Oct 15, 2022
CMU 15-445: 6. Query Execution
6. Query Execution
- how to execute queries using table heaps and indexes.
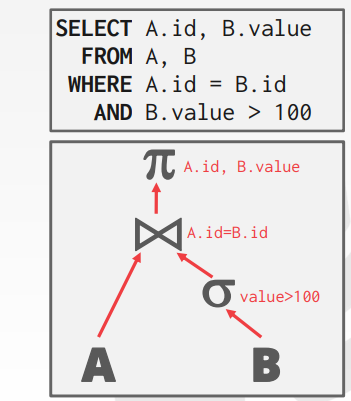
6.1. Query
- Query operators are arranged in a tree.
- 数据从底层向根节点流动
- 根节点的输出为 query 的输出
6.2. Sorting
- 我们在 query 时,时常需要 retrieve tuples in a specific order
- 但是 data 通常 not fit in memory(有时需要向磁盘 IO)。我们需要用一种能考虑到 IO 开销的技术
- 需要排序算法的原因:本质在于 tuples 在 table 中没有顺序,无论是用户还是 DBMS 本身,在处理某些任务时希望 tuples 能够按一定的顺序排列,如:
- 若 tuples 已经排好序,去重操作将变得很容易(DISTINCT)
- 批量将排好序的 tuples 插入到 B+ Tree index 中,速度更快
- Aggregations (GROUP BY)
6.2.1. External Merge Sort
思想是分治,就是把大数据分成独立的 *runs* 再分别 sort 它们。它们可以写回到硬盘,也可以读出来。这个算法包含两步: Phase #1 - Sorting: 首先算法会 sort 可以放在内存的小 chunk,然后写回到硬盘中。 Phase #2 - Merge: 然后合并这些子文件到一个大的单独文件中。
- Divide-and-conquer sorting(分治排序)
- 先排序:将数据分为多个 chunk,每个 chunk 可以 fit in main-memory,然后将它们排序,再将排好序的 data 写回 disk
- 再合并:将排好的 data 合并成一个 larger file
- 复杂度:见 ppt
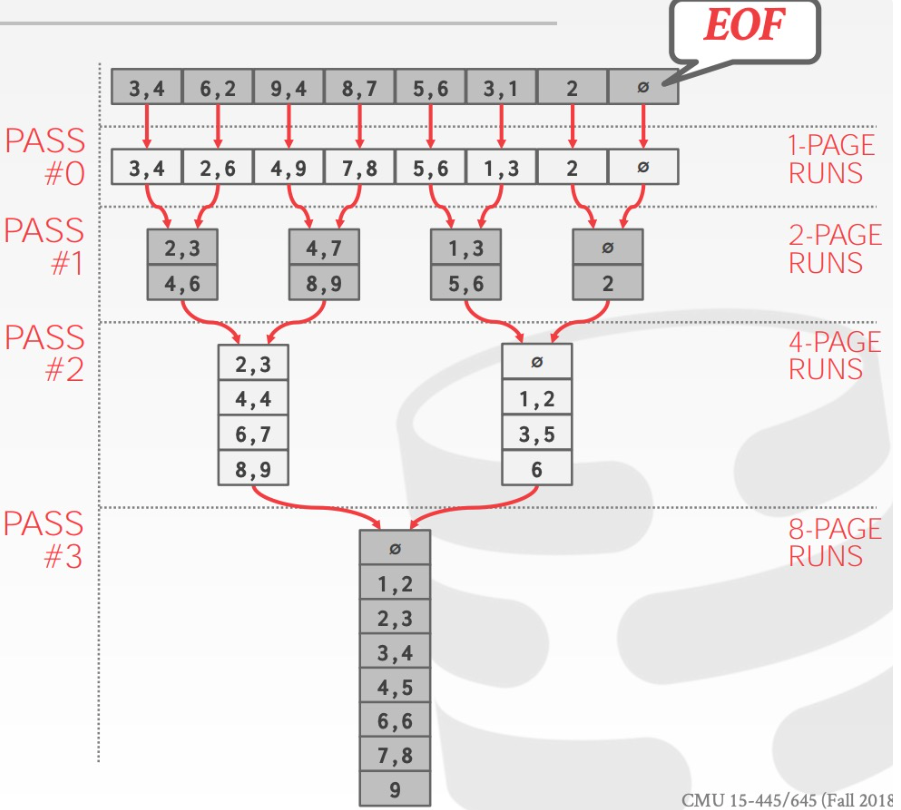
6.2.1.1. 2-Way External Merge Sort
“2” represents the number of runs that we are going to merge into a new run for each pass.
假设:
- Files 本分成 N 个 pages
- DBMS 有 B 个 fixed-size buffers
Pass #0
- 从 table 中读入 B pages tuples
- 将这些 tuples 排序后写回到 disk 中
- 每一轮成为一个 run
Pass #1,2,3,…
递归地将一对 runs 合并成一个两倍长度的 run
这一操作值需要 3 个 buffer pages ( 2 个用于输入,1 个用于输出)
6.2.1.1.2. 双重 buffering 优化
- 当系统在处理当前 run 的时候,提前将下一次 run 取进第二个 buffer。
- 通过充分利用 disk,减少等待 IO 的时间。
6.2.1.2. General External Merge Sort
- 就是把 2-way 泛化成 N-way,充分利用磁盘空间
6.2.2. Using B+ Tree
- 如果需要排序的属性已经有了 B+树索引,我们可以用 B+树来加速排序
6.3. Aggregation
aggregation 就是对一组 tuples 的某些值做统计,转化成一个标量,如平均值、最大值、最小值等,aggregation 的实现通常有两种方案:
- Sorting
