ,将对它们进行重复数据删除。
- 仅处理在一定的最小 GC 周期数(默认为 3 个)后幸存下来的字符串,以避免在非常短命的对象上浪费精力,从统计上看,这些对象很有可能成为垃圾。
- 如果存在一模一样的 char 数组,string 对象会被调整为引用那个数组,释放对原来数组的引用,最终被 G1 回收掉。
- 如果不存在,char 数组会被插入到 hashtable,这样以后其他相同的字符串可以共享该数组。
与 string.intern() 的区别
- String Deduplication:如果有 1000 个不同的 String 对象,它们都具有相同的内容“abc”,JVM 可以让它们在内部共享相同的 char[],但是仍然有 1000 个不同的 String 对象。
- String.intern():使用 intern(),将只有一个 String 对象。 因此,如果关心节省内存,那么 intern() 会更好。 它将节省空间以及 GC 时间。但缺点是有时需要手动调用
intern()(https://stackoverflow.com/questions/32854968/java-8-string-deduplication-vs-string-intern、https://dzone.com/articles/duplicate-strings-how-to-get-rid-of-them-and-save、[JEP 192: String Deduplication in G1](http://openjdk.java.net/jeps/192))
String Deduplication (reserved=1KB, committed=1KB)(malloc=1KB #8) |
- Internal:JVM 内部不属于其他类别的内存占用,不会很大
Internal (reserved=1373KB, committed=1373KB)(malloc=1309KB #6135) |
- Native Memory Tracking*:开启 Native Memory Tracking 本身消耗的内存
Native Memory Tracking (reserved=8426KB, committed=8426KB)(malloc=325KB #4777) |
非堆内存与 GC
结论:理论上非堆内存中,只有 DirectBuffer(堆外内存)可以被 gc 回收。其他部分都直接由操作系统/ native 库管理。在编程中:
- 对于 DirectBuffer ,要注意结合
-XX:MaxDirectMemorySize与 full gc 控制内存泄漏问题,必要时手动管理 - 对于其他非堆内存,要手动做好内存分配去配(malloc/free)管理
由于 DirectBuffer(堆外内存)可以通过 JVM 的 DirectBuffer 对象管理,因此 gc 可以通过回收 DirectBuffer 对象来回收其关联的堆外内存。这也是为什么会有如下现象:
DirectByteBuffer 对象本身其实是很小的,但是它后面可能关联了一个非常大的堆外内存,因此我们通常称之为『冰山对象』。
ygc 时会将新生代里的不可达的 DirectByteBuffer 对象及其堆外内存回收,但是无法对 old 里的 DirectByteBuffer 对象及其堆外内存进行回收。因此如果有大量的 DirectByteBuffer 对象移到了 old,但是又一直没有做 full gc,而只进行 ygc,且 -XX:MaxDirectMemory 没有正确设置,那么可能会发生堆外内存泄漏。
补充问题:对于 g1 这种 mixed gc 也可以回收老年代 region 的 gc 算法,是不是这个问题会缓解很多?
实验:手动添加 100_000_00 次堆外内存,每次添加 1024B,同时手动添加 10_000 次堆内存以触发 mixed gc/full gc,并将堆外内存晋升到老年代。对比 CMS 和 G1 的堆外内存回收情况。
环境:-XX:+UseG1GC/-XX:+UseConcMarkSweepGC -Xmx4g -XX:MaxDirectMemorySize=2g
结论 (将两种 GC 下,堆外内存 used 情况画成折线图):
- 在内存低负载情况下(x 轴 1471 之前),G1 对于堆外内存的控制优于 CMS*。猜测这是由于此时两种 GC 的 full gc 都不多,而 G1 的 mixed gc 能回收老年代 region,CMS 的 young gc 则不行,因此 G1 表现优于 CMS
- 在内存高负载情况下(x 轴 1471 之后),*CMS 对于堆外内存的控制优于 G1。猜测这是由于此时负载太高了,CMS 主要进行 full gc。而 G1 在 full gc 之余,优先会 mixed gc,而 mixed gc 对于内存的回收效果显然不如 full gc,因此 CMS 表现优于 G1
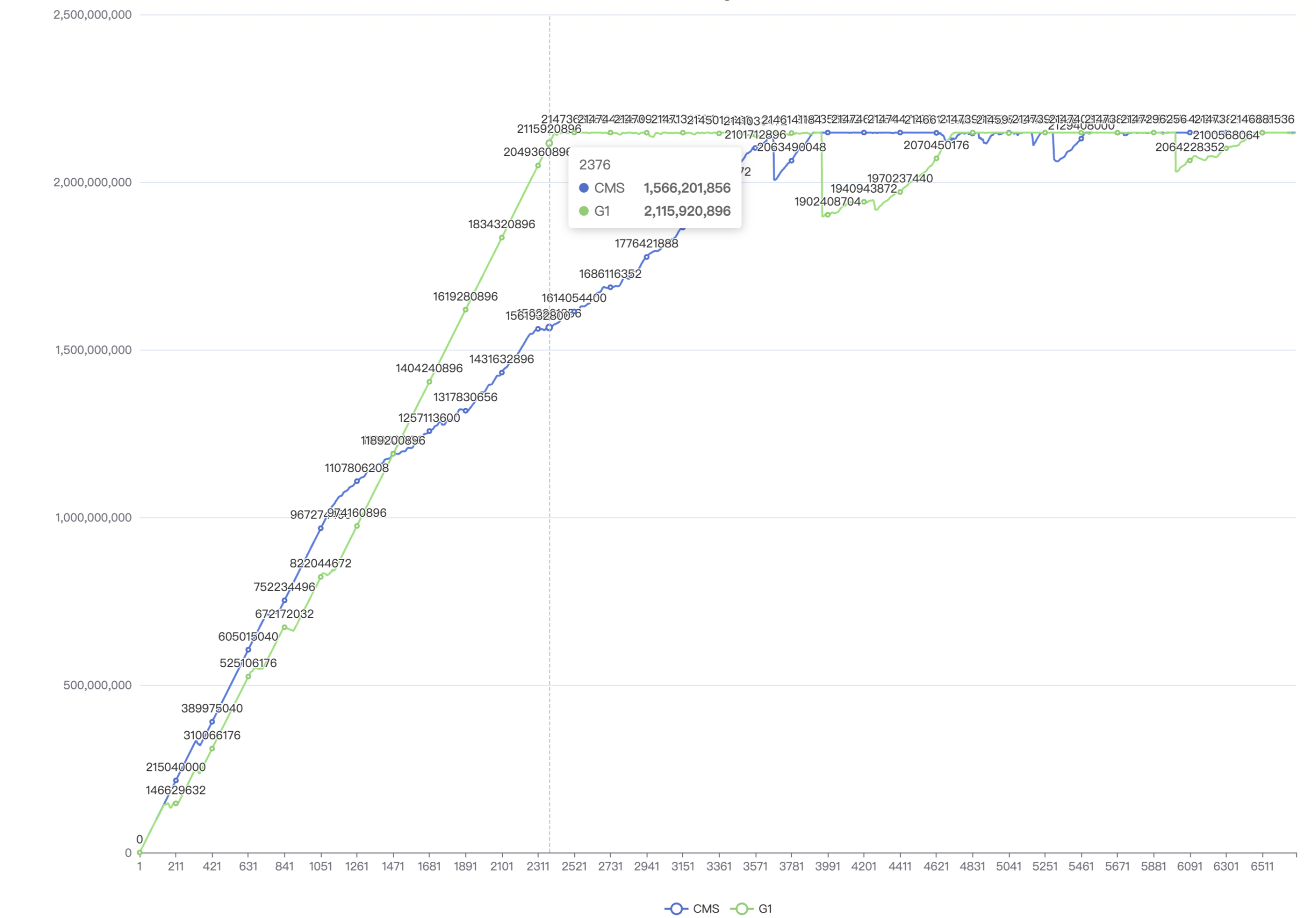
因此我们认为:对于堆外内存,只有 full gc 或者 System.gc() 才能比较彻底的回收,一旦一直触发不了 fullgc 或 System.gc(),后果会比较严重。
糟糕的是如果 JVM 分配的堆内存空间很大,以至于很少发生老年代的 GC (或者 Full GC),可能会导致一些 DirectByteBuffer 对象虽然已经处于不可达的状态但是却长时间无法被 GC 掉。然后这些对象会一直持有其指向的堆外内存,直到下面的清理方法被调用:
((DirectBuffer)buf).cleaner().clean(); |
虽然 GC 会销毁 DirectByteBuffer 之前调用该方法,但是,如上所述,它可能为时已晚。
如果我们对管理堆外内存的代码了如指掌,则可以显式调用上述方法。 否则,防止堆外内存过度使用的方法是减小堆内存的大小从而使得 GC 更加频繁,或者依赖-XX:MaxDirectMemorySize的 OOM 检查进行 System.gc()。
实验验证:在机器上指定 G1 GC(JDK 11),不断手动添加堆外内存。通过控制 -Xmx 和 -XX:MaxDirectMemory 来研究堆外内存受 GC 的影响。
实验代码:
public static void printMemInfo() {
System.out.println("==================================Mem===================================");
ManagementFactory.getPlatformMXBeans(MemoryPoolMXBean.class).stream()
.forEach(
e -> {
System.out.println("name: " + e.getName() + " / info: " + e.getUsage());
});
ManagementFactory.getPlatformMXBeans(BufferPoolMXBean.class).stream()
.forEach(
e -> {
System.out.println(
"name: "
+ e.getName()
+ " total: "
+ e.getTotalCapacity()
+ " used: "
+ e.getMemoryUsed());
});
System.out.println("==================================GC===================================");
ManagementFactory.getPlatformMXBeans(GarbageCollectorMXBean.class).stream()
.forEach(
e -> {
System.out.println(e.getName() + ": " + e.getCollectionTime());
});
}
public static void main(String[] args) throws RunnerException, IOException {
List<byte[]> heapMem = new ArrayList<>();
long startTime = System.currentTimeMillis();
for (int i = 0; i < 100_000_00; i++) {
// 通过增加 heap mem 来触发 full gc 或 mixed gc(G1)
if (i % 100 == 0) {
byte[] bytes = new byte[1024];
heapMem.add(bytes);
printMemInfo();
}
// 手动不断分配堆外内存
ByteBuffer byteBuffer = ByteBuffer.allocateDirect(1024);
}
printMemInfo();结果如下:
name: CodeHeap 'non-nmethods' / info: init = 2555904(2496K) used = 1121280(1095K) committed = 2555904(2496K) max = 5849088(5712K)
name: Metaspace / info: init = 0(0K) used = 8045576(7857K) committed = 8519680(8320K) max = -1(-1K)
name: CodeHeap 'profiled nmethods' / info: init = 2555904(2496K) used = 1836672(1793K) committed = 2555904(2496K) max = 122896384(120016K)
name: Compressed Class Space / info: init = 0(0K) used = 747256(729K) committed = 917504(896K) max = 1073741824(1048576K)
name: G1 Eden Space / info: init = 27262976(26624K) used = 60817408(59392K) committed = 247463936(241664K) max = -1(-1K)
name: G1 Old Gen / info: init = 241172480(235520K) used = 251638016(245740K) committed = 729808896(712704K) max = 2147483648(2097152K)
name: G1 Survivor Space / info: init = 0(0K) used = 34603008(33792K) committed = 34603008(33792K) max = -1(-1K)
name: CodeHeap 'non-profiled nmethods' / info: init = 2555904(2496K) used = 871168(850K) committed = 2555904(2496K) max = 122912768(120032K)
name: mapped total: 0 used: 0
name: direct total: 659278848 used: 659278848
// 限制最大堆内存 512M,堆外内存 1G
name: CodeHeap 'non-nmethods' / info: init = 2555904(2496K) used = 1120000(1093K) committed = 2555904(2496K) max = 5849088(5712K)
name: Metaspace / info: init = 0(0K) used = 8051904(7863K) committed = 8519680(8320K) max = -1(-1K)
name: CodeHeap 'profiled nmethods' / info: init = 2555904(2496K) used = 1885056(1840K) committed = 2555904(2496K) max = 122896384(120016K)
name: Compressed Class Space / info: init = 0(0K) used = 747256(729K) committed = 917504(896K) max = 1073741824(1048576K)
name: G1 Eden Space / info: init = 27262976(26624K) used = 157286400(153600K) committed = 191889408(187392K) max = -1(-1K)
name: G1 Old Gen / info: init = 241172480(235520K) used = 187691464(183292K) committed = 319815680(312320K) max = 536870912(524288K)
name: G1 Survivor Space / info: init = 0(0K) used = 3145728(3072K) committed = 3145728(3072K) max = -1(-1K)
name: CodeHeap 'non-profiled nmethods' / info: init = 2555904(2496K) used = 840192(820K) committed = 2555904(2496K) max = 122912768(120032K)
name: mapped total: 0 used: 0
name: direct total: 452782080 used: 452782080可以看到:当堆内存阈值变小时,GC 更加频繁,堆外内存得到了更好的回收。但是这是以减小堆内存为代价。
对于 IoTDB 的启示是:
- 在保证堆内存够用的前提下, -Xmx 尽量小对于堆外内存回收是有用的。
- 尽管如此,对于堆外内存,手动管理回收是更安全的方式。即在合适的时机(如 close() 方法)调用
DirectByteBuffer.getCleaner().clean(),手动清理堆外内存,而不是交给 GC(finalize() 方法)
我们通常通过-XX:MaxDirectMemorySize来指定最大的堆外内存大小,当使用达到了阈值的时候将调用System.gc 来做一次 full gc,以此来回收掉没有被使用的堆外内存。
- 因此不要轻易显示关闭 System.gc()
Java 进程内存占用 “misunderstanding”
明晰了 Java 内存组成,但实际观测时还是会发现:Java 实际占用内存与认知存在一定差距。这是因为存在一些“misunderstanding”:
JVM commit 的内存与实际占用内存的差异
首先明确 commit、reserve 等概念,对这些比较熟悉的可以直接跳到下一部分了(https://stackoverflow.com/questions/31173374/why-does-a-jvm-report-more-committed-memory-than-the-linux-process-resident-set;翻译起来总感觉不太准确,就直接贴英文了)
- JVM 自身监控工具里常见的内存概念:
Used Heap: the amount of memory occupied by live objects according to the last GC
Reserved: The total address range that has been pre-mapped via mmap for a particular memory pool. The reserved memory consists of PROT_NONE mappings, which are guaranteed to not be backed by physical memory
“PROT” 是 Linux 里的概念,意为 protection,表示的是对内存映射区域的保护,包括 PROT_READ(可读),PROT_WRITE(可写), PROT_EXEC(可执行)和 PROT_NONE,即既不可读也不可写更不可执行
意思就是说,reserved 是通过 PROT_NONE 分配的内存,即在虚存中分配的空间在 kernel 的 vma structs 有 entries,因此不会被其他 mmap/malloc calls 所使用。如果其他进程访问这些 reserved 的内存会造成 page fault(SIGSEGV)
Committed: Address ranges that have been mapped with something other than PROT_NONE. They may or may not be backed by physical or swap due to lazy allocation and paging.
Committed-but-not-backed-by-storage memory has been mapped with - for example - PROT_READ | PROT_WRITE but accessing it still causes a page fault. But that page fault is silently handled by the kernel by backing it with actual memory and returning to execution as if nothing happened.
- Linux 监控 Java 进程,常见的内存概念:
Resident: Pages which are currently in physical RAM. This means code, stacks, part of the committed memory pools but also portions of mmaped files which have recently been accessed and allocations outside the control of the JVM.(即真实使用的物理内存)
Virtual: The sum of all virtual address mappings. Covers committed, reserved memory pools but also mapped files or shared memory. This number is rarely informative since the JVM can reserve very large address ranges in advance or mmap large files.(就是说这个数值没啥参考价值)
我们经常可以在各种监控工具(JMX、上文提到的 NMT 等)看到 JVM commit 的内存。实际上 JVM commit 的内存与在 Linux OS 上的实际占用内存(RSS)是有差异的:
JVM 中大块内存,基本都是先 reserve 一大块,之后 commit 其中需要的一小块,然后开始读写处理内存。
- commit 之后,内存并不是立刻被分配了物理内存*,而是真正往内存中 store 东西(写动作)的时候,才会真正映射物理内存,如果是 load 读取也是可能不映射物理内存的。(所谓 lazy allocation)
- 还有的差异,主要来源于在 uncommit 之后,系统可能还没有来的及将这块物理内存真正回收。
所以,JVM 认为自己 commit 的内存,与实际系统分配的物理内存,可能是有差异的:可能 JVM 认为自己 commit 的内存比系统分配的物理内存多。
为什么啥都没干,JVM 启动后内存一直在涨
有的时候这是正常的,原因正是 1.3.1 所提到的。
比如:如果你使用的是 SerialGC,ParallelGC 或者 CMS GC,老年代的内存在有对象晋升到老年代之前,可能是不会映射物理内存的,虽然这块内存已经被 commit 了。如果你用的是 ZGC,G1GC,或者 ShenandoahGC,那么内存用的会更激进些(主要因为分区算法划分导致内存被写入),这是你在换 GC 之后看到物理内存内存快速上涨的原因之一。
假如 JVM 为堆申请的内存是 4.8G,JVM commit 了 4.8G。但在启动后 JVM 一开始可能实际只使用了 3G 内存,由于前面刚提到的 lazy allocation 机制,导致剩下的 1.8G 是不会映射物理内存的,虽然这块内存已经被 commit 了, Linux 实际只分配了 3G。
然后在 gc 时,由于会复制存活对象到堆的空闲部分,如果正好复制到了以前未使用过的区域,就又会触发 Linux 进行内存分配,故一段时间内内存占用会越来越多,直到堆的所有区域都被 touch 到。
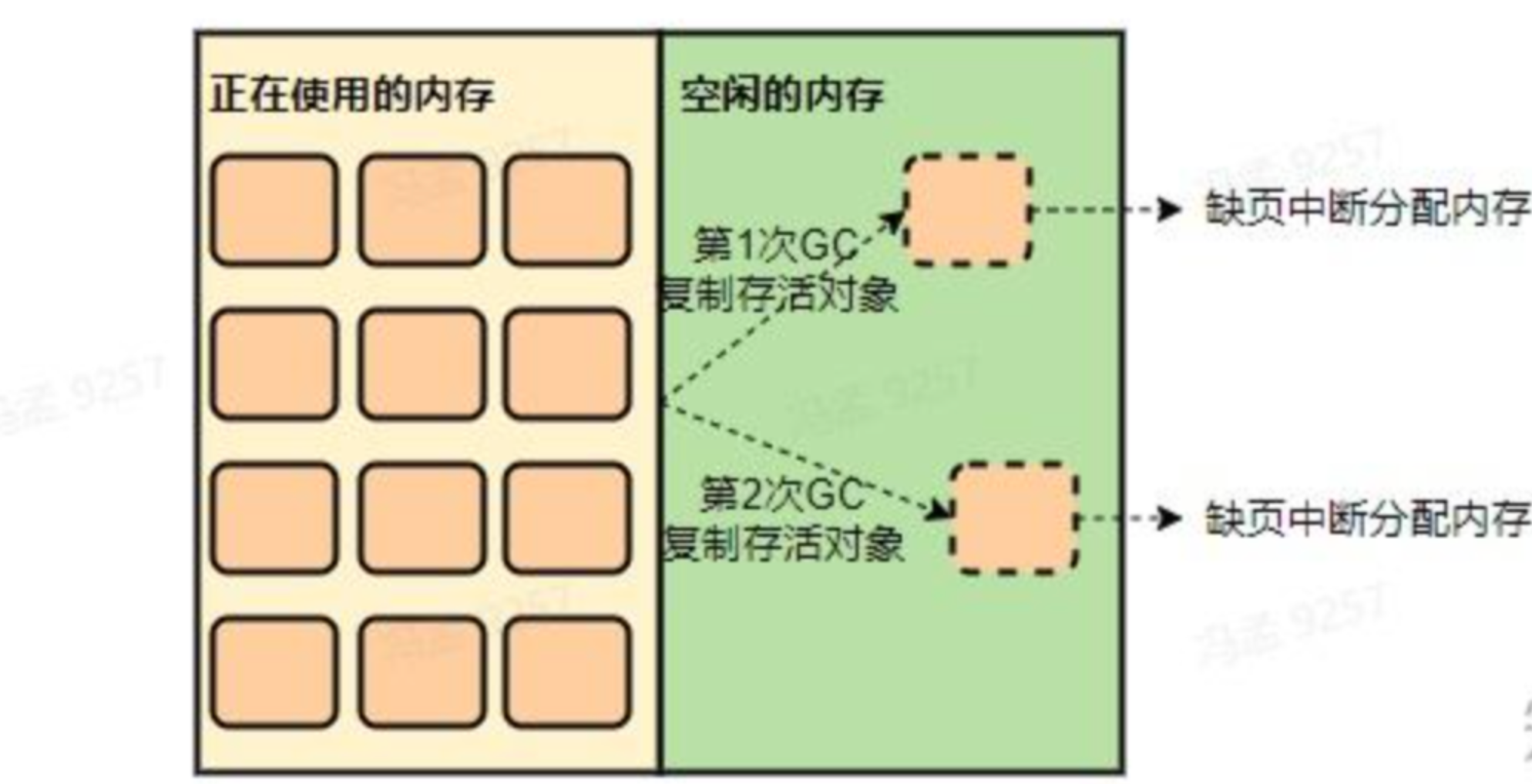
而通过添加JVM参数-XX:+AlwaysPreTouch(默认关闭),可以在 Commit 内存后立刻写入 0 来强制操作系统分配内存,使得堆区域全都被分配物理内存。而由于 Java 进程主要活动在堆内,故后续内存就不会有很大变化了。
- 这种优化叫做 “pre-zeroing”,即将内存全部预填 0,减少页分配开销,这篇论文有详细描述
无此参数可以提高内存利用度,加此参数则会使应用运行得更稳定。
- 在 jdk9 以前,理论上 AlwaysPreTouch 打开后会降低项目启动时间1~2个数量级(https://www.jianshu.com/p/a8356d03ac8f)。在 jdk9 及之后,由于 jvm 对 preTouch 加入了并行优化(https://bugs.openjdk.org/browse/JDK-8157952),AlwaysPreTouch 对项目启动时间的影响大幅降低。
AlwaysPreTouch 对 IoTDB 启动性能影响的实验:
- 环境:Mac M2 pro JDK 8/11
- ConfigNode:1068ms(加 AlwaysPreTouch)
- DataNode:1369ms(加 AlwaysPreTouch)
- ConfigNode:999ms(不加 AlwaysPreTouch)
- DataNode:1374ms(不加 AlwaysPreTouch)
- 环境:fit 服务器 JDK 8
- ConfigNode:1044ms(加 AlwaysPreTouch)
- DataNode:1349ms(加 AlwaysPreTouch)
- ConfigNode:1031ms(不加 AlwaysPreTouch)
- DataNode:1430ms(不加 AlwaysPreTouch)
结论:对 IoTDB 的启动几乎没有性能开销影响,对运行时理论没有性能开销。
glibc 内存去配机制对 JVM 的影响
JVM 等原生应用程序调用的 malloc、free 函数,实际是由基础 C 库 glibc 提供的,而 linux 系统则提供了 brk、mmap、munmap 这几个系统调用来分配虚拟内存,所以 libc 的 malloc、free 函数实际是基于这些系统调用实现的。
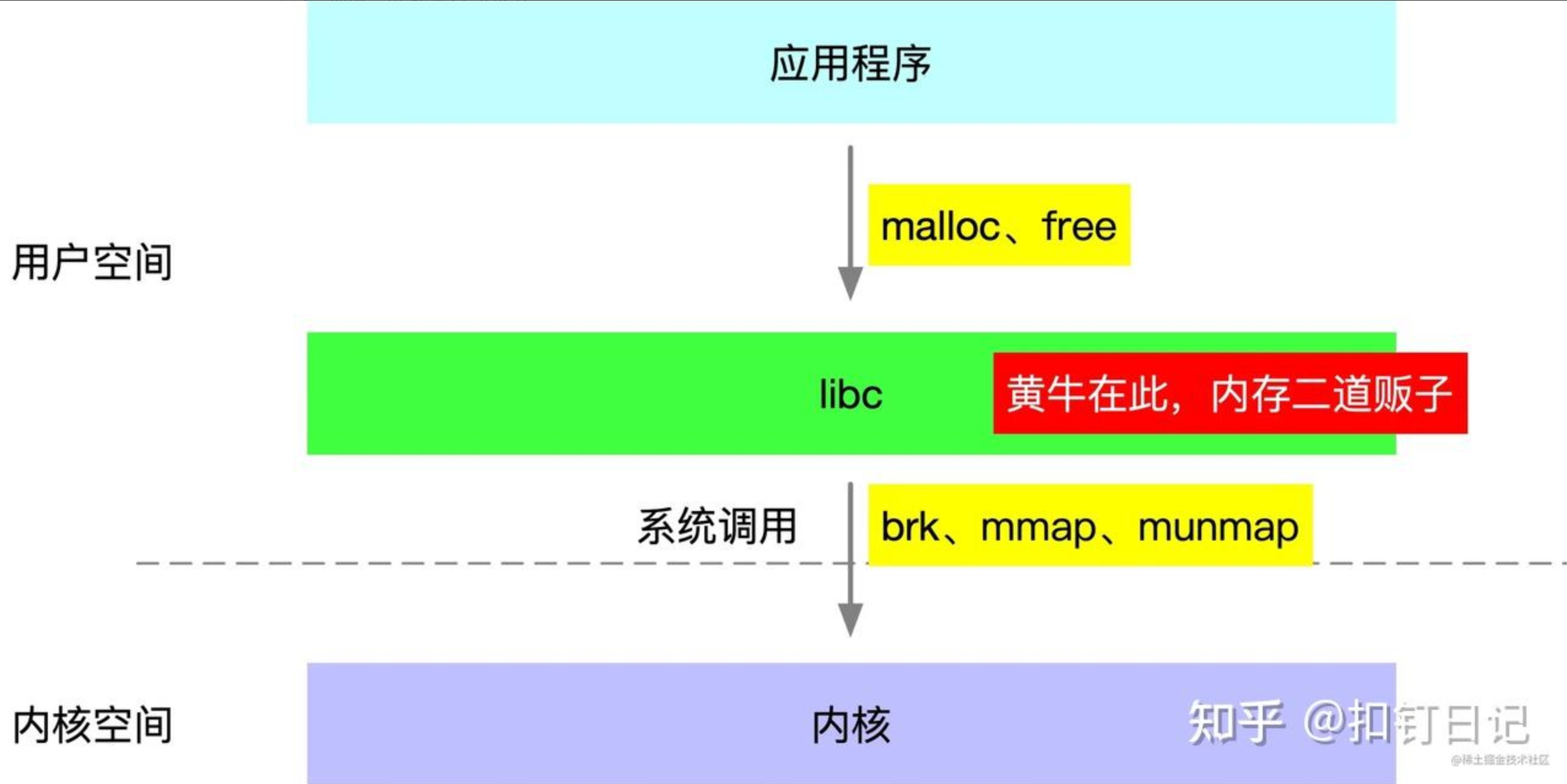
由于系统调用有一定的开销,为减小开销,glibc 实现了一个类似内存池的机制,在 free 函数调用时将内存块缓存起来不归还给 linux,直到缓存内存量到达一定条件才会实际执行归还内存的系统调用。
节选自 glibc 资料:
用户调用 free 函数释放内存的时候,ptmalloc 并不会立即将其归还操作系统,而是将其放入空闲链表 (bins) 中,这样下次再调用 malloc 函数申请内存的时候,就会从 bins 中取出一块返回,这样就避免了频繁调用系统调用函数,从而降低内存分配的开销。
因此,Java 进程占用内存有时比理论上要大些,一定程度上是正常的。(这点对于理解 Java 进程在操作系统中的占用内存非常重要)
glibc Allocator 的负面影响: RSS 以 64MB 为增量进行递增
这是最不容易发现但是可能导致堆外内存不符合预期的情况。在笔者调研时,中英文互联网均有这种 case:pmap 时,发现 java 进程分配了大量 64 MB 大小的内存块。
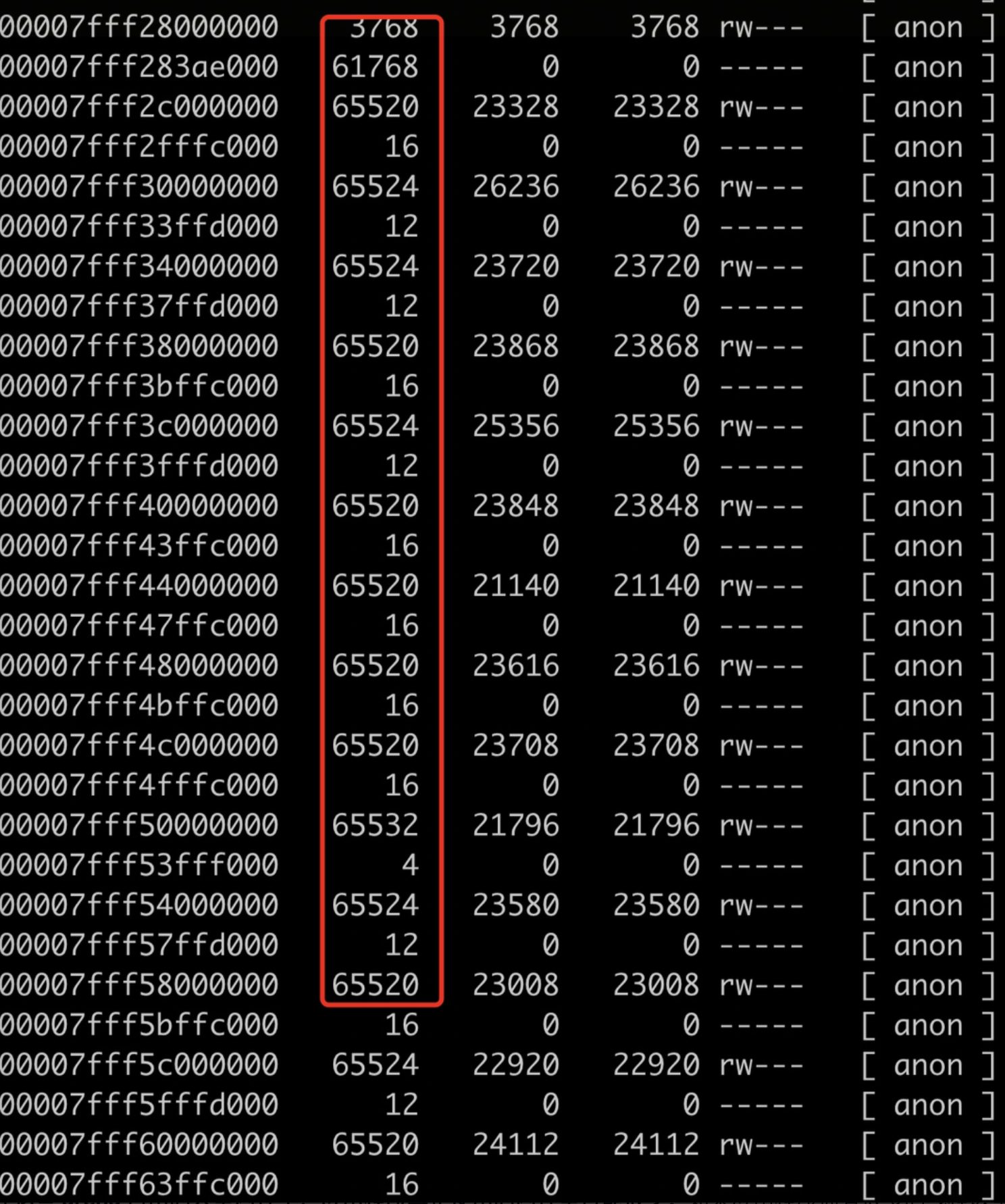
这是由于 Linux 中,glibc 对具有大量并发线程的程序进行了优化,通过避免竞争调高了程序运行速度。而提速是通过为每一个核来维护一个内存池达到的。
这种优化方式的本质是:操作系统会为给定的进程捕获(抢占)内存,每个内存块的大小为 64MB,这样的内存块被叫做 arena,glibc 再根据应用需要将 arena 切割为小块进行实际分配。当使用 pmap 分析进程内存时,这些清晰可见(如上图)
每一个 arena 都只能由特定的 CPU-Core 来进行访问,所以在同一时间点至多会有一个线程会进行访问。然后每个 arena 内部通过 malloc 来使用内存空间。每个 CPU-Core 至多可以分配一定数量的 arena,默认是 8 个。
但是在这些 arena 占用的大量内存中,应用程序真正使用的内存量可能很少。如果应用程序拥有很多的线程数量,并且执行程序的机器CPU核数也很多,那么通过分配 arena 这种方式占用的内存总量可能非常大。比如在CPU核数为16的机器上,arena 占用的内存量会达到 16 * 8 * 64 MB = 8GB。
映射到 Java 程序上,就是:JVM 实际只需要一小部分内存,但是 RSS 不断增长的问题就会显现出来。因此会导致 Java 实际使用的内存小于 Linux 系统分配的内存。
解决:
- 可以通过
MALLOC_ARENA_MAX环境变量来调整arena的最大数量,加上这个环境变量启动 java 进程。并且可以通过cat /proc/<JVM_PID>/environ来检查是否配置成功。
# Some versions of glibc use an arena memory allocator that causes |
但是 Linux的一个BUG 表明设置
MALLOC_ARENA_MAX可能无法生效。不过这个问题已经在glibc 2.12版本进行了修复(参考Linux update release notes mentioning BZ#769594),如果使用的仍旧是未修复版本,那么需要注意这一点。
- 替换 glibc 为碎片整理更友好的 tcmalloc(google) 和 jemalloc(facebook)
// 用法: |
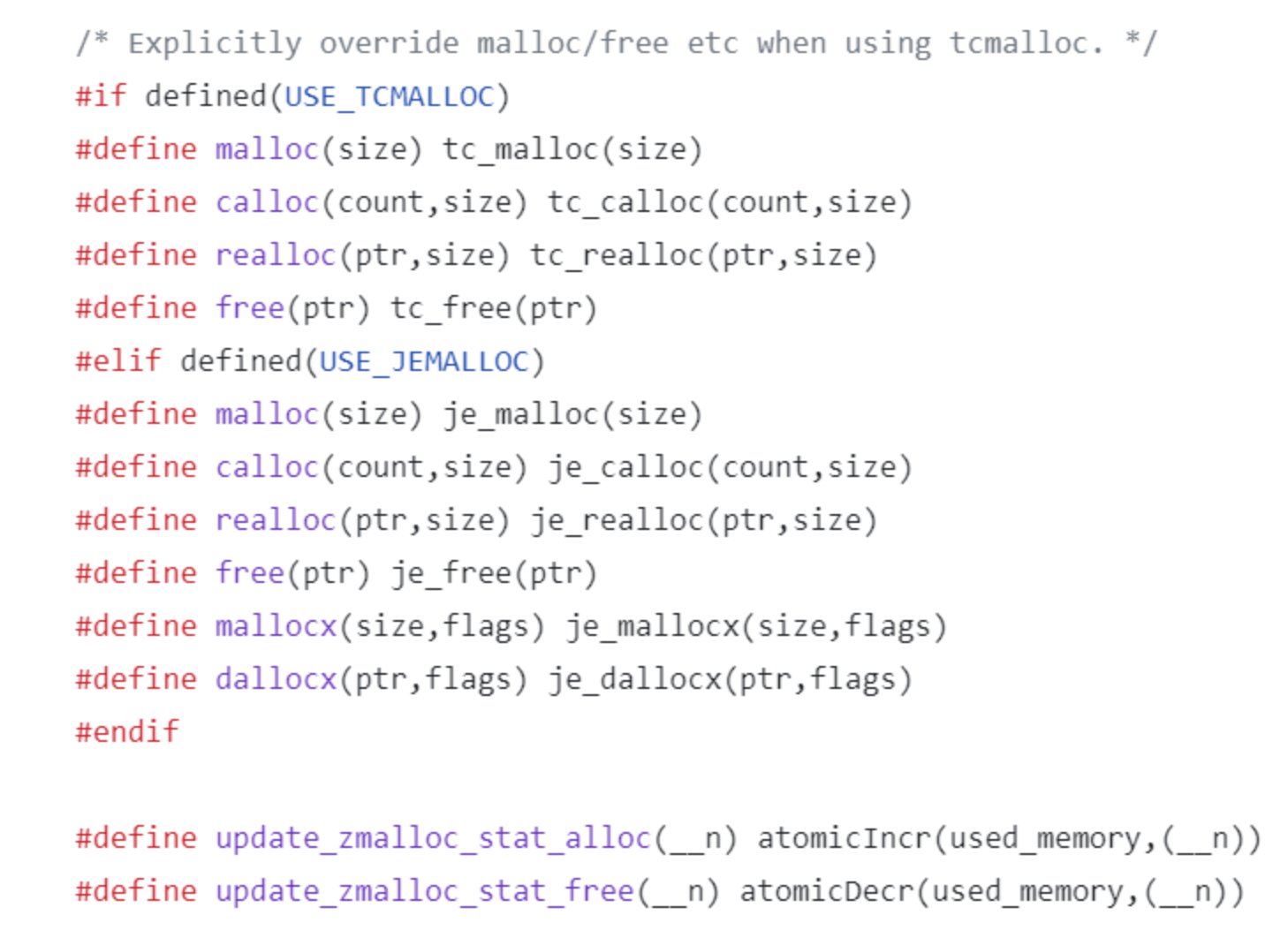
- Redis 使用了 tcmalloc 和 jemalloc 作为内存管理库的 option,在 zmalloc.c 源码中可以看到 redis 用二者覆盖了 glibc(https://blog.csdn.net/u010144805/article/details/80353851)
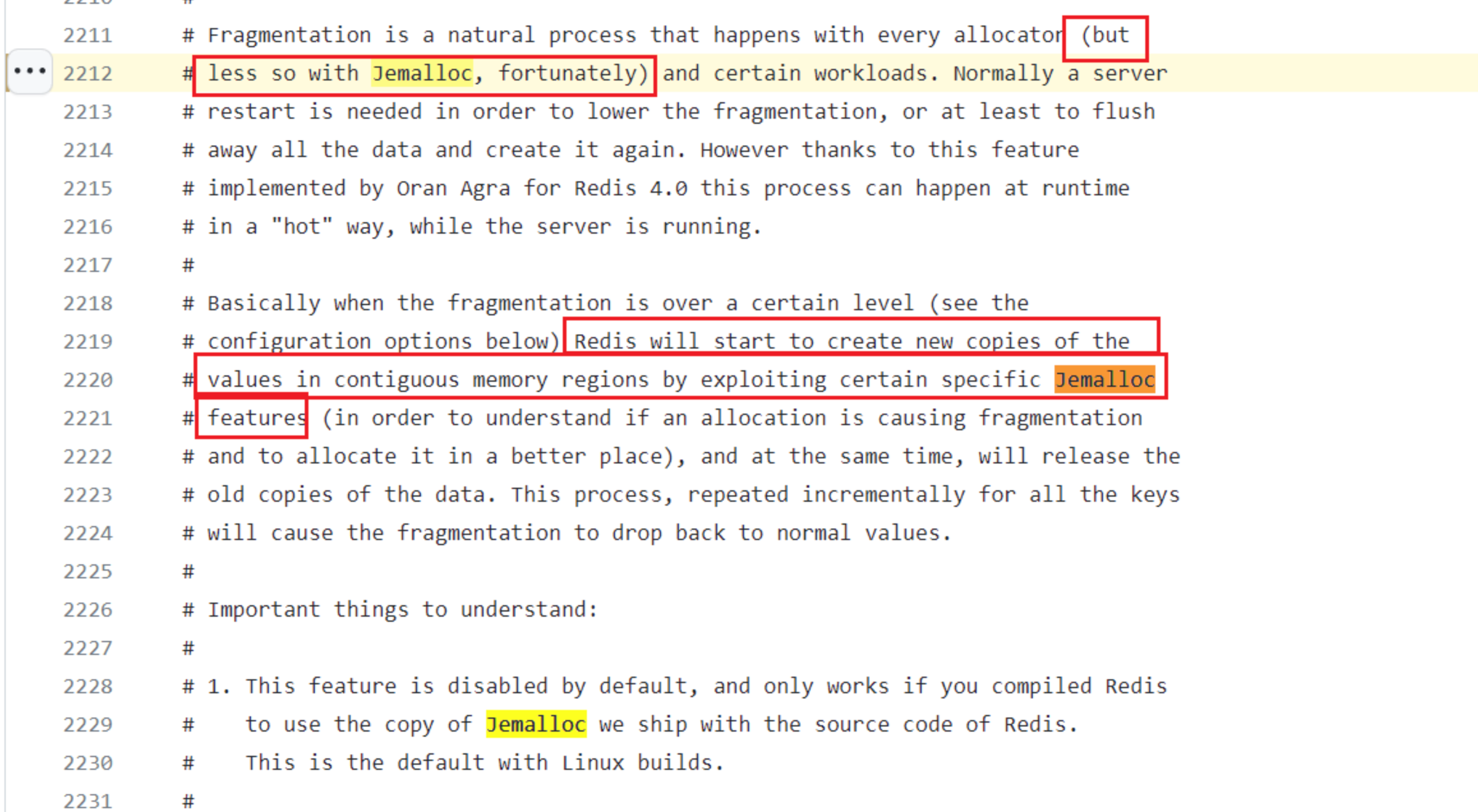
- 甚至 Redis 直接内置了 jemalloc 的源码,作为 deps 来覆盖 glibc。虽然 Redis 默认用 glibc,但从 Redis 源码的注释中可以看到,Redis 团队是鼓励使用 jemalloc 的
调研时,也发现互联网不乏喊 glibc 坑爹的声音,关于 tcmalloc、jemalloc 与 glibc 的性能对比测试比比皆是(https://www.zhihu.com/question/54823155),基本均表明 tcmalloc、jemalloc 不仅碎片整理比 glibc 优越,性能也有优势😳。
以下两点比较少见,主要贴出来供参考学习,感兴趣的可以看看
DirectByteBuffer 的 capacity 之和大于 MaxDirectMemorySize
有时我们设置了-XX:MaxDirectMemorySize,但是统计时将所有 DirectByteBuffer 对象的 capacity 加起来发现大于了-XX:MaxDirectMemorySize。
关注 DirectByteBuffer 里的这两个函数:
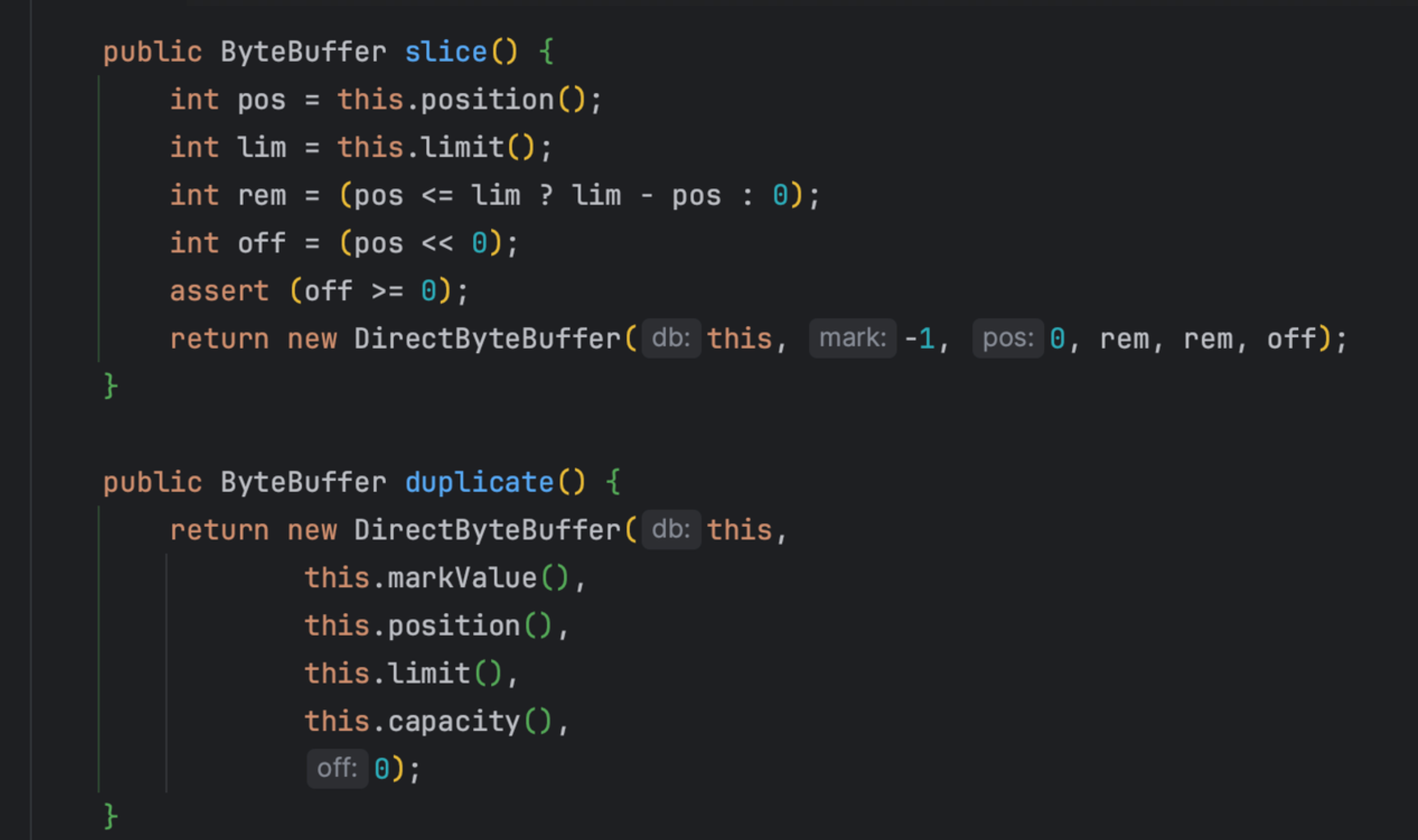
slice是从一块已知的内存里取出剩下的一部分,用一个新的 DirectByteBuffer 对象指向它,而 duplicate 就是创建一个现有 DirectByteBuffer 的全新副本,各种指针都一样。
- 这两个函数 IoTDB 都有用到
从这两个函数创建出来的 DirectByteBuffer 实际上指向的是已存在的堆外内存(相当于复用)。所以如果我们做统计的时候如果仅仅将所有 DirectByteBuffer 对象的 capacity 加起来,那可能会导致算出来的结果偏大不少。
因此我们统计的时候可以注意这点,不要简单 add 所有DirectByteBuffer 对象的 capacity*。
MaxDirectMemorySize 与 RealDirectMemoryBufferSize
首先明确:-XX:MaxDirectMemorySize是如何限制 DirectMemory 的?
我们从 java 层面创建 DirectByteBuffer 对象,一般都是通过 ByteBuffer 的 allocateDirect 方法

这个方法会调用该构造函数:
DirectByteBuffer(int cap) { // package-private |
而这个构造函数里的Bits.reserveMemory(size, cap)方法会做堆外内存的阈值 check
// These methods should be called whenever direct memory is allocated or |
该方法会检查已经分配的内存是否超过阈值,如是,会触发一次 gc 动作,并重新做一次分配,如果还是超过阈值,那将会抛出 OOM,因此分配动作会失败。
结论:只有通过 DirectByteBuffer(int cap) 构造函数分配的堆外内存,会被检查并受MaxDirectMemorySize限制。
那么如果通过其他构造函数分配堆外内存,显然就不会受MaxDirectMemorySize的限制,比如:
在 jvm 里可以通过 jni 方法回调 DirectByteBuffer 的构造函数,这个构造函数是
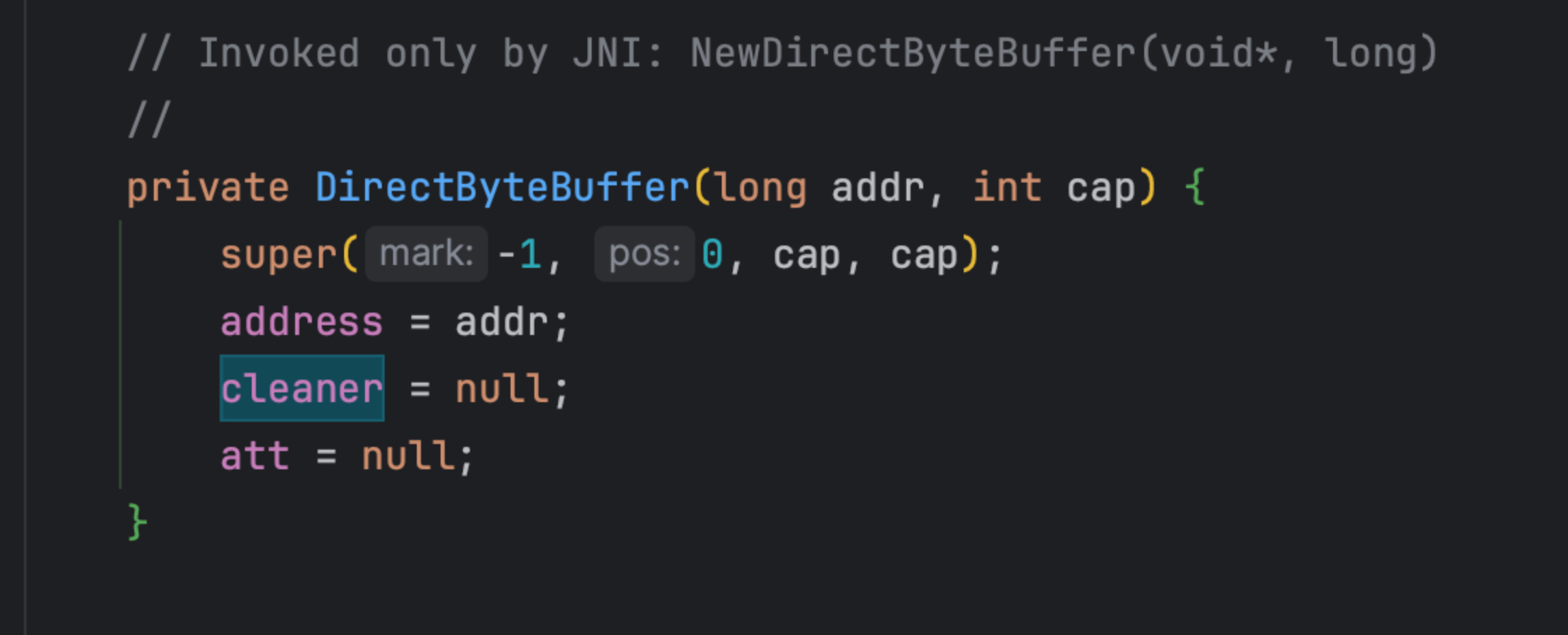
而调用这个构造函数的 jni 方法是NewDirectByteBuffer
想象这么种情况,我们写了一个 native 方法,里面分配了一块内存,同时通过上面这个方法和一个 DirectByteBuffer 对象关联起来,那从 java 层面来看这个 DirectByteBuffer 确实是一个有效的占有不少 native 内存的对象,但是这个对象后面关联的内存完全绕过了MaxDirectMemorySize 的 check。所以造成:明明设置了MaxDirectMemorySize,但是发现 DirectByteBuffer 关联的堆外内存其实是大于它的。
- IoTDB 的依赖 [zstd-jni](https://github.com/search?q=repo%3Aluben%2Fzstd-jni newDirectByteBuffer&type=code) 有声明该 jni 方法,不过 IoTDB 并未调用。这里贴出来主要参考学习~
【监控】如何监控?
JMX
- 使用 MemoryPoolMXBean 监控分代堆内存 + Code Cache + Metaspace

- 使用BufferPoolMXBean 监控 Direct + mmap

- 缺点:对于非堆内存的监控不全,只覆盖了 code cache、metaspace、direct、mapped。
反射
- 直接读取
java.nio.Bits来监控 direct 的TOTAL_CAPACITY与RESERVE_MEMORY。实测跟 JMX 的total、used效果一致
try { |
工具
Java 工具
Jmap
互联网上有非常丰富的资料,可以自行参考
- 优点:随时使用;没有性能损耗;适合监控堆内存,还可以监控类加载情况等,功能强大,可以找出 OOM 瓶颈
- 缺点:对非堆内存的监控有欠缺,只能看到 Metaspace 的内存情况
JProfiler
互联网上有非常丰富的资料,可以自行参考
- 优点:功能强大,可以找出 OOM 到底在哪个类发生
- 缺点:对 native 等非堆内存的监控有欠缺
Jcmd
- 监控堆内存使用信息(G1 GC)和 Metaspace

- 监控 Code Cache
- 查看堆使用情况的统计信息
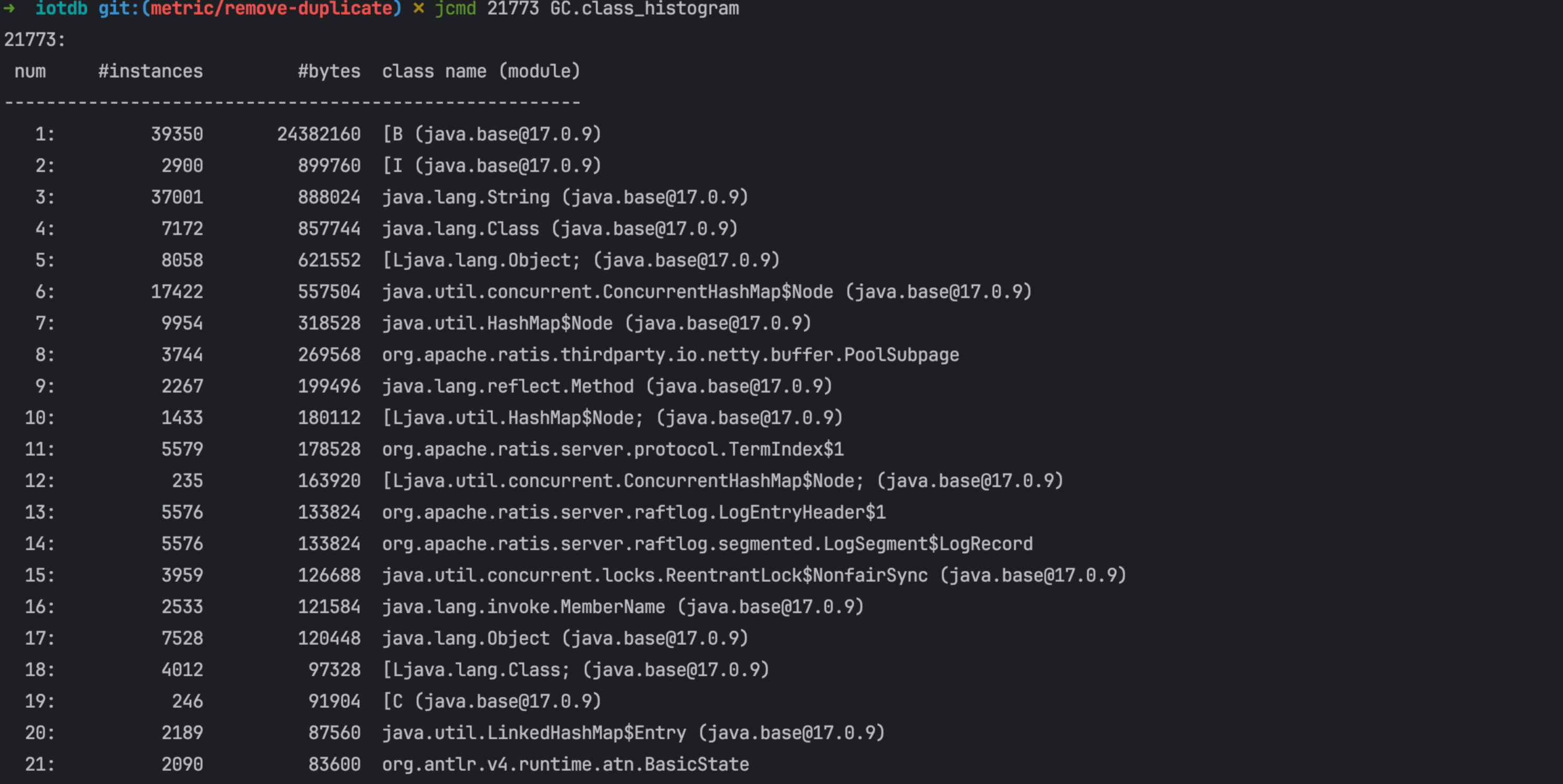
- 打印 native memory(非堆内存)信息,即使用 NMT,见下节。
- 优点:各种命令高低搭配,堆内非堆都能很好的监控到
- 缺点:非堆内存的详细监控需要开启 NMT,会带来性能损失且不支持热加载
Native Memory Tracking(NMT)
- 开启:使用
-XX:NativeMemoryTracking=``summary可以用于开启 NMT,其中该值默认为 off,可以设置为 summary 或者 detail 来开启;开启的话,大概会增加 5%-10% 的性能消耗 - 使用:使用
jcmd pid VM.native_memory可以查看,后面可以加 summary 或者 detail,如果是开启 summary 的,就只能使用 summary;其中 scale 参数可以指定展示的单位,可以为 KB 或者 MB 或者 GB
jcmd <pid> VM.native_memory [summary | detail | baseline | summary.diff | detail.diff | shutdown] [scale= KB | MB | GB] |
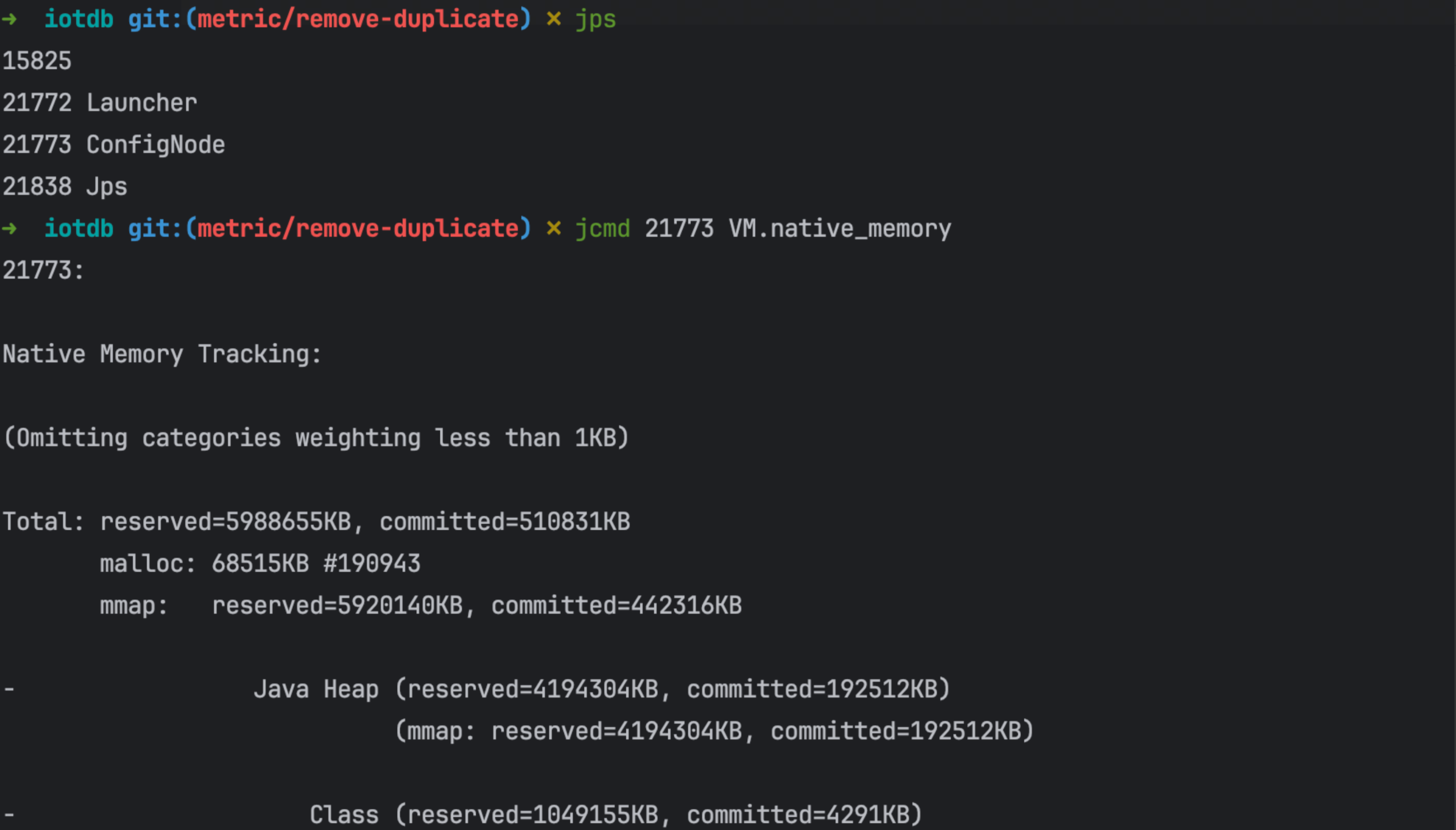
- 优点:非常全,各项都能很好的监控到;能监控到 memory map,拿到内存地址。
- 缺点:必须在 JVM 启动时添加参数开启,不支持热加载;有 5-10% 的性能损失
Verbose
在调试程序时,有时需要查看程序加载的类、内存回收情况、调用的本地接口等。这时候就需要 -verbose 命令。
- 直接在 VM 参数添加
- 也可以在命令行输入
java -verbose:xxx来查看
-verbose:class 查看类加载情况 |
作用:可以用来排查异常类加载情况、本地接口异常调用等(这些通常是内存泄漏、内存异常的凶手)
例:对 configNode 使用 -verbose:class:
系统工具(Linux)
对于 native 层面的内存分配和排查,Java 层面的工具已经不适合。此时需要 Linux 系统层面的工具进行排查。
以下提到的工具都可以结合起来使用。有一个真实案例,将下列工具组合运用,非常牛逼丝滑:
https://heapdump.cn/article/2640702
pmap
用法:pmap <选项> pid
- 快速检查占用较大的内存
pmap -x 1 | sort -nrk3 | less |
- 检查一段时间后新增了哪些内存段,或哪些变大了。在不同的时间点多次保存 pmap 命令的输出,然后通过文本对比工具查看两个时间点内存段分布的差异。
pmap -x 1 > pmap-`date +%F-%H-%M-%S`.log |
pmap 的输出如下:
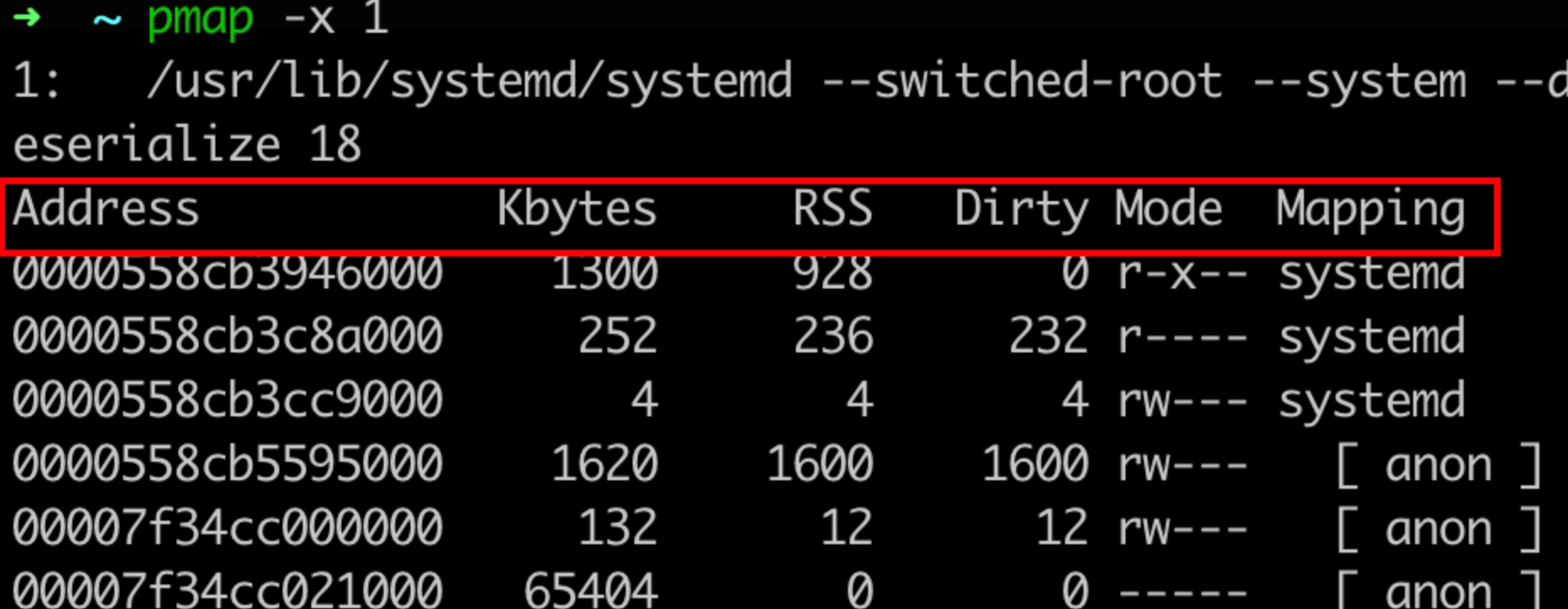
可以发现,进程申请的所有虚拟内存段,都在pmap中能够找到,相关字段解释如下:
- Address:表示此内存段的起始地址
- Kbytes:表示此内存段的大小(ps:这是虚拟内存)
- RSS:表示此内存段实际分配的物理内存,这是由于Linux是延迟分配内存的,进程调用malloc时Linux只是分配了一段虚拟内存块,直到进程实际读写此内存块中部分时,Linux会通过缺页中断真正分配物理内存。
- Dirty:此内存段中被修改过的内存大小,使用mmap系统调用申请虚拟内存时,可以关联到某个文件,也可不关联,当关联了文件的内存段被访问时,会自动读取此文件的数据到内存中,若此段某一页内存数据后被更改,即为Dirty,而对于非文件映射的匿名内存段(anon),此列与RSS相等。
- Mode:内存段是否可读(r)可写(w)可执行(x)
- Mapping:内存段映射的文件,匿名内存段显示为anon,非匿名内存段显示文件名(加-p可显示全路径)。
pmap 的作用通常是:查看内存分配情况,找出异常内存;根据内存地址,比对 strace 内存请求的具体申请额度;根据内存地址,比对 NMT 中的内存地址,找出异常内存。
gdb
作用1:已知异常内存地址的情况下,查看异常内存内容
gdp -pid pid进入GDB- 使用命令
dump memory mem.bin startAddress endAddressdump内存,其中 startAddress 和 endAddress 可以从 /proc/pid/**aps 中查找。 - 使用
strings mem.bin查看 dump 的内容。
作用2:检查被 glibc 内存*分配器缓存的内存
# 查看glibc内存分配情况,会输出到进程标准错误中 |
glibc 实现了 malloc_trim 函数,通过 brk 或 madvise 系统调用,归还被 glibc 缓存的内存,如下:
# 回收glibc缓存的内存 |
strace
向 os 追踪申请内存请求(系统调用),常见用法:
strace -f -e "brk,mmap,munmap" -p pid |
作用:查到异常申请内存请求的 pid*,从而通过 jstack 等分析工具,具体分析该 id 线程的调用栈等行为
缺点:必须在项目启动时 strace 才能达到比较好的追踪效果
【最佳实践】如何控制 Java 进程所占内存
堆内存
使用 JVM 参数控制
Xmx:对应 最大堆大小MaxHeapSizeXms:相当于同时设置最小堆*大小MinHeapSize和初始堆大小InitialHeapSize-XX:+AlwaysPreTouch:对于只运行 IoTDB 的机器,内存本来就都是给 IoTDB 用的,建议加上此参数,避免 Linux touch 内存的开销,让内存更稳定。
非堆内存
- 使用 JVM 参数控制
-Xss:每个线程 stack 的大小-XX:MaxDirectMemorySize:控制直接内存大小-XX:MaxMetaspaceSize:控制数据元信息区大小-XX:CompressedClassSpaceSize:控制类元信息区大小-XX:ReservedCodeCacheSize:Code cache 区最大内存-Djdk.nio.maxCachedBufferSize:限制每个线程缓存DirectByteBuffer的 size- 避免使用
-XX:+DisableExplicitGC:JVM 实现中:-XX:MaxMetaspaceSize的阈值检查依赖 System.gc()。禁用 System.gc() 会导致更容易 OOM。
- native 代码分配上妥善处理
- 主要指使用 Unsafe 类或者 NIO 相关类直接管理内存时,需要妥善做好内存的分配去配,防止内存泄漏
- 常见的实现是结合 try-with-resource,在 close 函数中释放内存,达到类似 C++ RAII 的效果
- 在合适的时机(close)调用
DirectByteBuffer.getCleaner().clean(),手动清理堆外内存,而不是交给 GC(finalize)
- 在合适的时机(close)调用
- 在堆外内存使用频繁的场合,不要擅自开启
-XX:+DisableExplicitGC开关进行“优化”。
- 常见的实现是结合 try-with-resource,在 close 函数中释放内存,达到类似 C++ RAII 的效果
- 冰山对象 GC
- 主要指 DirectByteBuffer
【总结】本调研旨在解决的问题
为什么设置-Xmx6g,但是 java 进程内存占用达到 8g?(数字随便举的)
镜像问题:为什么 MAX_DIRECT_MEMORY_SIZE + 堆内内存 比实际进程占用内存大?
- 因为有非堆内存,且非堆内存除了 Direct buffer 还包括 Code Cache,MetaSpace 等。
Java 进程内存占用 = 堆内存 + 非堆内存(DirectMemory + Metaspace + … )
- 由于 glibc 内存去配机制,Java 实际占用内存会比理论上大些
- 由于 glibc 内存分配机制,Java 实际分配到的物理内存会比真实使用的内存大些
非堆内存如何管理?
堆内存如何管理?
排查 Java 内存相关最佳实践
如何排查 Java 应用在线上到底占用了多少内存?
- 查看 IoTDB 占用的*物理内存
- top 等命令
- System 面板
- 查看 IoTDB 进程各模块占用内存
- 堆内存:jmap、jcmd、System 面板等
- 非堆内存:
- 推荐:NMT(查看绝大部分) + System 面板(查看 mapped memory)+ pmap(查看 native 内存)+ gdb(查看 glibc 缓存内存),以上组合拳可以覆盖本文提到的所有相关内存。
内存异常(OOM/RSS 远超预期等),如何定位哪部分内存是凶手?
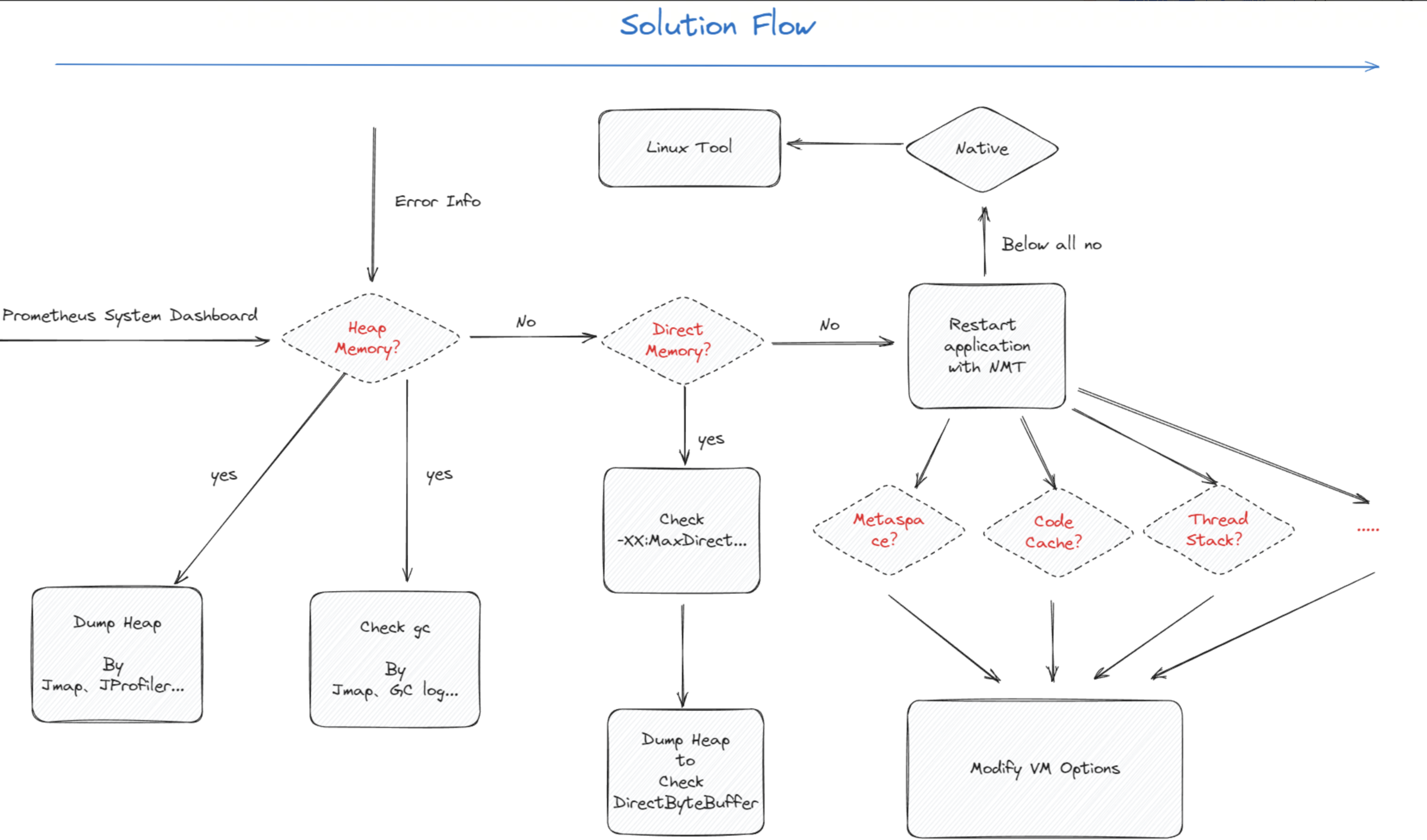
- 首先结合异常信息看 System 面板,定位是不是堆内存*的问题
- 如果是 OOM*:报错 OutOfMemoryError: Direct Buffer Memory:是 Direct Memory 泄漏,跳到第三步。OutOfMemoryError: GC limit、OutOfMemoryError: Heap size 等是堆内存泄漏,跳到第二步
- 如果是 Java 进程 RSS 远大于理论内存:一般不是堆内存的问题。根据经验,一般是:
- 某些自定义的 native 代码造成了内存泄漏,对应第四步。
DirectByteBuffer的问题,对应第三步。- 这些对象实例可能是由应用程序显示的创建(例如通过某些第三方库)
- 也可能是由 JDK 内部使用
HeapByteBuffer的 I/O 线程自动创建和缓存在 threadlocal 里,如果创造了很多通过这样的线程, 并且每个线程使用的 buffer 很大,那么最终 Java 进程可能占用大量的堆外内存,看起来就像发生了内存泄漏一样(参考组内大佬的这篇问题排查:2021-11-25 线上堆外内存泄漏问题排查 )
- 操作系统存在问题,对应第五步。
- 如果是操作系统的原因的话,那么在通过
pmap工具输出的日志中应该会存在众多大小为 64MB 的内存块分配,如果 64M 问题不是很显然,那么就需要检查自定义的本地代码(nmt 等手段)
- 如果是操作系统的原因的话,那么在通过
- System 面板看各 memory 是否符合预期,可以定位是否为堆内存的问题。
- 如果是堆内存的问题
- 使用 jmap、jprofiler 等手段 dump 内存,进一步查看到底是哪些对象积压
- 使用 jmap、GC log 等手段查看 gc 情况,看看是不是 full gc 不及时等问题。如是,需要调整 GC 的相关 VM options
- 如果是 DirectMemory
- 查看 MaxDirectMemorySize 是不是设置妥当
- 如 MaxDirectMemorySize 设好了,查看 heap 中 DirectByteBuffer 对象的积压/创建情况,可以通过 dump heap、verbose 等手段实现。有可能是 DirectByteBuffer 没有被及时 clean 导致 DirectMemory 增大
- 如果不是 heap 也不是 DirectMemory
- 建议加上 nmt,复现 OOM 场景,进一步查看到底是哪块区域内存异常
- Metaspace、code cache 等,如果它们异常了,重新设置对应的 VM options 即可
- 建议加上 nmt,复现 OOM 场景,进一步查看到底是哪块区域内存异常
- 如果 nmt 各项都正常
- 可能是 native 或者 glibc 等 JVM 不能控制的部分在搞鬼,这时候需要使用 linux 的工具了
- 先 pmap,查看是不是 glibc 64M 内存的问题。
- 一般来说,64M 问题不会导致 OOM 这么严重的 exception,只会让 Java 进程超额申请它所需要的内存。也就是说,64M 可能只是压死骆驼的最后一根稻草,但并不是 OOM 真正的罪魁祸首。如果想解决 64M 问题的话,可以参考前文的解决方案
pmap -x 1 | sort -nrk3 | less,依次排查较大的内存块。- 尝试用 gdb 等工具 dump 这些内存,看看里面是什么内容,往往能找到异常类的信息
- 结合 strace 等工具深度跟踪内存分配轨迹,揪出凶手
- 最后查看 glibc 内存分配情况,
gdb -q -batch -ex 'call malloc_stats()' -p pid,看看是不是 glibc 缓存未归还操作系统的问题。- 如是,调用
gdb -q -batch -ex 'call malloc_trim(0)' -p pid归还 glibc 的缓存- malloc_trim 有概率会导致 JVM Crash,使用的时候需要小心
- 可以参考 https://zhuanlan.zhihu.com/p/652545321
- 如是,调用
Ref
- http://lovestblog.cn/blog/2016/08/29/oom/
- http://lovestblog.cn/blog/2016/10/29/metaspace/
- http://lovestblog.cn/blog/2016/06/29/ooc-offheap/
- http://lovestblog.cn/blog/2015/05/12/direct-buffer/
- https://cloud.tencent.com/developer/article/1666640
- https://cloud.tencent.com/developer/article/1408384
- https://cloud.tencent.com/developer/article/2315755
- https://cloud.tencent.com/developer/article/2277333?areaId=106001
- https://juejin.cn/post/7225875600644407357
- https://juejin.cn/post/7225874698906615864
- https://juejin.cn/post/7225879698952486972
- https://juejin.cn/post/6844904168549777421
- https://juejin.cn/post/7067170332917923854
- https://juejin.cn/post/6854573220733911048
- https://juejin.cn/post/7078624931826794503
- https://juejin.cn/post/7176056215074504762
- https://zhuanlan.zhihu.com/p/342770702
- https://zhuanlan.zhihu.com/p/652545321
- https://zhuanlan.zhihu.com/p/428216764
- https://zhuanlan.zhihu.com/p/432258798
- https://www.zhihu.com/question/55529827
- https://www.zhihu.com/question/58943470
- https://heapdump.cn/article/2906673
- https://heapdump.cn/article/2614172
- https://heapdump.cn/article/2640702
- https://blog.csdn.net/pingnanlee/article/details/51984058
- https://blog.csdn.net/renfufei/article/details/115165919
- https://learn.skyofit.com/archives/478
- https://sploitfun.wordpress.com/2015/02/10/understanding-glibc-malloc/
- https://haslab.org/2020/12/06/hawkeye.html
- https://dzone.com/articles/troubleshooting-problems-with-native-off-heap-memo
- https://paper.seebug.org/papers/Archive/refs/heap/glibc%E5%86%85%E5%AD%98%E7%AE%A1%E7%90%86ptmalloc%E6%BA%90%E4%BB%A3%E7%A0%81%E5%88%86%E6%9E%90.pdf
- https://stackoverflow.com/questions/31173374/why-does-a-jvm-report-more-committed-memory-than-the-linux-process-resident-set
- https://stackoverflow.com/questions/41468670/difference-in-used-committed-and-max-heap-memory
- https://stackoverflow.com/questions/2440434/whats-the-difference-between-reserved-and-committed-memory
- https://stackoverflow.com/questions/71366522/how-does-java-guarateee-reserved-memory
- https://www.oracle.com/java/technologies/javase/vmoptions-jsp.html
- https://docs.oracle.com/javase/8/docs/technotes/tools/windows/java.html
- https://docs.oracle.com/en/java/javase/17/docs/specs/man/java.html
- https://docs.oracle.com/javase/8/docs/technotes/tools/unix/java.html